What built-in Snowflake features make use of the change tracking metadata for a table? (Choose two.)
- A . The MERGE command
- B . The UPSERT command
- C . The CHANGES clause
- D . A STREAM object
- E . The CHANGE_DATA_CAPTURE command
C, D
Explanation:
The built-in Snowflake features that make use of the change tracking metadata for a table are the CHANGES clause and a STREAM object. The CHANGES clause enables querying the change tracking metadata for a table or view within a specified interval of time without having to create a stream with an explicit transactional offset1. A STREAM object records data manipulation language (DML) changes made to tables, including inserts, updates, and deletes, as well as metadata about each change, so that actions can be taken using the changed data. This process is referred to as change data capture (CDC)2. The other options are incorrect because they do not make use of the change tracking metadata for a table. The MERGE command performs insert, update, or delete operations on a target table based on the results of a join with a source table3. The UPSERT command is not a valid Snowflake command. The CHANGE_DATA_CAPTURE command is not a valid Snowflake command.
Reference: CHANGES | Snowflake Documentation, Change Tracking Using Table Streams | Snowflake Documentation, MERGE | Snowflake Documentation
When using the Snowflake Connector for Kafka, what data formats are supported for the messages? (Choose two.)
- A . CSV
- B . XML
- C . Avro
- D . JSON
- E . Parquet
C, D
Explanation:
The data formats that are supported for the messages when using the Snowflake Connector for Kafka are Avro and JSON. These are the two formats that the connector can parse and convert into Snowflake table rows. The connector supports both schemaless and schematized JSON, as well as Avro with or without a schema registry1. The other options are incorrect because they are not supported data formats for the messages. CSV, XML, and Parquet are not formats that the connector can parse and convert into Snowflake table rows. If the messages are in these formats, the connector will load them as VARIANT data type and store them as raw strings in the table2.
Reference: Snowflake Connector for Kafka | Snowflake Documentation, Loading Protobuf Data using the Snowflake Connector for Kafka | Snowflake Documentation
At which object type level can the APPLY MASKING POLICY, APPLY ROW ACCESS POLICY and APPLY SESSION POLICY privileges be granted?
- A . Global
- B . Database
- C . Schema
- D . Table
A
Explanation:
The object type level at which the APPLY MASKING POLICY, APPLY ROW ACCESS POLICY and APPLY SESSION POLICY privileges can be granted is global. These are account-level privileges that control who can apply or unset these policies on objects such as columns, tables, views, accounts, or users. These privileges are granted to the ACCOUNTADMIN role by default, and can be granted to other roles as needed. The other options are incorrect because they are not the object type level at which these privileges can be granted. Database, schema, and table are lower-level object types that do not support these privileges.
Reference: Access Control Privileges | Snowflake Documentation, Using Dynamic Data Masking | Snowflake Documentation, Using Row Access Policies | Snowflake Documentation, Using Session Policies | Snowflake Documentation
An Architect uses COPY INTO with the ON_ERROR=SKIP_FILE option to bulk load CSV files into a table called TABLEA, using its table stage. One file named file5.csv fails to load. The Architect fixes the file and re-loads it to the stage with the exact same file name it had previously.
Which commands should the Architect use to load only file5.csv file from the stage? (Choose two.)
- A . COPY INTO tablea FROM @%tablea RETURN_FAILED_ONLY = TRUE;
- B . COPY INTO tablea FROM @%tablea;
- C . COPY INTO tablea FROM @%tablea FILES = (‘file5.csv’);
- D . COPY INTO tablea FROM @%tablea FORCE = TRUE;
- E . COPY INTO tablea FROM @%tablea NEW_FILES_ONLY = TRUE;
- F . COPY INTO tablea FROM @%tablea MERGE = TRUE;
BC
Explanation:
Option A (RETURN_FAILED_ONLY) will only load files that previously failed to load. Since file5.csv already exists in the stage with the same name, it will not be considered a new file and will not be loaded.
Option D (FORCE) will overwrite any existing data in the table. This is not desired as we only want to load the data from file5.csv.
Option E (NEW_FILES_ONLY) will only load files that have been added to the stage since the last COPY command. This will not work because file5.csv was already in the stage before it was fixed. Option F (MERGE) is used to merge data from a stage into an existing table, creating new rows for any data not already present. This is not needed in this case as we simply want to load the data from file5.csv.
Therefore, the architect can use either COPY INTO tablea FROM @%tablea or COPY INTO tablea FROM @%tablea FILES = (‘file5.csv’) to load only file5.csv from the stage. Both options will load the data from the specified file without overwriting any existing data or requiring additional configuration
A large manufacturing company runs a dozen individual Snowflake accounts across its business divisions. The company wants to increase the level of data sharing to support supply chain optimizations and increase its purchasing leverage with multiple vendors.
The company’s Snowflake Architects need to design a solution that would allow the business divisions to decide what to share, while minimizing the level of effort spent on configuration and management. Most of the company divisions use Snowflake accounts in the same cloud deployments with a few exceptions for European-based divisions.
According to Snowflake recommended best practice, how should these requirements be met?
- A . Migrate the European accounts in the global region and manage shares in a connected graph architecture. Deploy a Data Exchange.
- B . Deploy a Private Data Exchange in combination with data shares for the European accounts.
- C . Deploy to the Snowflake Marketplace making sure that invoker_share() is used in all secure views.
- D . Deploy a Private Data Exchange and use replication to allow European data shares in the Exchange.
B
Explanation:
According to Snowflake recommended best practice, the requirements of the large manufacturing company should be met by deploying a Private Data Exchange in combination with data shares for the European accounts. A Private Data Exchange is a feature of the Snowflake Data Cloud platform that enables secure and governed sharing of data between organizations. It allows Snowflake customers to create their own data hub and invite other parts of their organization or external partners to access and contribute data sets. A Private Data Exchange provides centralized management, granular access control, and data usage metrics for the data shared in the exchange1. A data share is a secure and direct way of sharing data between Snowflake accounts without having to copy or move the data. A data share allows the data provider to grant privileges on selected objects in their account to one or more data consumers in other accounts2. By using a Private Data Exchange in combination with data shares, the company can achieve the following benefits:
The business divisions can decide what data to share and publish it to the Private Data Exchange, where it can be discovered and accessed by other members of the exchange. This reduces the effort and complexity of managing multiple data sharing relationships and configurations.
The company can leverage the existing Snowflake accounts in the same cloud deployments to create the Private Data Exchange and invite the members to join. This minimizes the migration and setup costs and leverages the existing Snowflake features and security.
The company can use data shares to share data with the European accounts that are in different regions or cloud platforms. This allows the company to comply with the regional and regulatory requirements for data sovereignty and privacy, while still enabling data collaboration across the organization.
The company can use the Snowflake Data Cloud platform to perform data analysis and transformation on the shared data, as well as integrate with other data sources and applications. This enables the company to optimize its supply chain and increase its purchasing leverage with multiple vendors.
The other options are incorrect because they do not meet the requirements or follow the best practices. Option A is incorrect because migrating the European accounts to the global region may violate the data sovereignty and privacy regulations, and deploying a Data Exchange may not provide the level of control and management that the company needs. Option C is incorrect because deploying to the Snowflake Marketplace may expose the company’s data to unwanted consumers, and using invoker_share() in secure views may not provide the desired level of security and governance. Option D is incorrect because using replication to allow European data shares in the Exchange may incur additional costs and complexity, and may not be necessary if data shares can be used instead.
Reference: Private Data Exchange | Snowflake Documentation, Introduction to Secure Data Sharing | Snowflake Documentation
A user has the appropriate privilege to see unmasked data in a column.
If the user loads this column data into another column that does not have a masking policy, what will occur?
- A . Unmasked data will be loaded in the new column.
- B . Masked data will be loaded into the new column.
- C . Unmasked data will be loaded into the new column but only users with the appropriate privileges will be able to see the unmasked data.
- D . Unmasked data will be loaded into the new column and no users will be able to see the unmasked data.
A
Explanation:
According to the SnowPro Advanced: Architect documents and learning resources, column masking policies are applied at query time based on the privileges of the user who runs the query. Therefore, if a user has the privilege to see unmasked data in a column, they will see the original data when they query that column. If they load this column data into another column that does not have a masking policy, the unmasked data will be loaded in the new column, and any user who can query the new column will see the unmasked data as well. The masking policy does not affect the underlying data in the column, only the query results.
Reference: Snowflake Documentation: Column Masking
Snowflake Learning: Column Masking
How can an Architect enable optimal clustering to enhance performance for different access paths on a given table?
- A . Create multiple clustering keys for a table.
- B . Create multiple materialized views with different cluster keys.
- C . Create super projections that will automatically create clustering.
- D . Create a clustering key that contains all columns used in the access paths.
B
Explanation:
According to the SnowPro Advanced: Architect documents and learning resources, the best way to enable optimal clustering to enhance performance for different access paths on a given table is to create multiple materialized views with different cluster keys. A materialized view is a pre-computed result set that is derived from a query on one or more base tables. A materialized view can be clustered by specifying a clustering key, which is a subset of columns or expressions that determines how the data in the materialized view is co-located in micro-partitions. By creating multiple materialized views with different cluster keys, an Architect can optimize the performance of queries that use different access paths on the same base table. For example, if a base table has columns A, B, C, and D, and there are queries that filter on A and B, or on C and D, or on A and C, the Architect can create three materialized views, each with a different cluster key: (A, B), (C, D), and (A, C). This way, each query can leverage the optimal clustering of the corresponding materialized view and achieve faster scan efficiency and better compression.
Reference: Snowflake Documentation: Materialized Views
Snowflake Learning: Materialized Views
https://www.snowflake.com/blog/using-materialized-views-to-solve-multi-clustering-performance-problems/
Company A would like to share data in Snowflake with Company B. Company B is not on the same
cloud platform as Company A.
What is required to allow data sharing between these two companies?
- A . Create a pipeline to write shared data to a cloud storage location in the target cloud provider.
- B . Ensure that all views are persisted, as views cannot be shared across cloud platforms.
- C . Setup data replication to the region and cloud platform where the consumer resides.
- D . Company A and Company B must agree to use a single cloud platform: Data sharing is only possible if the companies share the same cloud provider.
