DRAG DROP
Refer to the exhibit.
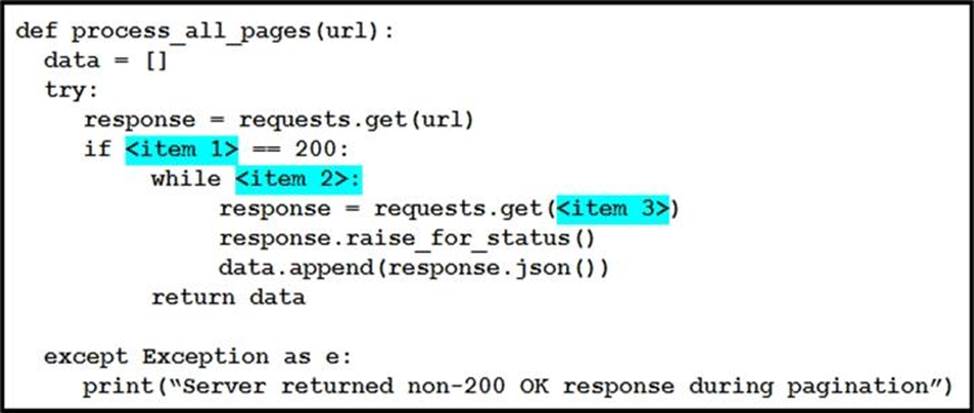
Drag and drop the parts of the Python code from the left onto the item numbers on the right that match the missing sections in the exhibit that consumes REST API pagination.
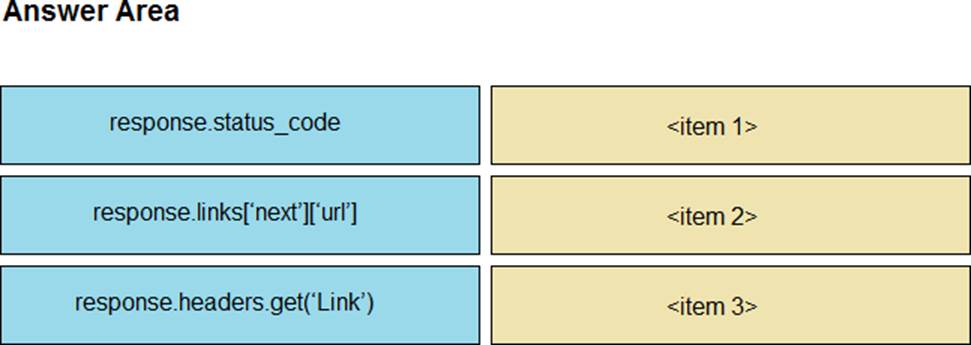
Answer: 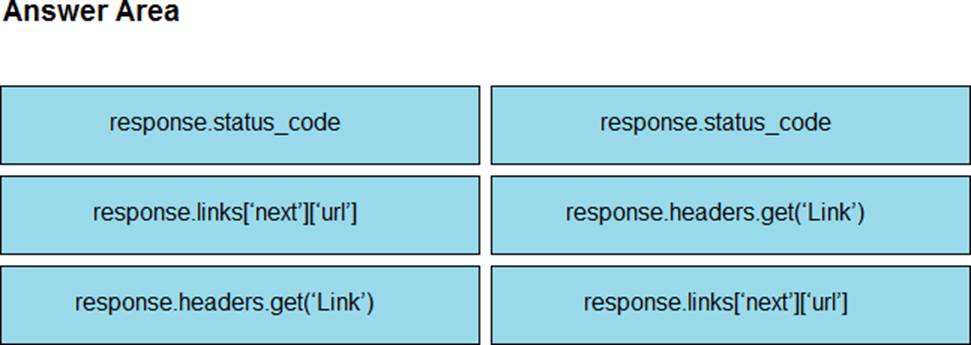
Explanation:
The correct URL from next page can be retrieved by using response.links[‘next’][‘url’]. The use of response.headers.get(‘Link’) could be easily replaced by an infinite loop like ‘while True:’ and it would be the same. They’re just testing our knowledge here. The trick here is that once we reach the last page, response.links[‘next’][‘url’] within the ‘try’ context will fail and we’ll move to the ‘except’ clause and the program will exit.
Latest 350-901 Dumps Valid Version with 169 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
