
A company wants to move its Mule API implementations into production as quickly as possible. To protect access to all Mule application data and metadata, the company requires that all Mule applications be deployed to the company’s customer-hosted infrastructure within the corporate firewall .
What combination of runtime plane and control plane options meets these project lifecycle goals?
- A . Manually provisioned customer-hosted runtime plane and customer-hosted control plane
- B . MuleSoft-hosted runtime plane and customer-hosted control plane
- C . Manually provisioned customer-hosted runtime plane and MuleSoft-hosted control plane
- D . iPaaS provisioned customer-hosted runtime plane and MuleSoft-hosted control plane
A
Explanation:
Explanation
Correct Answer. Manually provisioned customer-hosted runtime plane and customer-
hosted control plane
*****************************************
There are two key factors that are to be taken into consideration from the scenario given in the question.
>> Company requires both data and metadata to be resided within the corporate firewall
>> Company would like to go with customer-hosted infrastructure.
Any deployment model that is to deal with the cloud directly or indirectly (Mulesoft-hosted or Customer’s own cloud like Azure, AWS) will have to share atleast the metadata. Application data can be controlled inside firewall by having Mule Runtimes on customer hosted runtime plane. But if we go with Mulsoft-hosted/ Cloud-based control plane, the control plane required atleast some minimum level of metadata to be sent outside the corporate firewall.
As the customer requirement is pretty clear about the data and metadata both to be within the corporate firewall, even though customer wants to move to production as quickly as possible, unfortunately due to the nature of their security requirements, they have no other option but to go with manually provisioned customer-hosted runtime plane and customer-hosted control plane.
What is a best practice when building System APIs?
- A . Document the API using an easily consumable asset like a RAML definition
- B . Model all API resources and methods to closely mimic the operations of the backend system
- C . Build an Enterprise Data Model (Canonical Data Model) for each backend system and apply it to System APIs
- D . Expose to API clients all technical details of the API implementation’s interaction wifch the backend system
B
Explanation:
Correct Answer. Model all API resources and methods to closely mimic the operations of the backend system.
*****************************************
>> There are NO fixed and straight best practices while opting data models for APIs. They are completly contextual and depends on number of factors. Based upon those factors, an enterprise can choose if they have to go with Enterprise Canonical Data Model or Bounded Context Model etc.
>> One should NEVER expose the technical details of API implementation to their API clients. Only the API interface/ RAML is exposed to API clients.
>> It is true that the RAML definitions of APIs should be as detailed as possible and should reflect most of the documentation. However, just that is NOT enough to call your API as best documented API. There should be even more documentation on Anypoint Exchange with API Notebooks etc. to make and create a developer friendly API and repository..
>> The best practice always when creating System APIs is to create their API interfaces by modeling their resources and methods to closely reflect the operations and functionalities of that backend system.
An organization uses various cloud-based SaaS systems and multiple on-premises systems. The on-premises systems are an important part of the organization’s application network and can only be accessed from within the organization’s intranet.
What is the best way to configure and use Anypoint Platform to support integrations with both the cloud-based SaaS systems and on-premises systems?