C
Explanation:
According to the SnowPro Advanced: Architect documents and learning resources, the requirement to allow data sharing between two companies that are not on the same cloud platform is to set up data replication to the region and cloud platform where the consumer resides. Data replication is a feature of Snowflake that enables copying databases across accounts in different regions and cloud platforms. Data replication allows data providers to securely share data with data consumers across different regions and cloud platforms by creating a replica database in the consumer’s account. The replica database is read-only and automatically synchronized with the primary database in the provider’s account. Data replication is useful for scenarios where data sharing is not possible or desirable due to latency, compliance, or security reasons1. The other options are incorrect because they are not required or feasible to allow data sharing between two companies that are not on the same cloud platform. Option A is incorrect because creating a pipeline to write shared data to a cloud storage location in the target cloud provider is not a secure or efficient way of sharing data. It would require additional steps to load the data from the cloud storage to the consumer’s account, and it would not leverage the benefits of Snowflake’s data sharing features. Option B is incorrect because ensuring that all views are persisted is not relevant for data sharing across cloud platforms. Views can be shared across cloud platforms as long as they reference objects in the same database. Persisting views is an option to improve the performance of querying views, but it is not required for data sharing2. Option D is incorrect because Company A and Company B do not need to agree to use a single cloud platform. Data sharing is possible across different cloud platforms using data replication or other methods, such as listings or auto-fulfillment3.
Reference: Replicating Databases Across Multiple Accounts | Snowflake Documentation, Persisting Views | Snowflake
Documentation, Sharing Data Across Regions and Cloud Platforms | Snowflake Documentation
What are some of the characteristics of result set caches? (Choose three.)
- A . Time Travel queries can be executed against the result set cache.
- B . Snowflake persists the data results for 24 hours.
- C . Each time persisted results for a query are used, a 24-hour retention period is reset.
- D . The data stored in the result cache will contribute to storage costs.
- E . The retention period can be reset for a maximum of 31 days.
- F . The result set cache is not shared between warehouses.
B, C, E
Explanation:
Comprehensive and Detailed Explanation.
According to the SnowPro Advanced: Architect documents and learning resources, some of the characteristics of result set caches are:
Snowflake persists the data results for 24 hours. This means that the result set cache holds the results of every query executed in the past 24 hours, and can be reused if the same query is submitted again and the underlying data has not changed1.
Each time persisted results for a query are used, a 24-hour retention period is reset. This means that the result set cache extends the lifetime of the results every time they are reused, up to a maximum of 31 days from the date and time that the query was first executed1.
The retention period can be reset for a maximum of 31 days. This means that the result set cache will purge the results after 31 days, regardless of whether they are reused or not. After 31 days, the next time the query is submitted, a new result is generated and persisted1.
The other options are incorrect because they are not characteristics of result set caches. Option A is incorrect because Time Travel queries cannot be executed against the result set cache. Time Travel queries use the AS OF clause to access historical data that is stored in the storage layer, not the result set cache2. Option D is incorrect because the data stored in the result set cache does not contribute to storage costs. The result set cache is maintained by the service layer, and does not incur any additional charges1. Option F is incorrect because the result set cache is shared between warehouses. The result set cache is available across virtual warehouses, so query results returned to one user are available to any other user on the system who executes the same query, provided the underlying data has not changed1.
Reference: Using Persisted Query Results | Snowflake Documentation, Time Travel | Snowflake Documentation
Which organization-related tasks can be performed by the ORGADMIN role? (Choose three.)
- A . Changing the name of the organization
- B . Creating an account
- C . Viewing a list of organization accounts
- D . Changing the name of an account
- E . Deleting an account
- F . Enabling the replication of a database
B, C, F
Explanation:
According to the SnowPro Advanced: Architect documents and learning resources, the organization-related tasks that can be performed by the ORGADMIN role are:
Creating an account in the organization. A user with the ORGADMIN role can use the CREATE ACCOUNT command to create a new account that belongs to the same organization as the current account1.
Viewing a list of organization accounts. A user with the ORGADMIN role can use the SHOW ORGANIZATION ACCOUNTS command to view the names and properties of all accounts in the organization2. Alternatively, the user can use the Admin » Accounts page in the web interface to view the organization name and account names3.
Enabling the replication of a database. A user with the ORGADMIN role can use the
SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER function to enable database replication for an account in the organization. This allows the user to replicate databases across accounts in different regions and cloud platforms for data availability and durability4.
The other options are incorrect because they are not organization-related tasks that can be performed by the ORGADMIN role. Option A is incorrect because changing the name of the organization is not a task that can be performed by the ORGADMIN role. To change the name of an organization, the user must contact Snowflake Support3. Option D is incorrect because changing the name of an account is not a task that can be performed by the ORGADMIN role. To change the name of an account, the user must contact Snowflake Support5. Option E is incorrect because deleting an account is not a task that can be performed by the ORGADMIN role. To delete an account, the user must contact Snowflake Support.
Reference: CREATE ACCOUNT | Snowflake Documentation, SHOW ORGANIZATION ACCOUNTS | Snowflake Documentation, Getting Started with Organizations | Snowflake Documentation, SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER | Snowflake Documentation, ALTER ACCOUNT | Snowflake Documentation, [DROP ACCOUNT | Snowflake Documentation]
A Data Engineer is designing a near real-time ingestion pipeline for a retail company to ingest event logs into Snowflake to derive insights. A Snowflake Architect is asked to define security best practices to configure access control privileges for the data load for auto-ingest to Snowpipe.
What are the MINIMUM object privileges required for the Snowpipe user to execute Snowpipe?
- A . OWNERSHIP on the named pipe, USAGE on the named stage, target database, and schema, and INSERT and SELECT on the target table
- B . OWNERSHIP on the named pipe, USAGE and READ on the named stage, USAGE on the target database and schema, and INSERT end SELECT on the target table
- C . CREATE on the named pipe, USAGE and READ on the named stage, USAGE on the target database and schema, and INSERT end SELECT on the target table
- D . USAGE on the named pipe, named stage, target database, and schema, and INSERT and SELECT on the target table
B
Explanation:
According to the SnowPro Advanced: Architect documents and learning resources, the minimum object privileges required for the Snowpipe user to execute Snowpipe are:
OWNERSHIP on the named pipe. This privilege allows the Snowpipe user to create, modify, and drop the pipe object that defines the COPY statement for loading data from the stage to the table1. USAGE and READ on the named stage. These privileges allow the Snowpipe user to access and read the data files from the stage that are loaded by Snowpipe2.
USAGE on the target database and schema. These privileges allow the Snowpipe user to access the database and schema that contain the target table3.
INSERT and SELECT on the target table. These privileges allow the Snowpipe user to insert data into the table and select data from the table4.
The other options are incorrect because they do not specify the minimum object privileges required for the Snowpipe user to execute Snowpipe. Option A is incorrect because it does not include the READ privilege on the named stage, which is required for the Snowpipe user to read the data files from the stage. Option C is incorrect because it does not include the OWNERSHIP privilege on the named pipe, which is required for the Snowpipe user to create, modify, and drop the pipe object. Option D is incorrect because it does not include the OWNERSHIP privilege on the named pipe or the READ privilege on the named stage, which are both required for the Snowpipe user to execute Snowpipe.
Reference: CREATE PIPE | Snowflake Documentation, CREATE STAGE | Snowflake Documentation, CREATE DATABASE | Snowflake Documentation, CREATE TABLE | Snowflake Documentation
The IT Security team has identified that there is an ongoing credential stuffing attack on many of their organization’s system.
What is the BEST way to find recent and ongoing login attempts to Snowflake?
- A . Call the LOGIN_HISTORY Information Schema table function.
- B . Query the LOGIN_HISTORY view in the ACCOUNT_USAGE schema in the SNOWFLAKE database.
- C . View the History tab in the Snowflake UI and set up a filter for SQL text that contains the text "LOGIN".
- D . View the Users section in the Account tab in the Snowflake UI and review the last login column.
B
Explanation:
This view can be used to query login attempts by Snowflake users within the last 365 days (1 year). It provides information such as the event timestamp, the user name, the client IP, the authentication method, the success or failure status, and the error code or message if the login attempt was unsuccessful. By querying this view, the IT Security team can identify any suspicious or malicious login attempts to Snowflake and take appropriate actions to prevent credential stuffing attacks1. The other options are not the best ways to find recent and ongoing login attempts to Snowflake. Option A is incorrect because the LOGIN_HISTORY Information Schema table function only returns login events within the last 7 days, which may not be sufficient to detect credential stuffing attacks that span a longer period of time2. Option C is incorrect because the History tab in the Snowflake UI only shows the queries executed by the current user or role, not the login events of other users or roles3. Option D is incorrect because the Users section in the Account tab in the Snowflake UI only shows the last login time for each user, not the details of the login attempts or the failures.
An Architect has a VPN_ACCESS_LOGS table in the SECURITY_LOGS schema containing timestamps of the connection and disconnection, username of the user, and summary statistics.
What should the Architect do to enable the Snowflake search optimization service on this table?
- A . Assume role with OWNERSHIP on future tables and ADD SEARCH OPTIMIZATION on the SECURITY_LOGS schema.
- B . Assume role with ALL PRIVILEGES including ADD SEARCH OPTIMIZATION in the SECURITY LOGS schema.
- C . Assume role with OWNERSHIP on VPN_ACCESS_LOGS and ADD SEARCH OPTIMIZATION in the SECURITY_LOGS schema.
- D . Assume role with ALL PRIVILEGES on VPN_ACCESS_LOGS and ADD SEARCH OPTIMIZATION in the SECURITY_LOGS schema.
C
Explanation:
According to the SnowPro Advanced: Architect Exam Study Guide, to enable the search optimization service on a table, the user must have the ADD SEARCH OPTIMIZATION privilege on the table and the schema. The privilege can be granted explicitly or inherited from a higher-level object, such as a database or a role. The OWNERSHIP privilege on a table implies the ADD SEARCH OPTIMIZATION privilege, so the user who owns the table can enable the search optimization service on it. Therefore, the correct answer is to assume a role with OWNERSHIP on VPN_ACCESS_LOGS and ADD SEARCH OPTIMIZATION in the SECURITY_LOGS schema. This will allow the user to enable the search optimization service on the VPN_ACCESS_LOGS table and any future tables created in the SECURITY_LOGS schema. The other options are incorrect because they either grant excessive privileges or do not grant the required privileges on the table or the schema.
