HOTSPOT
You are building an Azure Stream Analytics job that queries reference data from a product catalog file. The file is updated daily.
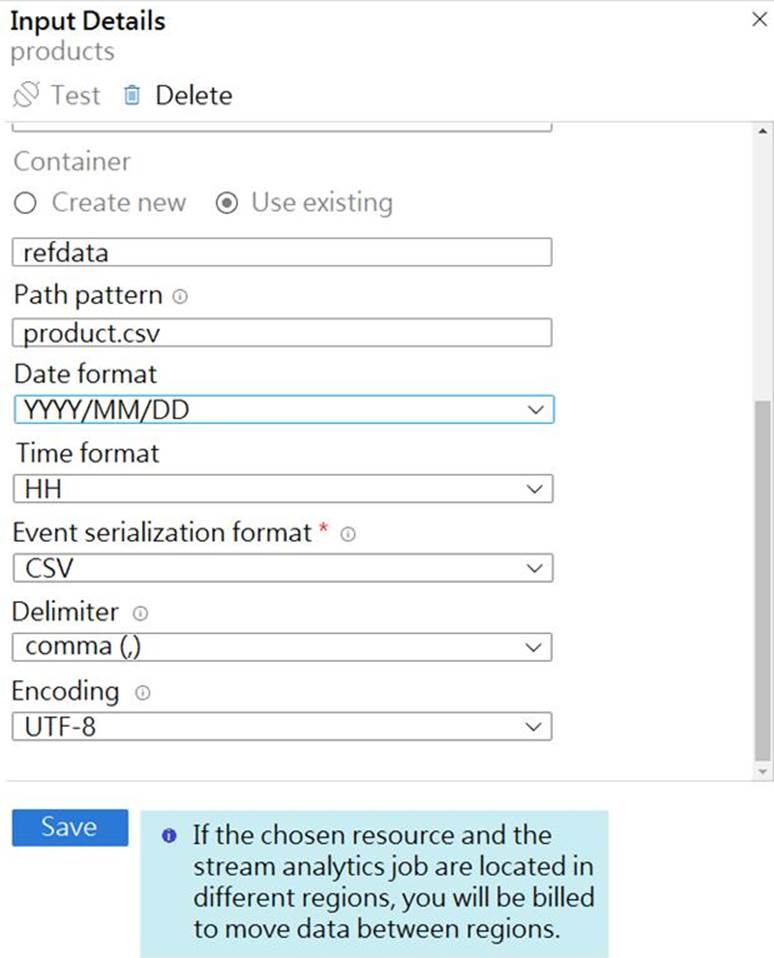
The reference data input details for the file are shown in the Input exhibit.
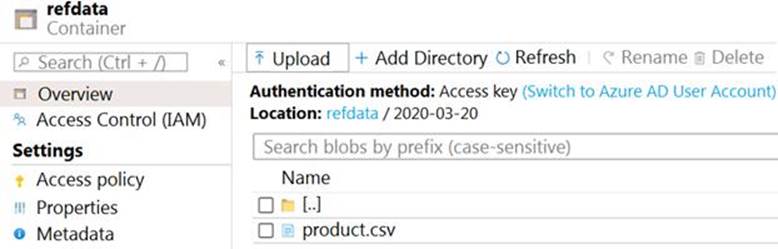
The storage account container view is shown in the Refdata exhibit.
You need to configure the Stream Analytics job to pick up the new reference data.
What should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
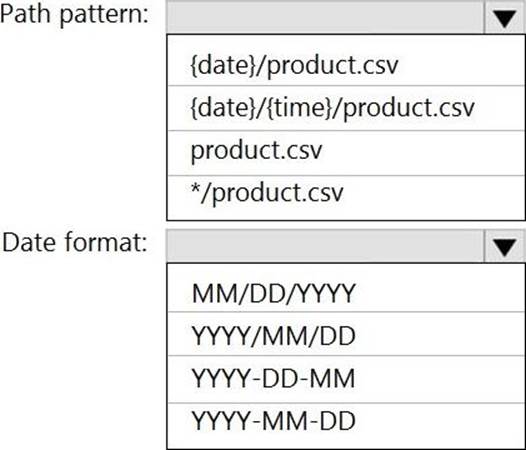
Answer: 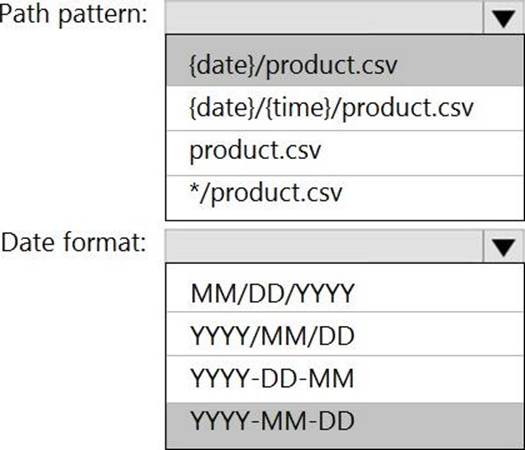
Explanation:
Table
Description automatically generated
Box 1: {date}/product.csv
In the 2nd exhibit we see: Location: refdata / 2020-03-20
Note: Path Pattern: This is a required property that is used to locate your blobs within the specified container. Within the path, you may choose to specify one or more instances of the following 2 variables:
{date}, {time}
Example 1: products/{date}/{time}/product-list.csv
Example 2: products/{date}/product-list.csv
Example 3: product-list.csv
Box 2: YYYY-MM-DD
Note: Date Format [optional]: If you have used {date} within the Path Pattern that you specified, then you can select the date format in which your blobs are organized from the drop-down of supported formats.
Example: YYYY/MM/DD, MM/DD/YYYY, etc.
Latest DP-200 Dumps Valid Version with 242 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