A) Use CloudHub-deployed Mule runtimes in an Anypoint VPC managed by Anypoint Platform Private Cloud Edition control plane
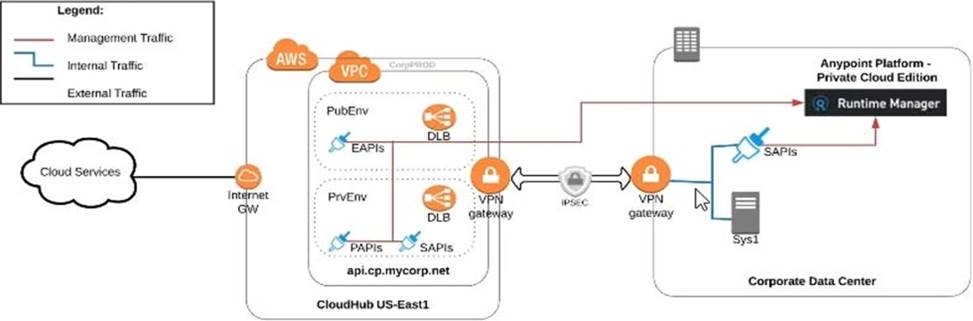

B) Use CloudHub-deployed Mule runtimes in the shared worker cloud managed by the MuleSoft-hosted Anypoint Platform control plane
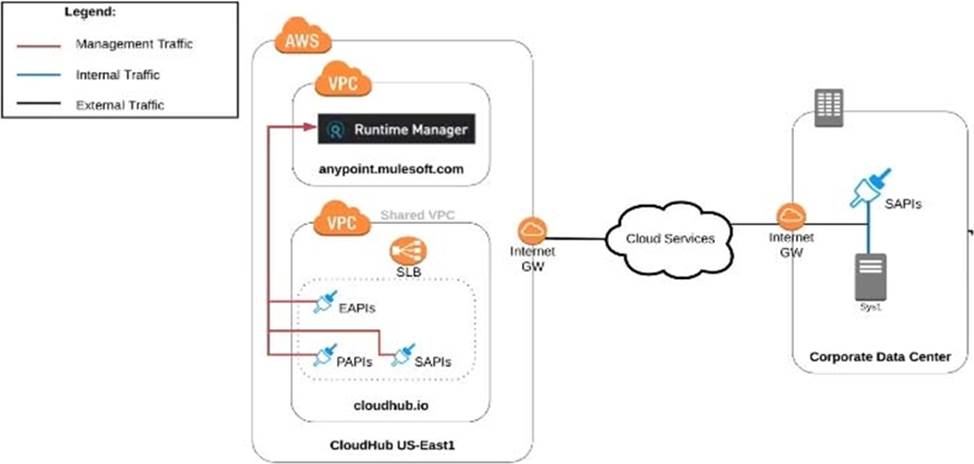

C) Use an on-premises installation of Mule runtimes that are completely isolated with NO external network access, managed by the Anypoint Platform Private Cloud Edition control plane
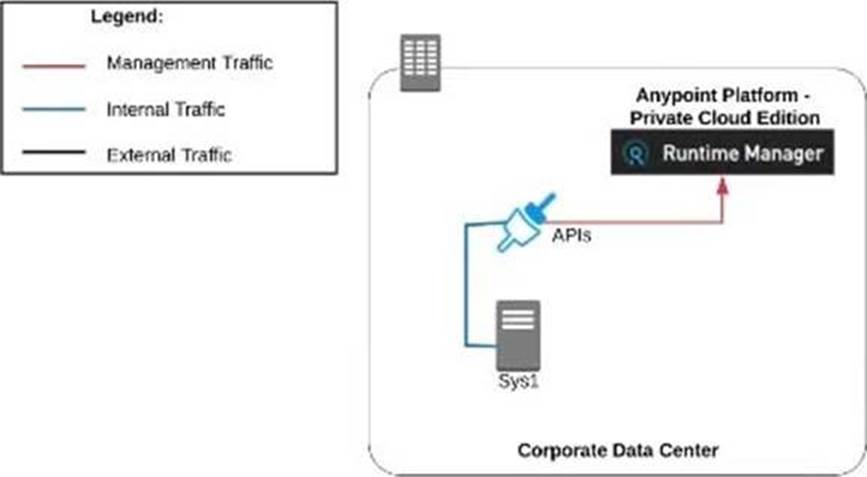

D) Use a combination of Cloud Hub-deployed and manually provisioned on-premises Mule runtimes managed by the MuleSoft-hosted Anypoint Platform control plane
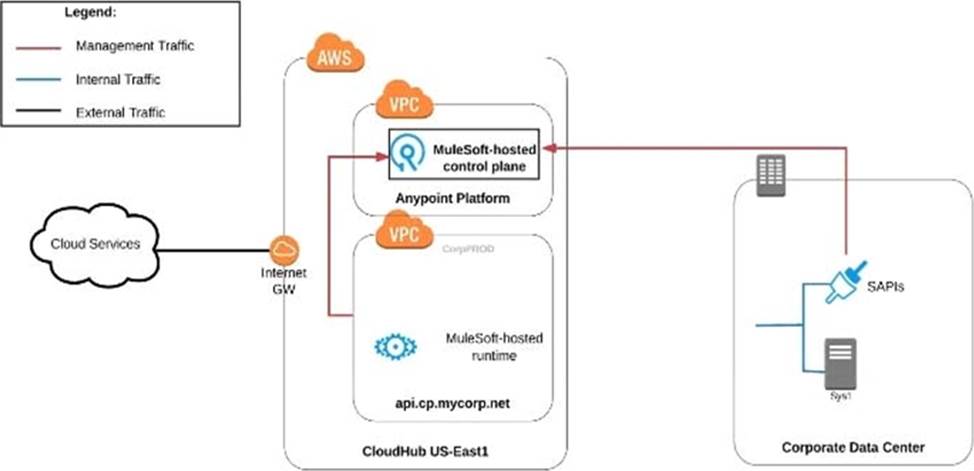

- A . Option A
- B . Option B
- C . Option C
- D . Option D
B
Explanation:
Correct Answer. Use a combination of CloudHub-deployed and manually provisioned on-premises Mule runtimes managed by the MuleSoft-hosted Platform control plane.
*****************************************
Key details to be taken from the given scenario:
>> Organization uses BOTH cloud-based and on-premises systems
>> On-premises systems can only be accessed from within the organization’s intranet Let us evaluate the given choices based on above key details:
>> CloudHub-deployed Mule runtimes can ONLY be controlled using MuleSoft-hosted
control plane. We CANNOT use Private Cloud Edition’s control plane to control CloudHub Mule Runtimes. So, option suggesting this is INVALID
>> Using CloudHub-deployed Mule runtimes in the shared worker cloud managed by the MuleSoft-hosted Anypoint Platform is completely IRRELEVANT to given scenario and silly choice. So, option suggesting this is INVALID
>> Using an on-premises installation of Mule runtimes that are completely isolated with NO external network access, managed by the Anypoint Platform Private Cloud Edition control