Reference: SnowPro Advanced: Architect Exam Study Guide, page 11, section 2.3.1
Snowflake Documentation: Enabling the Search Optimization Service
A table contains five columns and it has millions of records.
The cardinality distribution of the columns is shown below:
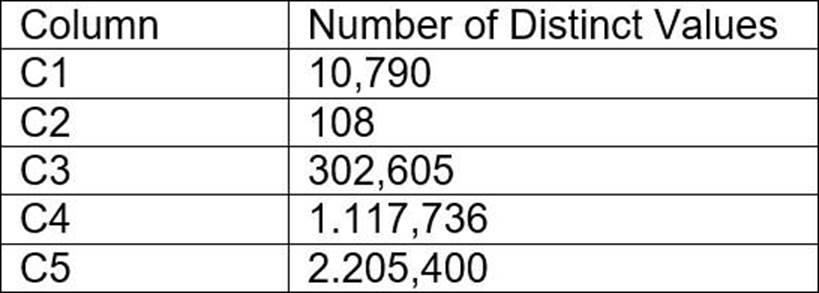

Column C4 and C5 are mostly used by SELECT queries in the GROUP BY and ORDER BY clauses.
Whereas columns C1, C2 and C3 are heavily used in filter and join conditions of SELECT queries.
The Architect must design a clustering key for this table to improve the query performance.
Based on Snowflake recommendations, how should the clustering key columns be ordered while defining the multi-column clustering key?
- A . C5, C4, C2
- B . C3, C4, C5
- C . C1, C3, C2
- D . C2, C1, C3
C
Explanation:
According to the Snowflake documentation, the following are some considerations for choosing
clustering for a table1:
Clustering is optimal when either:
You require the fastest possible response times, regardless of cost.
Your improved query performance offsets the credits required to cluster and maintain the table.
Clustering is most effective when the clustering key is used in the following types of query predicates:
Filter predicates (e.g. WHERE clauses)
Join predicates (e.g. ON clauses)
Grouping predicates (e.g. GROUP BY clauses)
Sorting predicates (e.g. ORDER BY clauses)
Clustering is less effective when the clustering key is not used in any of the above query predicates, or when the clustering key is used in a predicate that requires a function or expression to be applied to the key (e.g. DATE_TRUNC, TO_CHAR, etc.).
For most tables, Snowflake recommends a maximum of 3 or 4 columns (or expressions) per key.
Adding more than 3-4 columns tends to increase costs more than benefits.
Based on these considerations, the best option for the clustering key columns is C. C1, C3, C2, because:
These columns are heavily used in filter and join conditions of SELECT queries, which are the most effective types of predicates for clustering.
These columns have high cardinality, which means they have many distinct values and can help reduce the clustering skew and improve the compression ratio.
These columns are likely to be correlated with each other, which means they can help co-locate similar rows in the same micro-partitions and improve the scan efficiency.
These columns do not require any functions or expressions to be applied to them, which means they can be directly used in the predicates without affecting the clustering.
Reference: 1: Considerations for Choosing Clustering for a Table | Snowflake Documentation
Which security, governance, and data protection features require, at a MINIMUM, the Business Critical edition of Snowflake? (Choose two.)
- A . Extended Time Travel (up to 90 days)
- B . Customer-managed encryption keys through Tri-Secret Secure
- C . Periodic rekeying of encrypted data
- D . AWS, Azure, or Google Cloud private connectivity to Snowflake
- E . Federated authentication and SSO
B, D
Explanation:
According to the SnowPro Advanced: Architect documents and learning resources, the security, governance, and data protection features that require, at a minimum, the Business Critical edition of Snowflake are:
Customer-managed encryption keys through Tri-Secret Secure. This feature allows customers to manage their own encryption keys for data at rest in Snowflake, using a combination of three secrets: a master key, a service key, and a security password. This provides an additional layer of security and control over the data encryption and decryption process1.
Periodic rekeying of encrypted data. This feature allows customers to periodically rotate the encryption keys for data at rest in Snowflake, using either Snowflake-managed keys or customer-managed keys. This enhances the security and protection of the data by reducing the risk of key compromise or exposure2.
The other options are incorrect because they do not require the Business Critical edition of Snowflake. Option A is incorrect because extended Time Travel (up to 90 days) is available with the Enterprise edition of Snowflake3. Option D is incorrect because AWS, Azure, or Google Cloud private connectivity to Snowflake is available with the Standard edition of Snowflake4. Option E is incorrect because federated authentication and SSO are available with the Standard edition of Snowflake5.
Reference: Tri-Secret Secure | Snowflake Documentation, Periodic Rekeying of Encrypted Data | Snowflake Documentation, Snowflake Editions | Snowflake
Documentation, Snowflake Network Policies | Snowflake Documentation, Configuring Federated Authentication and SSO | Snowflake Documentation
A company wants to deploy its Snowflake accounts inside its corporate network with no visibility on the internet. The company is using a VPN infrastructure and Virtual Desktop Infrastructure (VDI) for its Snowflake users. The company also wants to re-use the login credentials set up for the VDI to eliminate redundancy when managing logins.
What Snowflake functionality should be used to meet these requirements? (Choose two.)
- A . Set up replication to allow users to connect from outside the company VPN.
- B . Provision a unique company Tri-Secret Secure key.
- C . Use private connectivity from a cloud provider.
- D . Set up SSO for federated authentication.
- E . Use a proxy Snowflake account outside the VPN, enabling client redirect for user logins.
C, D
Explanation:
According to the SnowPro Advanced: Architect documents and learning resources, the Snowflake functionality that should be used to meet these requirements are:
Use private connectivity from a cloud provider. This feature allows customers to connect to Snowflake from their own private network without exposing their data to the public Internet. Snowflake integrates with AWS PrivateLink, Azure Private Link, and Google Cloud Private Service Connect to offer private connectivity from customers’ VPCs or VNets to Snowflake endpoints. Customers can control how traffic reaches the Snowflake endpoint and avoid the need for proxies or public IP addresses123.
Set up SSO for federated authentication. This feature allows customers to use their existing identity provider (IdP) to authenticate users for SSO access to Snowflake. Snowflake supports most SAML 2.0-compliant vendors as an IdP, including Okta, Microsoft AD FS, Google G Suite, Microsoft Azure Active Directory, OneLogin, Ping Identity, and PingOne. By setting up SSO for federated authentication, customers can leverage their existing user credentials and profile information, and provide stronger security than username/password authentication4.
The other options are incorrect because they do not meet the requirements or are not feasible. Option A is incorrect because setting up replication does not allow users to connect from outside the company VPN. Replication is a feature of Snowflake that enables copying databases across accounts in different regions and cloud platforms. Replication does not affect the connectivity or visibility of the accounts5. Option B is incorrect because provisioning a unique company Tri-Secret Secure key does not affect the network or authentication requirements. Tri-Secret Secure is a feature of Snowflake that allows customers to manage their own encryption keys for data at rest in Snowflake, using a combination of three secrets: a master key, a service key, and a security password. Tri-Secret Secure provides an additional layer of security and control over the data encryption and decryption process, but it does not enable private connectivity or SSO6. Option E is incorrect because using a proxy Snowflake account outside the VPN, enabling client redirect for user logins, is not a supported or recommended way of meeting the requirements. Client redirect is a feature of Snowflake that allows customers to connect to a different Snowflake account than the one specified in the connection string. This feature is useful for scenarios such as cross-region failover, data sharing, and account migration, but it does not provide private connectivity or SSO7.
Reference: AWS PrivateLink
& Snowflake | Snowflake Documentation, Azure Private Link & Snowflake | Snowflake Documentation, Google Cloud Private Service Connect & Snowflake | Snowflake Documentation, Overview of Federated Authentication and SSO | Snowflake Documentation, Replicating Databases Across Multiple Accounts | Snowflake Documentation, Tri-Secret Secure | Snowflake Documentation, Redirecting Client Connections | Snowflake Documentation
How do Snowflake databases that are created from shares differ from standard databases that are not created from shares? (Choose three.)
- A . Shared databases are read-only.
- B . Shared databases must be refreshed in order for new data to be visible.
- C . Shared databases cannot be cloned.
- D . Shared databases are not supported by Time Travel.
- E . Shared databases will have the PUBLIC or INFORMATION_SCHEMA schemas without explicitly granting these schemas to the share.
- F . Shared databases can also be created as transient databases.
A, C, D
Explanation:
According to the SnowPro Advanced: Architect documents and learning resources, the ways that Snowflake databases that are created from shares differ from standard databases that are not created from shares are:
Shared databases are read-only. This means that the data consumers who access the shared databases cannot modify or delete the data or the objects in the databases. The data providers who share the databases have full control over the data and the objects, and can grant or revoke privileges on them1.
Shared databases cannot be cloned. This means that the data consumers who access the shared databases cannot create a copy of the databases or the objects in the databases. The data providers who share the databases can clone the databases or the objects, but the clones are not automatically shared2.
Shared databases are not supported by Time Travel. This means that the data consumers who access the shared databases cannot use the AS OF clause to query historical data or restore deleted data. The data providers who share the databases can use Time Travel on the databases or the objects, but the historical data is not visible to the data consumers3.
The other options are incorrect because they are not ways that Snowflake databases that are created from shares differ from standard databases that are not created from shares. Option B is incorrect because shared databases do not need to be refreshed in order for new data to be visible. The data consumers who access the shared databases can see the latest data as soon as the data providers update the data1. Option E is incorrect because shared databases will not have the PUBLIC or INFORMATION_SCHEMA schemas without explicitly granting these schemas to the share. The data consumers who access the shared databases can only see the objects that the data providers grant to the share, and the PUBLIC and INFORMATION_SCHEMA schemas are not granted by default4. Option F is incorrect because shared databases cannot be created as transient databases. Transient databases are databases that do not support Time Travel or Fail-safe, and can be dropped without affecting the retention period of the data. Shared databases are always created as permanent databases, regardless of the type of the source database5.
Reference: Introduction to Secure Data Sharing | Snowflake Documentation, Cloning Objects | Snowflake Documentation, Time Travel | Snowflake Documentation, Working with Shares | Snowflake Documentation, CREATE DATABASE | Snowflake Documentation
What integration object should be used to place restrictions on where data may be exported?
