A Machine Learning Specialist has built a model using Amazon SageMaker built-in algorithms and is not getting expected accurate results The Specialist wants to use hyperparameter optimization to increase the model’s accuracy
Which method is the MOST repeatable and requires the LEAST amount of effort to achieve this?
A . Launch multiple training jobs in parallel with different hyperparameters
B . Create an AWS Step Functions workflow that monitors the accuracy in Amazon CloudWatch Logs
and relaunches the training job with a defined list of hyperparameters
C . Create a hyperparameter tuning job and set the accuracy as an objective metric.
D . Create a random walk in the parameter space to iterate through a range of values that should be used for each individual hyperparameter
Answer: C
Explanation:
A hyperparameter tuning job is a feature of Amazon SageMaker that allows automatically finding the best combination of hyperparameters for a machine learning model. Hyperparameters are high-level parameters that influence the learning process and the performance of the model, such as the learning rate, the number of layers, the regularization factor, etc. A hyperparameter tuning job works by launching multiple training jobs with different hyperparameters, evaluating the results using an objective metric, and choosing the next set of hyperparameters to try based on a search strategy. The objective metric is a measure of the quality of the model, such as accuracy, precision, recall, etc. The search strategy is a method of exploring the hyperparameter space, such as random search, grid search, or Bayesian optimization.
Among the four options, option C is the most repeatable and requires the least amount of effort to use hyperparameter optimization to increase the model’s accuracy. This option involves the following steps:
Create a hyperparameter tuning job: Amazon SageMaker provides an easy-to-use interface for creating a hyperparameter tuning job, either through the AWS Management Console, the AWS CLI, or the AWS SDKs. To create a hyperparameter tuning job, the Machine Learning Specialist needs to specify the following information:
The name and type of the algorithm to use, either a built-in algorithm or a custom algorithm. The ranges and types of the hyperparameters to tune, such as categorical, continuous, or integer. The name and type of the objective metric to optimize, such as accuracy, and whether to maximize or minimize it.
The resource limits for the tuning job, such as the maximum number of training jobs and the maximum parallel training jobs.
The input data channels and the output data location for the training jobs.
The configuration of the training instances, such as the instance type, the instance count, the volume size, etc.
Set the accuracy as an objective metric: To use accuracy as an objective metric, the Machine Learning Specialist needs to ensure that the training algorithm writes the accuracy value to a file
called metric_definitions in JSON format and prints it to stdout or stderr. For example, the file can contain the following content:
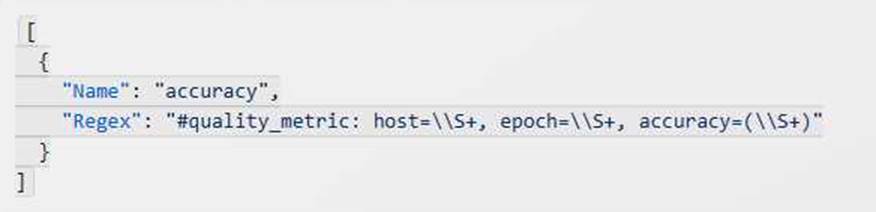
This means that the training algorithm prints a line like this:
![]()
Amazon SageMaker reads the accuracy value from the line and uses it to evaluate and compare the training jobs.
The other options are not as repeatable and require more effort than option C for the following reasons:
Option A: This option requires manually launching multiple training jobs in parallel with different hyperparameters, which can be tedious and error-prone. It also requires manually monitoring and comparing the results of the training jobs, which can be time-consuming and subjective.
Option B: This option requires writing code to create an AWS Step Functions workflow that monitors the accuracy in Amazon CloudWatch Logs and relaunches the training job with a defined list of hyperparameters, which can be complex and challenging. It also requires maintaining and updating the list of hyperparameters, which can be inefficient and suboptimal.
Option D: This option requires writing code to create a random walk in the parameter space to
iterate through a range of values that should be used for each individual hyperparameter, which can
be unreliable and unpredictable. It also requires defining and implementing a stopping criterion,
which can be arbitrary and inconsistent.
Reference: Automatic Model Tuning – Amazon SageMaker
Define Metrics to Monitor Model Performance
Latest MLS-C01 Dumps Valid Version with 104 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