plane would work for On-premises integrations. However, with NO external access, integrations cannot be done to SaaS-based apps. Moreover CloudHub-hosted apps are best-fit for integrating with SaaS-based applications. So, option suggesting this is BEST WAY.
The best way to configure and use Anypoint Platform to support these mixed/hybrid integrations is to use a combination of CloudHub-deployed and manually provisioned on-premises Mule runtimes managed by the MuleSoft-hosted Platform control plane.
An organization has implemented a Customer Address API to retrieve customer address information. This API has been deployed to multiple environments and has been configured to enforce client IDs everywhere.
A developer is writing a client application to allow a user to update their address. The developer has found the Customer Address API in Anypoint Exchange and wants to use it in their client application.
What step of gaining access to the API can be performed automatically by Anypoint Platform?
- A . Approve the client application request for the chosen SLA tier
- B . Request access to the appropriate API Instances deployed to multiple environments using the client application’s credentials
- C . Modify the client application to call the API using the client application’s credentials
- D . Create a new application in Anypoint Exchange for requesting access to the API
A
Explanation:
Correct Answer. Approve the client application request for the chosen SLA tier
*****************************************
>> Only approving the client application request for the chosen SLA tier can be automated
>> Rest of the provided options are not valid
Reference: https://docs.mulesoft.com/api-manager/2.x/defining-sla-tiers#defining-a-tier
What is a key requirement when using an external Identity Provider for Client Management in Anypoint Platform?