- A . Stage integration
- B . Security integration
- C . Storage integration
- D . API integration
B
Explanation:
According to the SnowPro Advanced: Architect documents and learning resources, the integration object that should be used to place restrictions on where data may be exported is the security integration. A security integration is a Snowflake object that provides an interface between Snowflake and third-party security services, such as Okta, Duo, or Google Authenticator. A security integration can be used to enforce policies on data export, such as requiring multi-factor authentication (MFA) or restricting the export destination to a specific network or domain. A security integration can also be used to enable single sign-on (SSO) or federated authentication for Snowflake users1.
The other options are incorrect because they are not integration objects that can be used to place restrictions on where data may be exported. Option A is incorrect because a stage integration is not a valid type of integration object in Snowflake. A stage is a Snowflake object that references a location where data files are stored, such as an internal stage, an external stage, or a named stage. A stage is not an integration object that provides an interface between Snowflake and third-party services2. Option C is incorrect because a storage integration is a Snowflake object that provides an interface between Snowflake and external cloud storage, such as Amazon S3, Azure Blob Storage, or Google Cloud Storage. A storage integration can be used to securely access data files from external cloud storage without exposing the credentials, but it cannot be used to place restrictions on where data may be exported3. Option D is incorrect because an API integration is a Snowflake object that
provides an interface between Snowflake and third-party services that use REST APIs, such as Salesforce, Slack, or Twilio. An API integration can be used to securely call external REST APIs from Snowflake using the CALL_EXTERNAL_API function, but it cannot be used to place restrictions on where data may be exported4.
Reference: CREATE SECURITY INTEGRATION | Snowflake Documentation, CREATE STAGE | Snowflake Documentation, CREATE STORAGE INTEGRATION | Snowflake Documentation, CREATE API INTEGRATION | Snowflake Documentation
The following DDL command was used to create a task based on a stream:


Assuming MY_WH is set to auto_suspend C 60 and used exclusively for this task, which statement is true?
- A . The warehouse MY_WH will be made active every five minutes to check the stream.
- B . The warehouse MY_WH will only be active when there are results in the stream.
- C . The warehouse MY_WH will never suspend.
- D . The warehouse MY_WH will automatically resize to accommodate the size of the stream.
B
Explanation:
The warehouse MY_WH will only be active when there are results in the stream. This is because the task is created based on a stream, which means that the task will only be executed when there are new data in the stream. Additionally, the warehouse is set to auto_suspend – 60, which means that the warehouse will automatically suspend after 60 seconds of inactivity. Therefore, the warehouse will only be active when there are results in the stream.
Reference: [CREATE TASK | Snowflake Documentation]
[Using Streams and Tasks | Snowflake Documentation]
[CREATE WAREHOUSE | Snowflake Documentation]
What is a characteristic of loading data into Snowflake using the Snowflake Connector for Kafka?
- A . The Connector only works in Snowflake regions that use AWS infrastructure.
- B . The Connector works with all file formats, including text, JSON, Avro, Ore, Parquet, and XML.
- C . The Connector creates and manages its own stage, file format, and pipe objects.
- D . Loads using the Connector will have lower latency than Snowpipe and will ingest data in real time.
C
Explanation:
According to the SnowPro Advanced: Architect documents and learning resources, a characteristic of loading data into Snowflake using the Snowflake Connector for Kafka is that the Connector creates and manages its own stage, file format, and pipe objects. The stage is an internal stage that is used to store the data files from the Kafka topics. The file format is a JSON or Avro file format that is used to parse the data files. The pipe is a Snowpipe object that is used to load the data files into the Snowflake table. The Connector automatically creates and configures these objects based on the Kafka configuration properties, and handles the cleanup and maintenance of these objects1.
The other options are incorrect because they are not characteristics of loading data into Snowflake using the Snowflake Connector for Kafka. Option A is incorrect because the Connector works in Snowflake regions that use any cloud infrastructure, not just AWS. The Connector supports AWS, Azure, and Google Cloud platforms, and can load data across different regions and cloud platforms using data replication2. Option B is incorrect because the Connector does not work with all file formats, only JSON and Avro. The Connector expects the data in the Kafka topics to be in JSON or Avro format, and parses the data accordingly. Other file formats, such as text, ORC, Parquet, or XML, are not supported by the Connector3. Option D is incorrect because loads using the Connector do not have lower latency than Snowpipe, and do not ingest data in real time. The Connector uses Snowpipe to load data into Snowflake, and inherits the same latency and performance characteristics of Snowpipe. The Connector does not provide real-time ingestion, but near real-time ingestion, depending on the frequency and size of the data files4.
Reference: Installing and Configuring the Kafka Connector | Snowflake Documentation, Sharing Data Across Regions and Cloud Platforms | Snowflake Documentation, Overview of the Kafka Connector | Snowflake Documentation, Using Snowflake Connector for Kafka With Snowpipe Streaming | Snowflake Documentation
A healthcare company wants to share data with a medical institute. The institute is running a Standard edition of Snowflake; the healthcare company is running a Business Critical edition.
How can this data be shared?
- A . The healthcare company will need to change the institute’s Snowflake edition in the accounts panel.
- B . By default, sharing is supported from a Business Critical Snowflake edition to a Standard edition.
- C . Contact Snowflake and they will execute the share request for the healthcare company.
- D . Set the share_restriction parameter on the shared object to false.
D
Explanation:
By default, Snowflake does not allow sharing data from a Business Critical edition to a non-Business Critical edition. This is because Business Critical edition provides enhanced security and data protection features that are not available in lower editions. However, this restriction can be overridden by setting the share_restriction parameter on the shared object (database, schema, or table) to false. This parameter allows the data provider to explicitly allow sharing data with lower edition accounts. Note that this parameter can only be set by the data provider, not the data consumer. Also, setting this parameter to false may reduce the level of security and data protection for the shared data.
Reference: Enable Data Share:Business Critical Account to Lower Edition
Sharing Is Not Allowed From An Account on BUSINESS CRITICAL Edition to an Account On A Lower Edition
SQL Execution Error: Sharing is Not Allowed from an Account on BUSINESS CRITICAL Edition to an Account on a Lower Edition
Snowflake Editions | Snowflake Documentation
An Architect is designing a pipeline to stream event data into Snowflake using the Snowflake Kafka connector. The Architect’s highest priority is to configure the connector to stream data in the MOST cost-effective manner.
Which of the following is recommended for optimizing the cost associated with the Snowflake Kafka connector?
- A . Utilize a higher Buffer.flush.time in the connector configuration.
- B . Utilize a higher Buffer.size.bytes in the connector configuration.
- C . Utilize a lower Buffer.size.bytes in the connector configuration.
- D . Utilize a lower Buffer.count.records in the connector configuration.
A
Explanation:
The minimum value supported for the buffer.flush.time property is 1 (in seconds). For higher average data flow rates, we suggest that you decrease the default value for improved latency. If cost is a greater concern than latency, you could increase the buffer flush time. Be careful to flush the Kafka memory buffer before it becomes full to avoid out of memory exceptions. https://docs.snowflake.com/en/user-guide/data-load-snowpipe-streaming-kafka
An Architect has chosen to separate their Snowflake Production and QA environments using two separate Snowflake accounts.
The QA account is intended to run and test changes on data and database objects before pushing those changes to the Production account. It is a requirement that all database objects and data in the QA account need to be an exact copy of the database objects, including privileges and data in the Production account on at least a nightly basis.
Which is the LEAST complex approach to use to populate the QA account with the Production account’s data and database objects on a nightly basis?
- A . 1) Create a share in the Production account for each database
2) Share access to the QA account as a Consumer
3) The QA account creates a database directly from each share
4) Create clones of those databases on a nightly basis
5) Run tests directly on those cloned databases - B . 1) Create a stage in the Production account
2) Create a stage in the QA account that points to the same external object-storage location
3) Create a task that runs nightly to unload each table in the Production account into the stage
4) Use Snowpipe to populate the QA account - C . 1) Enable replication for each database in the Production account
2) Create replica databases in the QA account
3) Create clones of the replica databases on a nightly basis
4) Run tests directly on those cloned databases - D . 1) In the Production account, create an external function that connects into the QA account and returns all the data for one specific table
2) Run the external function as part of a stored procedure that loops through each table in the Production account and populates each table in the QA account
C
Explanation:
This approach is the least complex because it uses Snowflake’s built-in replication feature to copy the data and database objects from the Production account to the QA account. Replication is a fast and efficient way to synchronize data across accounts, regions, and cloud platforms. It also preserves the privileges and metadata of the replicated objects. By creating clones of the replica databases, the QA account can run tests on the cloned data without affecting the original data. Clones are also zero-copy, meaning they do not consume any additional storage space unless the data is modified. This approach does not require any external stages, tasks, Snowpipe, or external functions, which can add complexity and overhead to the data transfer process.
Reference: Introduction to Replication and Failover
Replicating Databases Across Multiple Accounts
Cloning Considerations
A user can change object parameters using which of the following roles?
- A . ACCOUNTADMIN, SECURITYADMIN
- B . SYSADMIN, SECURITYADMIN
- C . ACCOUNTADMIN, USER with PRIVILEGE
- D . SECURITYADMIN, USER with PRIVILEGE
C
Explanation:
According to the Snowflake documentation, object parameters are parameters that can be set on
individual objects such as databases, schemas, tables, and stages. Object parameters can be set by
users with the appropriate privileges on the objects. For example, to set the object parameter AUTO_REFRESH on a table, the user must have the MODIFY privilege on the table. The ACCOUNTADMIN role has the highest level of privileges on all objects in the account, so it can set any object parameter on any object. However, other roles, such as SECURITYADMIN or SYSADMIN, do not have the same level of privileges on all objects, so they cannot set object parameters on objects they do not own or have the required privileges on. Therefore, the correct answer is C. ACCOUNTADMIN,
USER with PRIVILEGE.
Reference: Parameters | Snowflake Documentation
Object Parameters | Snowflake Documentation
Object Privileges | Snowflake Documentation
A media company needs a data pipeline that will ingest customer review data into a Snowflake table, and apply some transformations. The company also needs to use Amazon Comprehend to do sentiment analysis and make the de-identified final data set available publicly for advertising companies who use different cloud providers in different regions.
The data pipeline needs to run continuously ang efficiently as new records arrive in the object storage leveraging event notifications. Also, the operational complexity, maintenance of the infrastructure, including platform upgrades and security, and the development effort should be minimal.
