DRAG DROP
You have data stored in thousands of CSV files in Azure Data Lake Storage Gen2. Each file has a header row followed by a property formatted carriage return (/r) and line feed (/n).
You are implementing a pattern that batch loads the files daily into an an enterprise data warehouse in Azure Synapse Analytics by using PolyBase.
You need to skip the header row when you import the files into the data warehouse.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer: 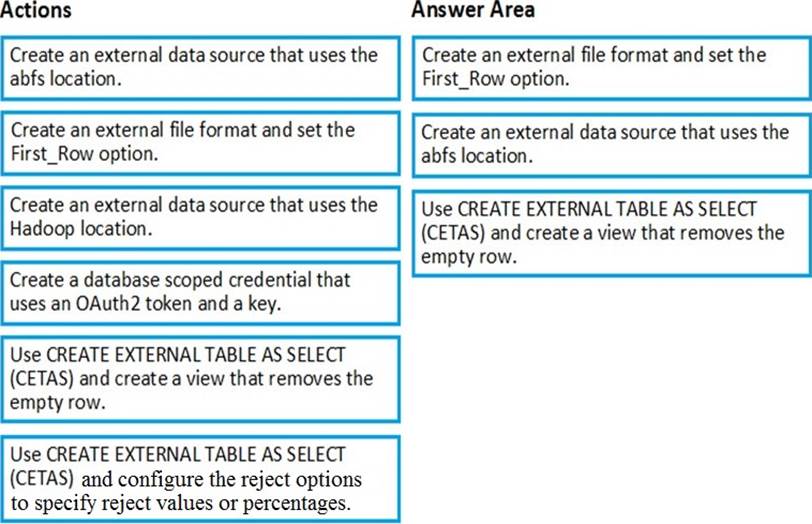
Explanation:
Step 1: Create an external data source and set the First_Row option.
Creates an External File Format object defining external data stored in Hadoop, Azure Blob Storage, or Azure Data Lake Store. Creating an external file format is a prerequisite for creating an External Table.
FIRST_ROW = First_row_int
Specifies the row number that is read first in all files during a PolyBase load. This parameter can take values 1-15. If the value is set to two, the first row in every file (header row) is skipped when the data is loaded. Rows are skipped based on the existence of row terminators (/r/n, /r, /n).
Step 2: Create an external data source that uses the abfs location
The hadoop-azure module provides support for the Azure Data Lake Storage Gen2 storage layer through the “abfs” connector
Step 3: Use CREATE EXTERNAL TABLE AS SELECT (CETAS) and create a view that removes the empty row.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-external-file-format-transact-sql https://hadoop.apache.org/docs/r3.2.0/hadoop-azure/abfs.html
Latest DP-200 Dumps Valid Version with 242 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
