HOTSPOT
You have an Apache Spark pool in Azure Synapse Analytics that runs the following Python code in a notebook.

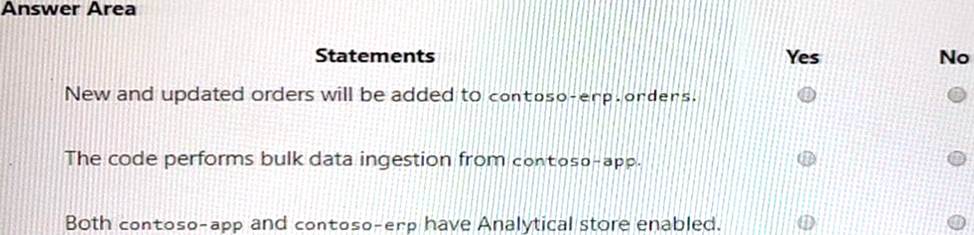
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Answer: 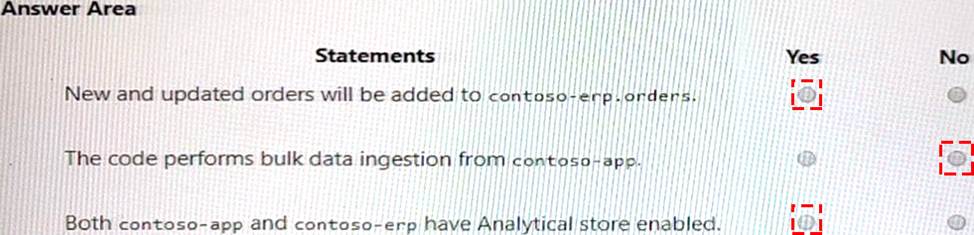
Explanation:
New and updated orders will be added to contoso-erp.orders: Yes
The code performs bulk data ingestion from contoso-app: No
Both contoso-app and contoso-erp have Analytics store enabled: Yes
The code uses the spark.readStream method to read data from a container named orders in a database named contoso-app. The data is then filtered by a condition and written to another container named orders in a database named contoso-erp using the spark.writeStream method. The write mode is set to “append”, which means that new and updated orders will be added to the destination container1.
The code does not perform bulk data ingestion from contoso-app, but rather stream processing. Bulk data ingestion is a process of loading large amounts of data into a data store in batches. Stream processing is a process of continuously processing data as it arrives in real-time2.
Both contoso-app and contoso-erp have Analytics store enabled, because they are both accessed by Spark pools using the spark.cosmos.oltp method. This method requires that the containers have Analytics store enabled, which is a feature that allows Spark pools to query data stored in Azure Cosmos DB containers using SQL APIs3.
Latest DP-420 Practice Questions with 51 Q&As
Updated Study Material | Instant Download | Detailed Answers and Explanations