Which design will meet these requirements?
- A . Ingest the data using COPY INTO and use streams and tasks to orchestrate transformations. Export the data into Amazon S3 to do model inference with Amazon Comprehend and ingest the data back into a Snowflake table. Then create a listing in the Snowflake Marketplace to make the data available to other companies.
- B . Ingest the data using Snowpipe and use streams and tasks to orchestrate transformations. Create an external function to do model inference with Amazon Comprehend and write the final records to a Snowflake table. Then create a listing in the Snowflake Marketplace to make the data available to other companies.
- C . Ingest the data into Snowflake using Amazon EMR and PySpark using the Snowflake Spark connector. Apply transformations using another Spark job. Develop a python program to do model inference by leveraging the Amazon Comprehend text analysis API. Then write the results to a Snowflake table and create a listing in the Snowflake Marketplace to make the data available to other companies.
- D . Ingest the data using Snowpipe and use streams and tasks to orchestrate transformations. Export the data into Amazon S3 to do model inference with Amazon Comprehend and ingest the data back into a Snowflake table. Then create a listing in the Snowflake Marketplace to make the data available to other companies.
B
Explanation:
This design meets all the requirements for the data pipeline. Snowpipe is a feature that enables continuous data loading into Snowflake from object storage using event notifications. It is efficient, scalable, and serverless, meaning it does not require any infrastructure or maintenance from the user. Streams and tasks are features that enable automated data pipelines within Snowflake, using change data capture and scheduled execution. They are also efficient, scalable, and serverless, and they simplify the data transformation process. External functions are functions that can invoke external services or APIs from within Snowflake. They can be used to integrate with Amazon Comprehend and perform sentiment analysis on the data. The results can be written back to a Snowflake table using standard SQL commands. Snowflake Marketplace is a platform that allows data providers to share data with data consumers across different accounts, regions, and cloud platforms. It is a secure and easy way to make data publicly available to other companies.
Reference: Snowpipe Overview | Snowflake Documentation Introduction to Data Pipelines | Snowflake Documentation External Functions Overview | Snowflake Documentation Snowflake Data Marketplace Overview | Snowflake Documentation
A Snowflake Architect is designing an application and tenancy strategy for an organization where strong legal isolation rules as well as multi-tenancy are requirements.
Which approach will meet these requirements if Role-Based Access Policies (RBAC) is a viable option for isolating tenants?
- A . Create accounts for each tenant in the Snowflake organization.
- B . Create an object for each tenant strategy if row level security is viable for isolating tenants.
- C . Create an object for each tenant strategy if row level security is not viable for isolating tenants.
- D . Create a multi-tenant table strategy if row level security is not viable for isolating tenants.
A
Explanation:
This approach meets the requirements of strong legal isolation and multi-tenancy. By creating separate accounts for each tenant, the application can ensure that each tenant has its own dedicated
storage, compute, and metadata resources, as well as its own encryption keys and security policies.
This provides the highest level of isolation and data protection among the tenancy models.
Furthermore, by creating the accounts within the same Snowflake organization, the application can leverage the features of Snowflake Organizations, such as centralized billing, account management, and cross-account data sharing.
Reference: Snowflake Organizations Overview | Snowflake Documentation Design Patterns for Building Multi-Tenant Applications on Snowflake
Which statements describe characteristics of the use of materialized views in Snowflake? (Choose two.)
- A . They can include ORDER BY clauses.
- B . They cannot include nested subqueries.
- C . They can include context functions, such as CURRENT_TIME().
- D . They can support MIN and MAX aggregates.
- E . They can support inner joins, but not outer joins.
B, D
Explanation:
According to the Snowflake documentation, materialized views have some limitations on the query specification that defines them. One of these limitations is that they cannot include nested subqueries, such as subqueries in the FROM clause or scalar subqueries in the SELECT list. Another limitation is that they cannot include ORDER BY clauses, context functions (such as CURRENT_TIME()), or outer joins. However, materialized views can support MIN and MAX aggregates, as well as other aggregate functions, such as SUM, COUNT, and AVG.
Reference: Limitations on Creating Materialized Views | Snowflake Documentation Working with Materialized Views | Snowflake Documentation
The Data Engineering team at a large manufacturing company needs to engineer data coming from many sources to support a wide variety of use cases and data consumer requirements which include:
1) Finance and Vendor Management team members who require reporting and visualization
2) Data Science team members who require access to raw data for ML model development
3) Sales team members who require engineered and protected data for data monetization What Snowflake data modeling approaches will meet these requirements? (Choose two.)
- A . Consolidate data in the company’s data lake and use EXTERNAL TABLES.
- B . Create a raw database for landing and persisting raw data entering the data pipelines.
- C . Create a set of profile-specific databases that aligns data with usage patterns.
- D . Create a single star schema in a single database to support all consumers’ requirements.
- E . Create a Data Vault as the sole data pipeline endpoint and have all consumers directly access the Vault.
B, C
Explanation:
These two approaches are recommended by Snowflake for data modeling in a data lake scenario. Creating a raw database allows the data engineering team to ingest data from various sources without any transformation or cleansing, preserving the original data quality and format. This enables the data science team to access the raw data for ML model development. Creating a set of profile-specific databases allows the data engineering team to apply different transformations and optimizations for different use cases and data consumer requirements. For example, the finance and vendor management team can access a dimensional database that supports reporting and visualization, while the sales team can access a secure database that supports data monetization.
Reference: Snowflake Data Lake Architecture | Snowflake Documentation Snowflake Data Lake Best Practices | Snowflake Documentation
An Architect on a new project has been asked to design an architecture that meets Snowflake security, compliance, and governance requirements as follows:
1) Use Tri-Secret Secure in Snowflake
2) Share some information stored in a view with another Snowflake customer
3) Hide portions of sensitive information from some columns
4) Use zero-copy cloning to refresh the non-production environment from the production environment
To meet these requirements, which design elements must be implemented? (Choose three.)
- A . Define row access policies.
- B . Use the Business-Critical edition of Snowflake.
- C . Create a secure view.
- D . Use the Enterprise edition of Snowflake.
- E . Use Dynamic Data Masking.
- F . Create a materialized view.
B, C, E
Explanation:
These three design elements are required to meet the security, compliance, and governance requirements for the project.
To use Tri-Secret Secure in Snowflake, the Business Critical edition of Snowflake is required. This edition provides enhanced data protection features, such as customer-managed encryption keys, that are not available in lower editions. Tri-Secret Secure is a feature that combines a Snowflake-maintained key and a customer-managed key to create a composite master key to encrypt the data in Snowflake1.
To share some information stored in a view with another Snowflake customer, a secure view is recommended. A secure view is a view that hides the underlying data and the view definition from unauthorized users. Only the owner of the view and the users who are granted the owner’s role can see the view definition and the data in the base tables of the view2. A secure view can be shared with another Snowflake account using a data share3.
To hide portions of sensitive information from some columns, Dynamic Data Masking can be used. Dynamic Data Masking is a feature that allows applying masking policies to columns to selectively mask plain-text data at query time. Depending on the masking policy conditions and the user’s role, the data can be fully or partially masked, or shown as plain-text4.
Which of the following are characteristics of how row access policies can be applied to external tables? (Choose three.)
- A . An external table can be created with a row access policy, and the policy can be applied to the VALUE column.
- B . A row access policy can be applied to the VALUE column of an existing external table.
- C . A row access policy cannot be directly added to a virtual column of an external table.
- D . External tables are supported as mapping tables in a row access policy.
- E . While cloning a database, both the row access policy and the external table will be cloned.
- F . A row access policy cannot be applied to a view created on top of an external table.
A, B, C
Explanation:
These three statements are true according to the Snowflake documentation and the web search results. A row access policy is a feature that allows filtering rows based on user-defined conditions. A row access policy can be applied to an external table, which is a table that reads data from external files in a stage. However, there are some limitations and considerations for using row access policies with external tables.
An external table can be created with a row access policy by using the WITH ROW ACCESS POLICY clause in the CREATE EXTERNAL TABLE statement. The policy can be applied to the VALUE column, which is the column that contains the raw data from the external files in a VARIANT data type1.
A row access policy can also be applied to the VALUE column of an existing external table by using the ALTER TABLE statement with the SET ROW ACCESS POLICY clause2.
A row access policy cannot be directly added to a virtual column of an external table. A virtual column is a column that is derived from the VALUE column using an expression. To apply a row access policy to a virtual column, the policy must be applied to the VALUE column and the expression must be repeated in the policy definition3.
External tables are not supported as mapping tables in a row access policy. A mapping table is a table that is used to determine the access rights of users or roles based on some criteria. Snowflake does not support using an external table as a mapping table because it may cause performance issues or errors4.
While cloning a database, Snowflake clones the row access policy, but not the external table. Therefore, the policy in the cloned database refers to a table that is not present in the cloned database. To avoid this issue, the external table must be manually cloned or recreated in the cloned database4.
A row access policy can be applied to a view created on top of an external table. The policy can be applied to the view itself or to the underlying external table. However, if the policy is applied to the view, the view must be a secure view, which is a view that hides the underlying data and the view definition from unauthorized users5.
Reference: CREATE EXTERNAL TABLE | Snowflake Documentation ALTER EXTERNAL TABLE | Snowflake Documentation Understanding Row Access Policies | Snowflake Documentation Snowflake Data Governance: Row Access Policy Overview Secure Views | Snowflake Documentation
An Architect needs to allow a user to create a database from an inbound share.
To meet this requirement, the user’s role must have which privileges? (Choose two.)
- A . IMPORT SHARE;
- B . IMPORT PRIVILEGES;
- C . CREATE DATABASE;
- D . CREATE SHARE;
- E . IMPORT DATABASE;
C, E
Explanation:
According to the Snowflake documentation, to create a database from an inbound share, the user’s role must have the following privileges:
The CREATE DATABASE privilege on the current account. This privilege allows the user to create a new database in the account1.
The IMPORT DATABASE privilege on the share. This privilege allows the user to import a database from the share into the account2. The other privileges listed are not relevant for this requirement. The IMPORT SHARE privilege is used to import a share into the account, not a database3. The IMPORT PRIVILEGES privilege is used to import the privileges granted on the shared objects, not the objects themselves2. The CREATE SHARE privilege is used to create a share to provide data to other accounts, not to consume data from other accounts4.
