HOTSPOT
You are designing a data processing solution that will run as a Spark job on an HDInsight cluster. The solution will be used to provide near real-time information about online ordering for a retailer.
The solution must include a page on the company intranet that displays summary information.
The summary information page must meet the following requirements:
– Display a summary of sales to date grouped by product categories, price range, and review scope.
– Display sales summary information including total sales, sales as compared to one day ago and sales as compared to one year ago.
– Reflect information for new orders as quickly as possible.
You need to recommend a design for the solution.
What should you recommend? To answer, select the appropriate configuration in the answer area.
Answer: 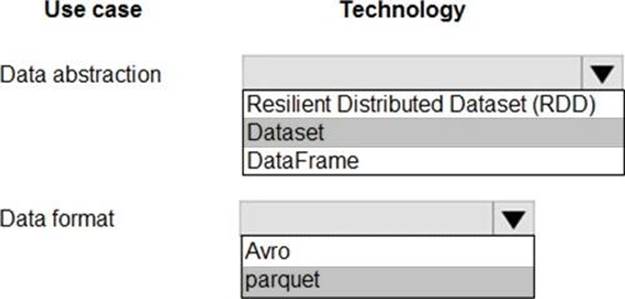
Explanation:
Box 1: DataFrame
DataFrames
Best choice in most situations.
Provides query optimization through Catalyst.
Whole-stage code generation.
Direct memory access.
Low garbage collection (GC) overhead.
Not as developer-friendly as DataSets, as there are no compile-time checks or domain object programming.
Box 2: parquet
The best format for performance is parquet with snappy compression, which is the default in Spark 2.x. Parquet stores data in columnar format, and is highly optimized in Spark.
Incorrect Answers:
DataSets
Good in complex ETL pipelines where the performance impact is acceptable.
Not good in aggregations where the performance impact can be considerable.
RDDs
You do not need to use RDDs, unless you need to build a new custom RDD.
No query optimization through Catalyst.
No whole-stage code generation.
High GC overhead.
References: https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-perf
Latest DP-201 Dumps Valid Version with 208 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
