HOTSPOT
You plan to develop a dataset named Purchases by using Azure Databricks.
Purchases will contain the following columns:
✑ ProductID
✑ ItemPrice
✑ LineTotal
✑ Quantity
✑ StoreID
✑ Minute
✑ Month
✑ Hour
✑ Year
✑ Day
You need to store the data to support hourly incremental load pipelines that will vary for each StoreID. The solution must minimize storage costs.
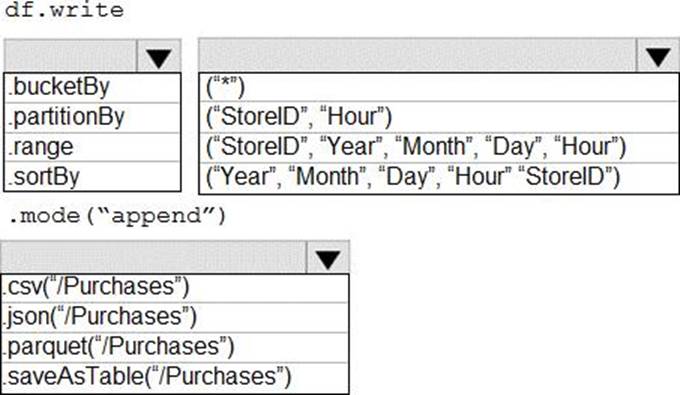
How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Answer: 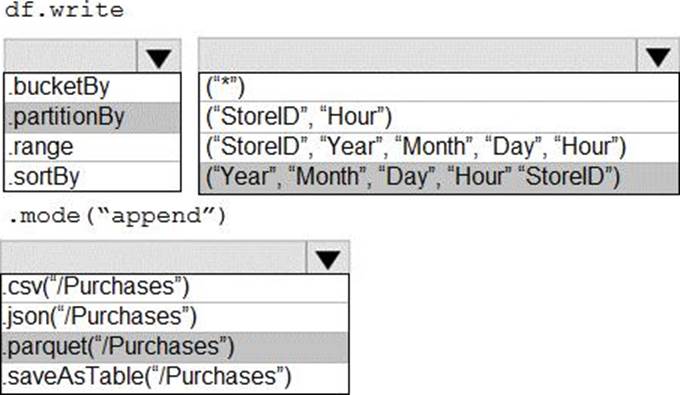
Explanation:
Box 1: .partitionBy
Example:
df.write.partitionBy("y","m","d")
mode(SaveMode.Append)
parquet("/data/hive/warehouse/db_name.db/" + tableName)
Box 2: ("Year","Month","Day","Hour","StoreID")
Box 3: .parquet("/Purchases")
Reference: https://intellipaat.com/community/11744/how-to-partition-and-write-dataframe-in-spark-without-deleting-partitions-with-no-new-data
Latest DP-300 Practice Questions with 176 Q&As
Updated Study Material | Instant Download | Detailed Answers and Explanations