Create a task and a stream following the below steps. So, when the
system$stream_has_data(‘rawstream1’) condition returns false, what will happen to the task ?
— Create a landing table to store raw JSON data.
— Snowpipe could load data into this table. create or replace table raw (var variant);
— Create a stream to capture inserts to the landing table.
— A task will consume a set of columns from this stream. create or replace stream rawstream1 on table raw;
— Create a second stream to capture inserts to the landing table.
— A second task will consume another set of columns from this stream. create or replace stream rawstream2 on table raw;
— Create a table that stores the names of office visitors identified in the raw data. create or replace table names (id int, first_name string, last_name string);
— Create a table that stores the visitation dates of office visitors identified in the raw data.
create or replace table visits (id int, dt date);
— Create a task that inserts new name records from the rawstream1 stream into the names table
— every minute when the stream contains records.
— Replace the ‘etl_wh’ warehouse with a warehouse that your role has USAGE privilege on. create or replace task raw_to_names
warehouse = etl_wh schedule = ‘1 minute’ when
system$stream_has_data(‘rawstream1’) as
merge into names n
using (select var:id id, var:fname fname, var:lname lname from rawstream1) r1 on n.id = to_number(r1.id)
when matched then update set n.first_name = r1.fname, n.last_name = r1.lname
when not matched then insert (id, first_name, last_name) values (r1.id, r1.fname, r1.lname)
;
— Create another task that merges visitation records from the rawstream1 stream into the visits table
— every minute when the stream contains records.
— Records with new IDs are inserted into the visits table;
— Records with IDs that exist in the visits table update the DT column in the table.
— Replace the ‘etl_wh’ warehouse with a warehouse that your role has USAGE privilege on. create or replace task raw_to_visits
warehouse = etl_wh schedule = ‘1 minute’ when
system$stream_has_data(‘rawstream2’) as
merge into visits v
using (select var:id id, var:visit_dt visit_dt from rawstream2) r2 on v.id = to_number(r2.id) when matched then update set v.dt = r2.visit_dt
when not matched then insert (id, dt) values (r2.id, r2.visit_dt)
;
— Resume both tasks.
alter task raw_to_names resume;
alter task raw_to_visits resume;
— Insert a set of records into the landing table. insert into raw
select parse_json(column1) from values
(‘{"id": "123","fname": "Jane","lname": "Smith","visit_dt": "2019-09-17"}’),
(‘{"id": "456","fname": "Peter","lname": "Williams","visit_dt": "2019-09-17"}’);
— Query the change data capture record in the table streams select * from rawstream1;
select * from rawstream2;
A . Task will be executed but no rows will be merged
B. Task will return an warning message
C. Task will be skipped
Answer: C
Explanation:
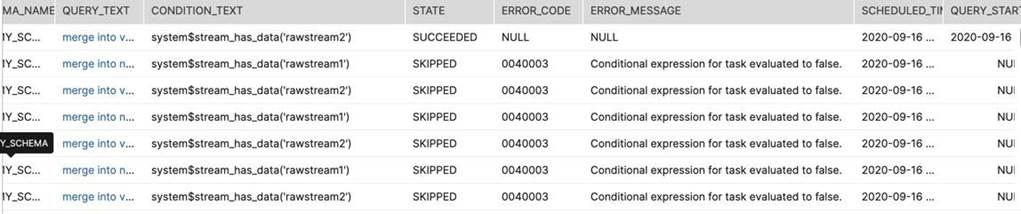
I would like you to complete the above steps and then run the below query to see it yourself. This way
you will never forget this:)
select *
from table(information_schema.task_history())
order by scheduled_time;
Do you see that the task has been skipped?
Latest ARA-C01 Practice Questions with 156 Q&As
Updated Study Material | Instant Download | Detailed Answers and Explanations