Reference: CREATE DATABASE | Snowflake Documentation Importing Data from a Share | Snowflake Documentation Importing a Share | Snowflake Documentation CREATE SHARE | Snowflake Documentation
Files arrive in an external stage every 10 seconds from a proprietary system. The files range in size from 500 K to 3 MB. The data must be accessible by dashboards as soon as it arrives.
How can a Snowflake Architect meet this requirement with the LEAST amount of coding? (Choose two.)
- A . Use Snowpipe with auto-ingest.
- B . Use a COPY command with a task.
- C . Use a materialized view on an external table.
- D . Use the COPY INTO command.
- E . Use a combination of a task and a stream.
A, C
Explanation:
These two options are the best ways to meet the requirement of loading data from an external stage and making it accessible by dashboards with the least amount of coding.
Snowpipe with auto-ingest is a feature that enables continuous and automated data loading from an external stage into a Snowflake table. Snowpipe uses event notifications from the cloud storage service to detect new or modified files in the stage and triggers a COPY INTO command to load the data into the table. Snowpipe is efficient, scalable, and serverless, meaning it does not require any infrastructure or maintenance from the user. Snowpipe also supports loading data from files of any size, as long as they are in a supported format1.
A materialized view on an external table is a feature that enables creating a pre-computed result set from an external table and storing it in Snowflake. A materialized view can improve the performance and efficiency of querying data from an external table, especially for complex queries or dashboards. A materialized view can also support aggregations, joins, and filters on the external table data. A materialized view on an external table is automatically refreshed when the underlying data in the external stage changes, as long as the AUTO_REFRESH parameter is set to true2.
Reference: Snowpipe Overview | Snowflake Documentation
Materialized Views on External Tables | Snowflake Documentation
When loading data into a table that captures the load time in a column with a default value of either CURRENT_TIME () or CURRENT_TIMESTAMP() what will occur?
- A . All rows loaded using a specific COPY statement will have varying timestamps based on when the rows were inserted.
- B . Any rows loaded using a specific COPY statement will have varying timestamps based on when the rows were read from the source.
- C . Any rows loaded using a specific COPY statement will have varying timestamps based on when the rows were created in the source.
- D . All rows loaded using a specific COPY statement will have the same timestamp value.
D
Explanation:
According to the Snowflake documentation, when loading data into a table that captures the load time in a column with a default value of either CURRENT_TIME () or CURRENT_TIMESTAMP(), the default value is evaluated once per COPY statement, not once per row. Therefore, all rows loaded using a specific COPY statement will have the same timestamp value. This behavior ensures that the timestamp value reflects the time when the data was loaded into the table, not when the data was read from the source or created in the source.
Reference: Snowflake Documentation: Loading Data into Tables with Default Values
Snowflake Documentation: COPY INTO table
How does a standard virtual warehouse policy work in Snowflake?
- A . It conserves credits by keeping running clusters fully loaded rather than starting additional clusters.
- B . It starts only if the system estimates that there is a query load that will keep the cluster busy for at least 6 minutes.
- C . It starts only f the system estimates that there is a query load that will keep the cluster busy for at least 2 minutes.
- D . It prevents or minimizes queuing by starting additional clusters instead of conserving credits.
D
Explanation:
A standard virtual warehouse policy is one of the two scaling policies available for multi-cluster warehouses in Snowflake. The other policy is economic. A standard policy aims to prevent or minimize queuing by starting additional clusters as soon as the current cluster is fully loaded, regardless of the number of queries in the queue. This policy can improve query performance and concurrency, but it may also consume more credits than an economic policy, which tries to conserve credits by keeping the running clusters fully loaded before starting additional clusters. The scaling policy can be set when creating or modifying a warehouse, and it can be changed at any time.
Reference: Snowflake Documentation: Multi-cluster Warehouses
Snowflake Documentation: Scaling Policy for Multi-cluster Warehouses
Which feature provides the capability to define an alternate cluster key for a table with an existing cluster key?
- A . External table
- B . Materialized view
- C . Search optimization
- D . Result cache
B
Explanation:
A materialized view is a feature that provides the capability to define an alternate cluster key for a table with an existing cluster key. A materialized view is a pre-computed result set that is stored in Snowflake and can be queried like a regular table. A materialized view can have a different cluster key than the base table, which can improve the performance and efficiency of queries on the materialized view. A materialized view can also support aggregations, joins, and filters on the base table data. A materialized view is automatically refreshed when the underlying data in the base table changes, as long as the AUTO_REFRESH parameter is set to true1.
Reference: Materialized Views | Snowflake Documentation
An Architect would like to save quarter-end financial results for the previous six years.
Which Snowflake feature can the Architect use to accomplish this?
- A . Search optimization service
- B . Materialized view
- C . Time Travel
- D . Zero-copy cloning
- E . Secure views
D
Explanation:
Zero-copy cloning is a Snowflake feature that can be used to save quarter-end financial results for the previous six years. Zero-copy cloning allows creating a copy of a database, schema, table, or view without duplicating the data or metadata. The clone shares the same data files as the original object, but tracks any changes made to the clone or the original separately. Zero-copy cloning can be used to create snapshots of data at different points in time, such as quarter-end financial results, and preserve them for future analysis or comparison. Zero-copy cloning is fast, efficient, and does not consume any additional storage space unless the data is modified1.
Reference: Zero-Copy Cloning | Snowflake Documentation
A company is using a Snowflake account in Azure. The account has SAML SSO set up using ADFS as a SCIM identity provider.
To validate Private Link connectivity, an Architect performed the following steps:
* Confirmed Private Link URLs are working by logging in with a username/password account
* Verified DNS resolution by running nslookups against Private Link URLs
* Validated connectivity using SnowCD
* Disabled public access using a network policy set to use the company’s IP address range However, the following error message is received when using SSO to log into the company account: IP XX.XXX.XX.XX is not allowed to access snowflake. Contact your local security administrator.
What steps should the Architect take to resolve this error and ensure that the account is accessed using only Private Link? (Choose two.)
- A . Alter the Azure security integration to use the Private Link URLs.
- B . Add the IP address in the error message to the allowed list in the network policy.
- C . Generate a new SCIM access token using system$generate_scim_access_token and save it to Azure AD.
- D . Update the configuration of the Azure AD SSO to use the Private Link URLs.
- E . Open a case with Snowflake Support to authorize the Private Link URLs’ access to the account.
B, D
Explanation:
The error message indicates that the IP address in the error message is not allowed to access Snowflake because it is not in the allowed list of the network policy. The network policy is a feature that allows restricting access to Snowflake based on IP addresses or ranges.
To resolve this error, the Architect should take the following steps:
Add the IP address in the error message to the allowed list in the network policy. This will allow the IP address to access Snowflake using the Private Link URLs. Alternatively, the Architect can disable
the network policy if it is not required for security reasons.
Update the configuration of the Azure AD SSO to use the Private Link URLs. This will ensure that the SSO authentication process uses the Private Link URLs instead of the public URLs. The configuration can be updated by following the steps in the Azure documentation1.
These two steps should resolve the error and ensure that the account is accessed using only Private Link. The other options are not necessary or relevant for this scenario. Altering the Azure security integration to use the Private Link URLs is not required because the security integration is used for SCIM provisioning, not for SSO authentication. Generating a new SCIM access token using system$generate_scim_access_token and saving it to Azure AD is not required because the SCIM access token is used for SCIM provisioning, not for SSO authentication. Opening a case with Snowflake Support to authorize the Private Link URLs’ access to the account is not required because the authorization can be done by the account administrator using the SYSTEM$AUTHORIZE_PRIVATELINK function2.
Which steps are recommended best practices for prioritizing cluster keys in Snowflake? (Choose two.)
- A . Choose columns that are frequently used in join predicates.
- B . Choose lower cardinality columns to support clustering keys and cost effectiveness.
- C . Choose TIMESTAMP columns with nanoseconds for the highest number of unique rows.
- D . Choose cluster columns that are most actively used in selective filters.
- E . Choose cluster columns that are actively used in the GROUP BY clauses.
A, D
Explanation:
According to the Snowflake documentation, the best practices for choosing clustering keys are: Choose columns that are frequently used in join predicates. This can improve the join performance by reducing the number of micro-partitions that need to be scanned and joined.
Choose columns that are most actively used in selective filters. This can improve the scan efficiency by skipping micro-partitions that do not match the filter predicates.
Avoid using low cardinality columns, such as gender or country, as clustering keys. This can result in poor clustering and high maintenance costs.
Avoid using TIMESTAMP columns with nanoseconds, as they tend to have very high cardinality and low correlation with other columns. This can also result in poor clustering and high maintenance costs.
Avoid using columns with duplicate values or NULLs, as they can cause skew in the clustering and reduce the benefits of pruning.
Cluster on multiple columns if the queries use multiple filters or join predicates. This can increase the chances of pruning more micro-partitions and improve the compression ratio.
Clustering is not always useful, especially for small or medium-sized tables, or tables that are not
frequently queried or updated. Clustering can incur additional costs for initially clustering the data
and maintaining the clustering over time.
Reference: Clustering Keys & Clustered Tables | Snowflake Documentation [Considerations for Choosing Clustering for a Table | Snowflake Documentation]
Which Snowflake data modeling approach is designed for BI queries?
- A . 3NF
- B . Star schema
- C . Data Vault
- D . Snowflake schema
B
Explanation:
A star schema is a Snowflake data modeling approach that is designed for BI queries. A star schema is a type of dimensional modeling that organizes data into fact tables and dimension tables. A fact table contains the measures or metrics of the business process, such as sales amount, order quantity, or profit margin. A dimension table contains the attributes or descriptors of the business process, such as product name, customer name, or order date. A star schema is called so because it resembles a star, with one fact table in the center and multiple dimension tables radiating from it. A star schema can improve the performance and simplicity of BI queries by reducing the number of joins, providing fast access to aggregated data, and enabling intuitive query syntax. A star schema can also support various types of analysis, such as trend analysis, slice and dice, drill down, and roll up12.
Reference: Snowflake Documentation: Dimensional Modeling
Snowflake Documentation: Star Schema
How is the change of local time due to daylight savings time handled in Snowflake tasks? (Choose two.)
- A . A task scheduled in a UTC-based schedule will have no issues with the time changes.
- B . Task schedules can be designed to follow specified or local time zones to accommodate the time changes.