- A . Single sign-on is required to sign in to Anypoint Platform
- B . The application network must include System APIs that interact with the Identity Provider
- C . To invoke OAuth 2.0-protected APIs managed by Anypoint Platform, API clients must submit access tokens issued by that same Identity Provider
- D . APIs managed by Anypoint Platform must be protected by SAML 2.0 policies
C
Explanation:
https://www.folkstalk.com/2019/11/mulesoft-integration-and-platform.html
Correct Answer. To invoke OAuth 2.0-protected APIs managed by Anypoint Platform, API clients must submit access tokens issued by that same Identity Provider
*****************************************
>> It is NOT necessary that single sign-on is required to sign in to Anypoint Platform because we are using an external Identity Provider for Client Management
>> It is NOT necessary that all APIs managed by Anypoint Platform must be protected by SAML 2.0 policies because we are using an external Identity Provider for Client Management
>> Not TRUE that the application network must include System APIs that interact with the Identity Provider because we are using an external Identity Provider for Client Management Only TRUE statement in the given options is – "To invoke OAuth 2.0-protected APIs managed by Anypoint Platform, API clients must submit access tokens issued by that same Identity Provider"
References:
https://docs.mulesoft.com/api-manager/2.x/external-oauth-2.0-token-validation-policy https://blogs.mulesoft.com/dev/api-dev/api-security-ways-to-authenticate-and-authorize/
Which of the following best fits the definition of API-led connectivity?
- A . API-led connectivity is not just an architecture or technology but also a way to organize people and processes for efficient IT delivery in the organization
- B . API-led connectivity is a 3-layered architecture covering Experience, Process and System layers
- C . API-led connectivity is a technology which enabled us to implement Experience, Process and System layer based APIs
A
Explanation:
Correct Answer. API-led connectivity is not just an architecture or technology but also a way to organize people and processes for efficient IT delivery in the organization.
*****************************************
Reference: https://blogs.mulesoft.com/dev/api-dev/what-is-api-led-connectivity/
An organization wants MuleSoft-hosted runtime plane features (such as HTTP load balancing, zero downtime, and horizontal and vertical scaling) in its Azure environment .
What runtime plane minimizes the organization’s effort to achieve these features?
- A . Anypoint Runtime Fabric
- B . Anypoint Platform for Pivotal Cloud Foundry
- C . CloudHub
- D . A hybrid combination of customer-hosted and MuleSoft-hosted Mule runtimes
A
Explanation:
Correct Answer. Anypoint Runtime Fabric
*****************************************
>> When a customer is already having an Azure environment, It is not at all an ideal approach to go with hybrid model having some M
t-hosted Runtime plane and is on AWS. We cannot customize to point CloudHub to customerule Runtimes hosted on Azure and some on MuleSoft. This is unnecessary and useless.
>> CloudHub is a Mulesof’s Azure environment.
>> Anypoint Platform for Pivotal Cloud Foundry is specifically for infrastructure provided by Pivotal Cloud Foundry
>> Anypoint Runtime Fabric is right answer as it is a container service that automates the deployment and orchestration of Mule applications and API gateways. Runtime Fabric runs within a customer-managed infrastructure on AWS, Azure, virtual machines (VMs), and bare-metal servers.
-Some of the capabilities of Anypoint Runtime Fabric include:
-Isolation between applications by running a separate Mule runtime per application.
-Ability to run multiple versions of Mule runtime on the same set of resources.
-Scaling applications across multiple replicas.
-Automated application fail-over.
-Application management with Anypoint Runtime Manager.
Reference: https://docs.mulesoft.com/runtime-fabric/1.7/
What is a key performance indicator (KPI) that measures the success of a typical C4E that is immediately apparent in responses from the Anypoint Platform APIs?
