You ran the below query and it took a long time to run
select itembarcode from checkouts where BIBNUMBER = ‘2213435’;
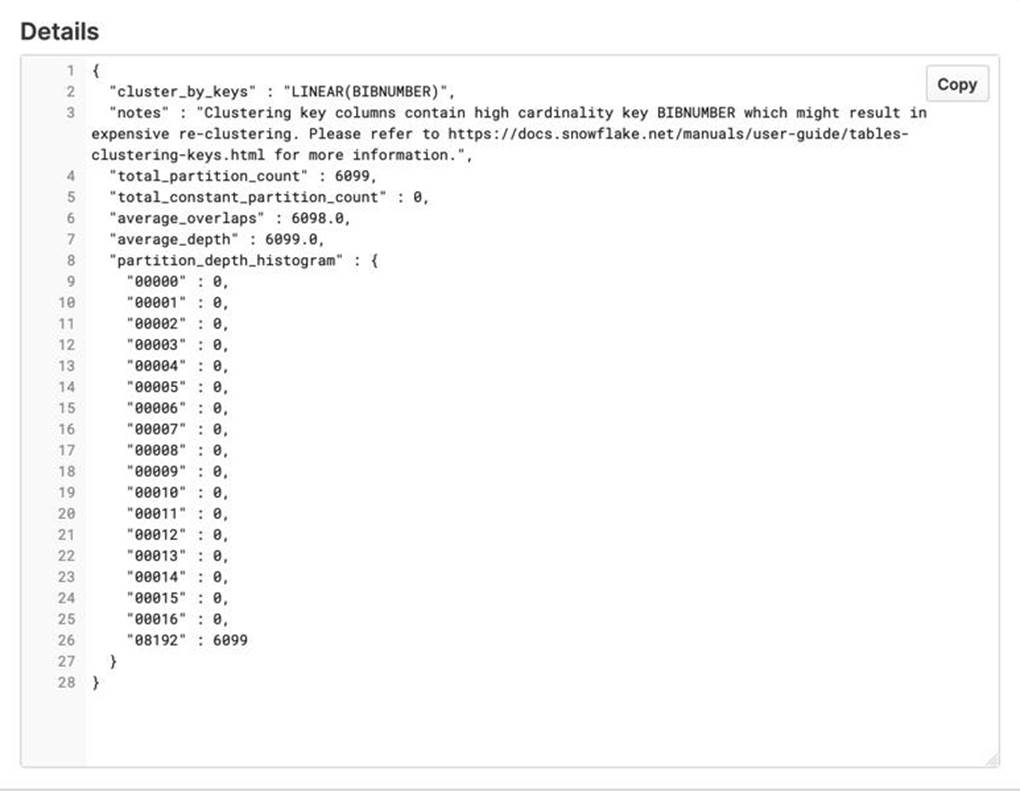
The clustering information shows the below result.
What can you derive from this information
select system$clustering_information(‘checkouts’,'(BIBNUMBER)’);
A . The data is not clustered well by BIBNUMBER and it is spread across all the micro-partitions, hence to retrieve a small number of micro-partitions, the query has to scan all the partitions in the table
B. The query is running slow because the warehouse does not have enough memory
C. The query is running slow because BIBNUMBER does not have an index created on it.
Answer: A
Explanation:
This is a question that requires good understanding of how the data is stored in snowflake. Snowflake stores data in columnar format in micro-partitions. In general, Snowflake produces well-clustered data in tables; however, over time, particularly as DML occurs on very large tables (as defined by the amount of data in the table, not the number of rows), the data in some table rows might no longer cluster optimally on desired dimensions. Here also the same thing has happened. The data is not longer clustered well on BIBNUMBER.
There are Zero (0) constant micro-partitions out of 6099 total micro-partitions.
High average of overlapping micro-partitions.
High average of overlap depth across micro-partitions.
All the micro-partitions are grouped at the lower-end of the histogram. It tells us that there are 6099 micro-partitions which has BIBNUMBER that is also available in micropartitions between 64 and 8192. In this case, therefore the BIBNUMBER is all over the micro-partitions.
Latest ARA-C01 Practice Questions with 156 Q&As
Updated Study Material | Instant Download | Detailed Answers and Explanations