- C . A task will move to a suspended state during the daylight savings time change.
- D . A frequent task execution schedule like minutes may not cause a problem, but will affect the task history.
- E . A task schedule will follow only the specified time and will fail to handle lost or duplicated hours.
A, B
Explanation:
According to the Snowflake documentation1 and the web search results2, these two statements are true about how the change of local time due to daylight savings time is handled in Snowflake tasks. A task is a feature that allows scheduling and executing SQL statements or stored procedures in Snowflake. A task can be scheduled using a cron expression that specifies the frequency and time zone of the task execution.
A task scheduled in a UTC-based schedule will have no issues with the time changes. UTC is a universal time standard that does not observe daylight savings time. Therefore, a task that uses UTC as the time zone will run at the same time throughout the year, regardless of the local time changes1.
Task schedules can be designed to follow specified or local time zones to accommodate the time changes. Snowflake supports using any valid IANA time zone identifier in the cron expression for a task. This allows the task to run according to the local time of the specified time zone, which may include daylight savings time adjustments. For example, a task that uses Europe/London as the time zone will run one hour earlier or later when the local time switches between GMT and BST12.
Reference: Snowflake Documentation: Scheduling Tasks
Snowflake Community: Do the timezones used in scheduling tasks in Snowflake adhere to daylight savings?
An Architect needs to grant a group of ORDER_ADMIN users the ability to clean old data in an ORDERS table (deleting all records older than 5 years), without granting any privileges on the table. The group’s manager (ORDER_MANAGER) has full DELETE privileges on the table.
How can the ORDER_ADMIN role be enabled to perform this data cleanup, without needing the DELETE privilege held by the ORDER_MANAGER role?
- A . Create a stored procedure that runs with caller’s rights, including the appropriate "> 5 years" business logic, and grant USAGE on this procedure to ORDER_ADMIN. The ORDER_MANAGER role owns the procedure.
- B . Create a stored procedure that can be run using both caller’s and owner’s rights (allowing the user to specify which rights are used during execution), and grant USAGE on this procedure to ORDER_ADMIN. The ORDER_MANAGER role owns the procedure.
- C . Create a stored procedure that runs with owner’s rights, including the appropriate "> 5 years" business logic, and grant USAGE on this procedure to ORDER_ADMIN. The ORDER_MANAGER role owns the procedure.
- D . This scenario would actually not be possible in Snowflake C any user performing a DELETE on a table requires the DELETE privilege to be granted to the role they are using.
C
Explanation:
This is the correct answer because it allows the ORDER_ADMIN role to perform the data cleanup without needing the DELETE privilege on the ORDERS table. A stored procedure is a feature that allows scheduling and executing SQL statements or stored procedures in Snowflake. A stored procedure can run with either the caller’s rights or the owner’s rights. A caller’s rights stored procedure runs with the privileges of the role that called the stored procedure, while an owner’s rights stored procedure runs with the privileges of the role that created the stored procedure. By creating a stored procedure that runs with owner’s rights, the ORDER_MANAGER role can delegate the specific task of deleting old data to the ORDER_ADMIN role, without granting the ORDER_ADMIN role more general privileges on the ORDERS table. The stored procedure must include the appropriate business logic to delete only the records older than 5 years, and the ORDER_MANAGER role must grant the USAGE privilege on the stored procedure to the ORDER_ADMIN role. The ORDER_ADMIN role can then execute the stored procedure to perform the data cleanup12.
Reference: Snowflake Documentation: Stored Procedures
Snowflake Documentation: Understanding Caller’s Rights and Owner’s Rights Stored Procedures
A company’s daily Snowflake workload consists of a huge number of concurrent queries triggered between 9pm and 11pm. At the individual level, these queries are smaller statements that get completed within a short time period.
What configuration can the company’s Architect implement to enhance the performance of this workload? (Choose two.)
- A . Enable a multi-clustered virtual warehouse in maximized mode during the workload duration.
- B . Set the MAX_CONCURRENCY_LEVEL to a higher value than its default value of 8 at the virtual warehouse level.
- C . Increase the size of the virtual warehouse to size X-Large.
- D . Reduce the amount of data that is being processed through this workload.
- E . Set the connection timeout to a higher value than its default.
A, B
Explanation:
These two configuration options can enhance the performance of the workload that consists of a huge number of concurrent queries that are smaller and faster.
Enabling a multi-clustered virtual warehouse in maximized mode allows the warehouse to scale out automatically by adding more clusters as soon as the current cluster is fully loaded, regardless of the number of queries in the queue. This can improve the concurrency and throughput of the workload by minimizing or preventing queuing. The maximized mode is suitable for workloads that require high performance and low latency, and are less sensitive to credit consumption1.
Setting the MAX_CONCURRENCY_LEVEL to a higher value than its default value of 8 at the virtual warehouse level allows the warehouse to run more queries concurrently on each cluster. This can improve the utilization and efficiency of the warehouse resources, especially for smaller and faster queries that do not require a lot of processing power. The MAX_CONCURRENCY_LEVEL parameter can be set when creating or modifying a warehouse, and it can be changed at any time2.
Reference: Snowflake Documentation: Scaling Policy for Multi-cluster Warehouses
Snowflake Documentation: MAX_CONCURRENCY_LEVEL
Which system functions does Snowflake provide to monitor clustering information within a table (Choose two.)
- A . SYSTEM$CLUSTERING_INFORMATION
- B . SYSTEM$CLUSTERING_USAGE
- C . SYSTEM$CLUSTERING_DEPTH
- D . SYSTEM$CLUSTERING_KEYS
- E . SYSTEM$CLUSTERING_PERCENT
A, C
Explanation:
According to the Snowflake documentation, these two system functions are provided by Snowflake to monitor clustering information within a table. A system function is a type of function that allows executing actions or returning information about the system. A clustering key is a feature that allows organizing data across micro-partitions based on one or more columns in the table. Clustering can improve query performance by reducing the number of files to scan.
SYSTEM$CLUSTERING_INFORMATION is a system function that returns clustering information, including average clustering depth, for a table based on one or more columns in the table. The function takes a table name and an optional column name or expression as arguments, and returns a JSON string with the clustering information. The clustering information includes the cluster by keys, the total partition count, the total constant partition count, the average overlaps, and the average depth1.
SYSTEM$CLUSTERING_DEPTH is a system function that returns the clustering depth for a table based on one or more columns in the table. The function takes a table name and an optional column name or expression as arguments, and returns an integer value with the clustering depth. The clustering depth is the maximum number of overlapping micro-partitions for any micro-partition in the table. A lower clustering depth indicates a better clustering2.
Reference: SYSTEM$CLUSTERING_INFORMATION | Snowflake Documentation SYSTEM$CLUSTERING_DEPTH | Snowflake Documentation
A company has a table with that has corrupted data, named Data. The company wants to recover the data as it was 5 minutes ago using cloning and Time Travel.
What command will accomplish this?
- A . CREATE CLONE TABLE Recover_Data FROM Data AT(OFFSET => -60*5);
- B . CREATE CLONE Recover_Data FROM Data AT(OFFSET => -60*5);
- C . CREATE TABLE Recover_Data CLONE Data AT(OFFSET => -60*5);
- D . CREATE TABLE Recover Data CLONE Data AT(TIME => -60*5);
C
Explanation:
This is the correct command to create a clone of the table Data as it was 5 minutes ago using cloning and Time Travel. Cloning is a feature that allows creating a copy of a database, schema, table, or view without duplicating the data or metadata. Time Travel is a feature that enables accessing historical data (i.e. data that has been changed or deleted) at any point within a defined period.
To create a clone of a table at a point in time in the past, the syntax is:
CREATE TABLE <clone_name> CLONE <source_table> AT (OFFSET => <offset_in_seconds>);
The OFFSET parameter specifies the time difference in seconds from the present time. A negative value indicates a point in the past. For example, -60*5 means 5 minutes ago. Alternatively, the TIMESTAMP parameter can be used to specify an exact timestamp in the past. The clone will contain the data as it existed in the source table at the specified point in time12.
Reference: Snowflake Documentation: Cloning Objects
Snowflake Documentation: Cloning Objects at a Point in Time in the Past
A company has an inbound share set up with eight tables and five secure views. The company plans to make the share part of its production data pipelines.
Which actions can the company take with the inbound share? (Choose two.)
- A . Clone a table from a share.
- B . Grant modify permissions on the share.
- C . Create a table from the shared database.
- D . Create additional views inside the shared database.
- E . Create a table stream on the shared table.
A, D
Explanation:
These two actions are possible with an inbound share, according to the Snowflake documentation and the web search results. An inbound share is a share that is created by another Snowflake account (the provider) and imported into your account (the consumer). An inbound share allows you to access the data shared by the provider, but not to modify or delete it.
However, you can perform some actions with the inbound share, such as:
Clone a table from a share. You can create a copy of a table from an inbound share using the CREATE TABLE … CLONE statement. The clone will contain the same data and metadata as the original table, but it will be independent of the share. You can modify or delete the clone as you wish, but it will not reflect any changes made to the original table by the provider1.
Create additional views inside the shared database. You can create views on the tables or views from an inbound share using the CREATE VIEW statement. The views will be stored in the shared database, but they will be owned by your account. You can query the views as you would query any other view in your account, but you cannot modify or delete the underlying objects from the share2.
The other actions listed are not possible with an inbound share, because they would require modifying the share or the shared objects, which are read-only for the consumer. You cannot grant modify permissions on the share, create a table from the shared database, or create a table stream on the shared table34.
Reference: Cloning Objects from a Share | Snowflake Documentation Creating Views on Shared Data | Snowflake Documentation Importing Data from a Share | Snowflake Documentation Streams on Shared Tables | Snowflake Documentation
A company has several sites in different regions from which the company wants to ingest data.
Which of the following will enable this type of data ingestion?
- A . The company must have a Snowflake account in each cloud region to be able to ingest data to that account.
- B . The company must replicate data between Snowflake accounts.
- C . The company should provision a reader account to each site and ingest the data through the reader accounts.
- D . The company should use a storage integration for the external stage.
D
Explanation:
This is the correct answer because it allows the company to ingest data from different regions using a storage integration for the external stage. A storage integration is a feature that enables secure and easy access to files in external cloud storage from Snowflake. A storage integration can be used to create an external stage, which is a named location that references the files in the external storage. An external stage can be used to load data into Snowflake tables using the COPY INTO command, or to unload data from Snowflake tables using the COPY INTO LOCATION command. A storage integration can support multiple regions and cloud platforms, as long as the external storage service is compatible with Snowflake12.
