HOTSPOT
You plan to develop a dataset named Purchases by using Azure databricks Purchases will contain the following columns:
• ProductID
• ItemPrice
• lineTotal
• Quantity
• StorelD
• Minute
• Month
• Hour
• Year
• Day
You need to store the data to support hourly incremental load pipelines that will vary for each StoreID. the solution must minimize storage costs .
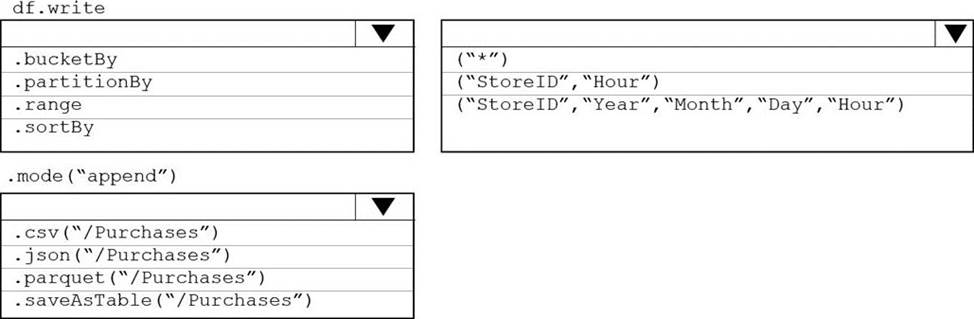
How should you complete the rode? To answer, select the appropriate options In the answer area. NOTE: Each correct selection is worth one point.
Answer: 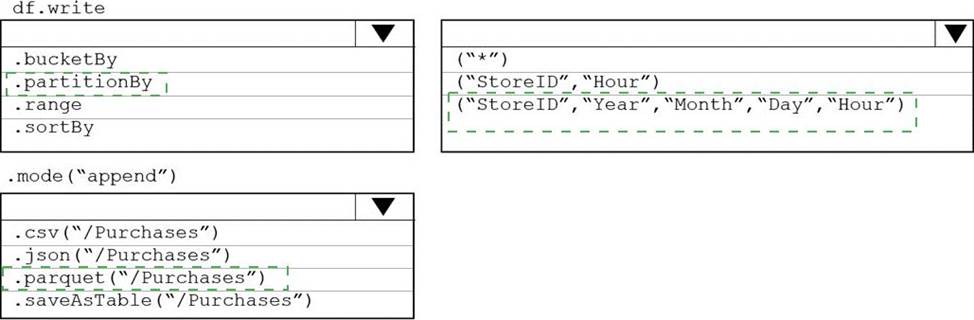
Explanation:
Box 1: partitionBy
We should overwrite at the partition level.
Example:
df.write.partitionBy("y","m","d")
mode(SaveMode.Append)
parquet("/data/hive/warehouse/db_name.db/" + tableName)
Box 2: ("StoreID", "Year", "Month", "Day", "Hour", "StoreID")
Box 3: parquet("/Purchases")
Latest DP-203 Practice Questions with 116 Q&As
Updated Study Material | Instant Download | Detailed Answers and Explanations