- A . The number of production outage incidents reported in the last 24 hours
- B . The number of API implementations that have a publicly accessible HTTP endpoint and are being managed by Anypoint Platform
- C . The fraction of API implementations deployed manually relative to those deployed using a CI/CD tool
- D . The number of API specifications in RAML or OAS format published to Anypoint Exchange
D
Explanation:
Correct Answer. The number of API specifications in RAML or OAS format published to
Anypoint Exchange
*****************************************
>> The success of C4E always depends on their contribution to the number of reusable assets that they have helped to build and publish to Anypoint Exchange.
>> It is NOT due to any factors w.r.t # of outages, Manual vs CI/CD deployments or Publicly accessible HTTP endpoints
>> Anypoint Platform APIs helps us to quickly run and get the number of published RAML/OAS assets to Anypoint Exchange. This clearly depicts how successful a C4E team
is based on number of returned assets in the response.
Reference: https://help.mulesoft.com/s/question/0D52T00004mXSTUSA4/how-should-a-company-measure-c4e-success
An organization has created an API-led architecture that uses various API layers to integrate mobile clients with a backend system. The backend system consists of a number
of specialized components and can be accessed via a REST API. The process and experience APIs share the same bounded-context model that is different from the backend data model .
What additional canonical models, bounded-context models, or anti-corruption layers are best added to this architecture to help process data consumed from the backend system?
- A . Create a bounded-context model for every layer and overlap them when the boundary contexts overlap, letting API developers know about the differences between upstream and downstream data models
- B . Create a canonical model that combines the backend and API-led models to simplify and unify data models, and minimize data transformations.
- C . Create a bounded-context model for the system layer to closely match the backend data model, and add an anti-corruption layer to let the different bounded contexts cooperate across the system and process layers
- D . Create an anti-corruption layer for every API to perform transformation for every data model to match each other, and let data simply travel between APIs to avoid the complexity and overhead of building canonical models
C
Explanation:
Correct Answer. Create a bounded-context model for the system layer to closely match the backend data model, and add an anti-corruption layer to let the different bounded contexts cooperate across the system and process layers
*****************************************
>> Canonical models are not an option here as the organization has already put in efforts and created bounded-context models for Experience and Process APIs.
>> Anti-corruption layers for ALL APIs is unnecessary and invalid because it is mentioned that experience and process APIs share same bounded-context model. It is just the System layer APIs that need to choose their approach now.
>> So, having an anti-corruption layer just between the process and system layers will work well. Also to speed up the approach, system APIs can mimic the backend system data model.
What is true about automating interactions with Anypoint Platform using tools such as Anypoint Platform REST APIs, Anypoint CU, or the Mule Maven plugin?
- A . Access to Anypoint Platform APIs and Anypoint CU can be controlled separately through the roles and permissions in Anypoint Platform, so that specific users can get access to Anypoint CLI white others get access to the platform APIs
- B . Anypoint Platform APIs can ONLY automate interactions with CloudHub, while the Mule Maven plugin is required for deployment to customer-hosted Mule runtimes
- C . By default, the Anypoint CLI and Mule Maven plugin are NOT included in the Mule runtime, so are NOT available to be used by deployed Mule applications
- D . API policies can be applied to the Anypoint Platform APIs so that ONLY certain LOBs have access to specific functions
C
Explanation:
Correct Answer. By default, the Anypoint CLI and Mule Maven plugin are NOT included in the Mule runtime, so are NOT available to be used by deployed Mule applications *****************************************
>> We CANNOT apply API policies to the Anypoint Platform APIs like we can do on our custom written API instances. So, option suggesting this is FALSE.
>> Anypoint Platform APIs can be used for automating interactions with both CloudHub and customer-hosted Mule runtimes. Not JUST the CloudHub. So, option opposing this is FALSE.
>> Mule Maven plugin is NOT mandatory for deployment to customer-hosted Mule runtimes. It just helps your CI/CD to have smoother automation. But not a compulsory requirement to deploy. So, option opposing this is FALSE.
>> We DO NOT have any such special roles and permissions on the platform to separately control access for some users to have Anypoint CLI and others to have Anypoint Platform APIs. With proper general roles/permissions (API Owner, Cloudhub Admin etc..), one can use any of the options (Anypoint CLI or Platform APIs). So, option suggesting this is
FALSE.