Reference: Snowflake Documentation: Storage Integrations
Snowflake Documentation: External Stages
What Snowflake features should be leveraged when modeling using Data Vault?
- A . Snowflake’s support of multi-table inserts into the data model’s Data Vault tables
- B . Data needs to be pre-partitioned to obtain a superior data access performance
- C . Scaling up the virtual warehouses will support parallel processing of new source loads
- D . Snowflake’s ability to hash keys so that hash key joins can run faster than integer joins
A, C
Explanation:
These two features are relevant for modeling using Data Vault on Snowflake. Data Vault is a data modeling approach that organizes data into hubs, links, and satellites. Data Vault is designed to enable high scalability, flexibility, and performance for data integration and analytics. Snowflake is a cloud data platform that supports various data modeling techniques, including Data Vault. Snowflake provides some features that can enhance the Data Vault modeling, such as:
Snowflake’s support of multi-table inserts into the data model’s Data Vault tables. Multi-table inserts (MTI) are a feature that allows inserting data from a single query into multiple tables in a single DML statement. MTI can improve the performance and efficiency of loading data into Data Vault tables, especially for real-time or near-real-time data integration. MTI can also reduce the complexity and maintenance of the loading code, as well as the data duplication and latency12.
Scaling up the virtual warehouses will support parallel processing of new source loads. Virtual
warehouses are a feature that allows provisioning compute resources on demand for data
processing. Virtual warehouses can be scaled up or down by changing the size of the warehouse,
which determines the number of servers in the warehouse. Scaling up the virtual warehouses can
improve the performance and concurrency of processing new source loads into Data Vault tables,
especially for large or complex data sets. Scaling up the virtual warehouses can also leverage the
parallelism and distribution of Snowflake’s architecture, which can optimize the data loading and
querying34.
Reference: Snowflake Documentation: Multi-table Inserts
Snowflake Blog: Tips for Optimizing the Data Vault Architecture on Snowflake
Snowflake Documentation: Virtual Warehouses
Snowflake Blog: Building a Real-Time Data Vault in Snowflake
A company’s client application supports multiple authentication methods, and is using Okta.
What is the best practice recommendation for the order of priority when applications authenticate to Snowflake?
- A . 1) OAuth (either Snowflake OAuth or External OAuth)
2) External browser
3) Okta native authentication
4) Key Pair Authentication, mostly used for service account users
5) Password - B . 1) External browser, SSO
2) Key Pair Authentication, mostly used for development environment users
3) Okta native authentication
4) OAuth (ether Snowflake OAuth or External OAuth)
5) Password - C . 1) Okta native authentication
2) Key Pair Authentication, mostly used for production environment users
3) Password
4) OAuth (either Snowflake OAuth or External OAuth)
5) External browser, SSO - D . 1) Password
2) Key Pair Authentication, mostly used for production environment users
3) Okta native authentication
4) OAuth (either Snowflake OAuth or External OAuth)
5) External browser, SSO
A
Explanation:
This is the best practice recommendation for the order of priority when applications authenticate to Snowflake, according to the Snowflake documentation and the web search results. Authentication is the process of verifying the identity of a user or application that connects to Snowflake. Snowflake supports multiple authentication methods, each with different advantages and disadvantages.
The recommended order of priority is based on the following factors:
Security: The authentication method should provide a high level of security and protection against unauthorized access or data breaches. The authentication method should also support multi-factor authentication (MFA) or single sign-on (SSO) for additional security.
Convenience: The authentication method should provide a smooth and easy user experience, without requiring complex or manual steps. The authentication method should also support seamless integration with external identity providers or applications.
Flexibility: The authentication method should provide a range of options and features to suit different use cases and scenarios. The authentication method should also support customization and configuration to meet specific requirements.
Based on these factors, the recommended order of priority is:
OAuth (either Snowflake OAuth or External OAuth): OAuth is an open standard for authorization that allows applications to access Snowflake resources on behalf of a user, without exposing the user’s credentials. OAuth provides a high level of security, convenience, and flexibility, as it supports MFA, SSO, token-based authentication, and various grant types and scopes. OAuth can be implemented using either Snowflake OAuth or External OAuth, depending on the identity provider and the application12.
External browser: External browser is an authentication method that allows users to log in to Snowflake using a web browser and an external identity provider, such as Okta, Azure AD, or Ping Identity. External browser provides a high level of security and convenience, as it supports MFA, SSO, and federated authentication. External browser also provides a consistent user interface and experience across different platforms and devices34.
Okta native authentication: Okta native authentication is an authentication method that allows users to log in to Snowflake using Okta as the identity provider, without using a web browser. Okta native authentication provides a high level of security and convenience, as it supports MFA, SSO, and federated authentication. Okta native authentication also provides a native user interface and experience for Okta users, and supports various Okta features, such as password policies and user management56.
Key Pair Authentication: Key Pair Authentication is an authentication method that allows users to log in to Snowflake using a public-private key pair, without using a password. Key Pair Authentication provides a high level of security, as it relies on asymmetric encryption and digital signatures. Key Pair Authentication also provides a flexible and customizable authentication option, as it supports various key formats, algorithms, and expiration times. Key Pair Authentication is mostly used for service account users, such as applications or scripts that connect to Snowflake programmatically7.
Password: Password is the simplest and most basic authentication method that allows users to log in to Snowflake using a username and password. Password provides a low level of security, as it relies on symmetric encryption and is vulnerable to brute force attacks or phishing. Password also provides a low level of convenience and flexibility, as it requires manual input and management, and does not support MFA or SSO. Password is the least recommended authentication method, and should be used only as a last resort or for testing purposes .
Reference: Snowflake Documentation: Snowflake OAuth
Snowflake Documentation: External OAuth
Snowflake Documentation: External Browser Authentication
Snowflake Blog: How to Use External Browser Authentication with Snowflake
Snowflake Documentation: Okta Native Authentication
Snowflake Blog: How to Use Okta Native Authentication with Snowflake
Snowflake Documentation: Key Pair Authentication
[Snowflake Blog: How to Use Key Pair Authentication with Snowflake]
[Snowflake Documentation: Password Authentication]
[Snowflake Blog: How to Use Password Authentication with Snowflake]
What is a valid object hierarchy when building a Snowflake environment?
- A . Account –> Database –> Schema –> Warehouse
- B . Organization –> Account –> Database –> Schema –> Stage
- C . Account –> Schema > Table –> Stage
- D . Organization –> Account –> Stage –> Table –> View
B
Explanation:
This is the valid object hierarchy when building a Snowflake environment, according to the Snowflake documentation and the web search results. Snowflake is a cloud data platform that supports various types of objects, such as databases, schemas, tables, views, stages, warehouses, and more.
These objects are organized in a hierarchical structure, as follows:
Organization: An organization is the top-level entity that represents a group of Snowflake accounts that are related by business needs or ownership. An organization can have one or more accounts, and can enable features such as cross-account data sharing, billing and usage reporting, and single sign-on across accounts12.
Account: An account is the primary entity that represents a Snowflake customer. An account can have one or more databases, schemas, stages, warehouses, and other objects. An account can also have one or more users, roles, and security integrations. An account is associated with a specific cloud platform, region, and Snowflake edition34.
Database: A database is a logical grouping of schemas. A database can have one or more schemas, and can store structured, semi-structured, or unstructured data. A database can also have properties such as retention time, encryption, and ownership56.
Schema: A schema is a logical grouping of tables, views, stages, and other objects. A schema can have one or more objects, and can define the namespace and access control for the objects. A schema can also have properties such as ownership and default warehouse.
Stage: A stage is a named location that references the files in external or internal storage. A stage can be used to load data into Snowflake tables using the COPY INTO command, or to unload data from Snowflake tables using the COPY INTO LOCATION command. A stage can be created at the account, database, or schema level, and can have properties such as file format, encryption, and credentials. The other options listed are not valid object hierarchies, because they either omit or misplace some objects in the structure. For example, option A omits the organization level and places the warehouse under the schema level, which is incorrect. Option C omits the organization, account, and stage levels, and places the table under the schema level, which is incorrect. Option D omits the database level and places the stage and table under the account level, which is incorrect.
Reference: Snowflake Documentation: Organizations
Snowflake Blog: Introducing Organizations in Snowflake
Snowflake Documentation: Accounts
Snowflake Blog: Understanding Snowflake Account Structures
Snowflake Documentation: Databases
Snowflake Blog: How to Create a Database in Snowflake
[Snowflake Documentation: Schemas]
[Snowflake Blog: How to Create a Schema in Snowflake]
[Snowflake Documentation: Stages]
[Snowflake Blog: How to Use Stages in Snowflake]
Which of the following are characteristics of Snowflake’s parameter hierarchy?
- A . Session parameters override virtual warehouse parameters.
- B . Virtual warehouse parameters override user parameters.
- C . Table parameters override virtual warehouse parameters.
- D . Schema parameters override account parameters.
D
Explanation:
This is the correct answer because it reflects the characteristics of Snowflake’s parameter hierarchy. Snowflake provides three types of parameters that can be set for an account: account parameters, session parameters, and object parameters. All parameters have default values, which can be set and then overridden at different levels depending on the parameter type. The following diagram illustrates the hierarchical relationship between the different parameter types and how individual parameters can be overridden at each level1:
As shown in the diagram, schema parameters are a type of object parameters that can be set for schemas. Schema parameters can override the account parameters that are set at the account level. For example, the LOG_LEVEL parameter can be set at the account level to control the logging level for all objects in the account, but it can also be overridden at the schema level to control the logging level for specific stored procedures and UDFs in that schema2.
The other options listed are not correct because they do not reflect the characteristics of Snowflake’s parameter hierarchy. Session parameters do not override virtual warehouse parameters, because virtual warehouse parameters are a type of session parameters that can be set for virtual warehouses. Virtual warehouse parameters do not override user parameters, because user parameters are a type of session parameters that can be set for users. Table parameters do not override virtual warehouse parameters, because table parameters are a type of object parameters that can be set for tables, and object parameters do not affect session parameters1.
Reference: Snowflake Documentation: Parameters
Snowflake Documentation: Setting Log Level