Only TRUE statement given in the choices is that – Anypoint CLI and Mule Maven plugin are NOT included in the Mule runtime, so are NOT available to be used by deployed Mule applications.
Maven is part of Studio or you can use other Maven installation for development. CLI is convenience only. It is one of many ways how to install app to the runtime.
These are definitely NOT part of anything except your process of deployment or automation.
What is a typical result of using a fine-grained rather than a coarse-grained API deployment model to implement a given business process?
- A . A decrease in the number of connections within the application network supporting the business process
- B . A higher number of discoverable API-related assets in the application network
- C . A better response time for the end user as a result of the APIs being smaller in scope and complexity
- D . An overall tower usage of resources because each fine-grained API consumes less resources
B
Explanation:
Correct Answer. A higher number of discoverable API-related assets in the application network.
*****************************************
>> We do NOT get faster response times in fine-grained approach when compared to coarse-grained approach.
>> In fact, we get faster response times from a network having coarse-grained APIs compared to a network having fine-grained APIs model. The reasons are below. Fine-grained approach:
What is a typical result of using a fine-grained rather than a coarse-grained API deployment model to implement a given business process?
- A . A decrease in the number of connections within the application network supporting the business process
- B . A higher number of discoverable API-related assets in the application network
- C . A better response time for the end user as a result of the APIs being smaller in scope and complexity
- D . An overall tower usage of resources because each fine-grained API consumes less resources
B
Explanation:
Correct Answer. A higher number of discoverable API-related assets in the application network.
*****************************************
>> We do NOT get faster response times in fine-grained approach when compared to coarse-grained approach.
>> In fact, we get faster response times from a network having coarse-grained APIs compared to a network having fine-grained APIs model. The reasons are below. Fine-grained approach:
What is a typical result of using a fine-grained rather than a coarse-grained API deployment model to implement a given business process?
- A . A decrease in the number of connections within the application network supporting the business process
- B . A higher number of discoverable API-related assets in the application network
- C . A better response time for the end user as a result of the APIs being smaller in scope and complexity
- D . An overall tower usage of resources because each fine-grained API consumes less resources
B
Explanation:
Correct Answer. A higher number of discoverable API-related assets in the application network.
*****************************************
>> We do NOT get faster response times in fine-grained approach when compared to coarse-grained approach.
>> In fact, we get faster response times from a network having coarse-grained APIs compared to a network having fine-grained APIs model. The reasons are below. Fine-grained approach:
What is a typical result of using a fine-grained rather than a coarse-grained API deployment model to implement a given business process?
- A . A decrease in the number of connections within the application network supporting the business process
- B . A higher number of discoverable API-related assets in the application network
- C . A better response time for the end user as a result of the APIs being smaller in scope and complexity
- D . An overall tower usage of resources because each fine-grained API consumes less resources
B
Explanation:
Correct Answer. A higher number of discoverable API-related assets in the application network.
*****************************************
>> We do NOT get faster response times in fine-grained approach when compared to coarse-grained approach.
>> In fact, we get faster response times from a network having coarse-grained APIs compared to a network having fine-grained APIs model. The reasons are below. Fine-grained approach:
What is a typical result of using a fine-grained rather than a coarse-grained API deployment model to implement a given business process?
- A . A decrease in the number of connections within the application network supporting the business process
- B . A higher number of discoverable API-related assets in the application network
- C . A better response time for the end user as a result of the APIs being smaller in scope and complexity
- D . An overall tower usage of resources because each fine-grained API consumes less resources
B
Explanation:
Correct Answer. A higher number of discoverable API-related assets in the application network.
*****************************************
>> We do NOT get faster response times in fine-grained approach when compared to coarse-grained approach.
>> In fact, we get faster response times from a network having coarse-grained APIs compared to a network having fine-grained APIs model. The reasons are below. Fine-grained approach:
What is a typical result of using a fine-grained rather than a coarse-grained API deployment model to implement a given business process?
- A . A decrease in the number of connections within the application network supporting the business process
- B . A higher number of discoverable API-related assets in the application network
- C . A better response time for the end user as a result of the APIs being smaller in scope and complexity
- D . An overall tower usage of resources because each fine-grained API consumes less resources
B
Explanation:
Correct Answer. A higher number of discoverable API-related assets in the application network.
*****************************************
>> We do NOT get faster response times in fine-grained approach when compared to coarse-grained approach.
>> In fact, we get faster response times from a network having coarse-grained APIs compared to a network having fine-grained APIs model. The reasons are below. Fine-grained approach:
How can the application of a rate limiting API policy be accurately reflected in the RAML definition of an API?
- A . By refining the resource definitions by adding a description of the rate limiting policy behavior
- B . By refining the request definitions by adding a remaining Requests query parameter with description, type, and example
- C . By refining the response definitions by adding the out-of-the-box Anypoint Platform rate-limit-enforcement securityScheme with description, type, and example
- D . By refining the response definitions by adding the x-ratelimit-* response headers with description, type, and example
D
Explanation:
Correct Answer. By refining the response definitions by adding the x-ratelimit-* response headers with description, type, and example
*****************************************
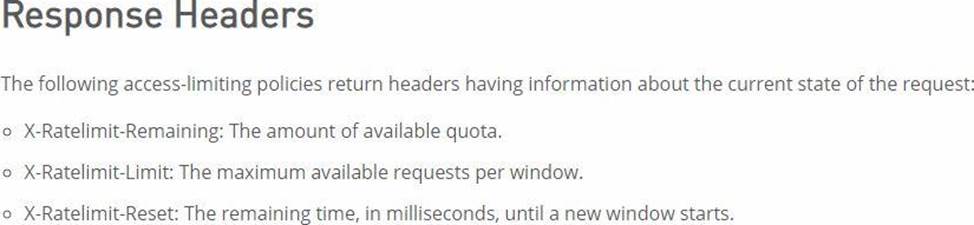

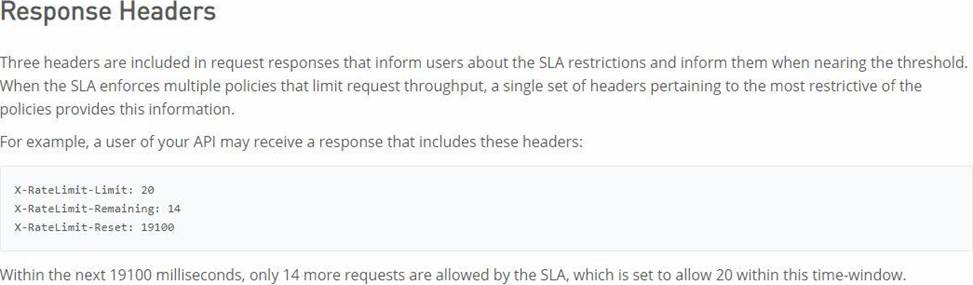

References:
https://docs.mulesoft.com/api-manager/2.x/rate-limiting-and-throttling#response-headers
https://docs.mulesoft.com/api-manager/2.x/rate-limiting-and-throttling-sla-based-policies#response-headers
What do the API invocation metrics provided by Anypoint Platform provide?
- A . ROI metrics from APIs that can be directly shared with business users
- B . Measurements of the effectiveness of the application network based on the level of reuse
- C . Data on past API invocations to help identify anomalies and usage patterns across various APIs
- D . Proactive identification of likely future policy violations that exceed a given threat threshold
C
Explanation:
Correct Answer. Data on past API invocations to help identify anomalies and usage
patterns across various APIs
*****************************************
API Invocation metrics provided by Anypoint Platform:
>> Does NOT provide any Return Of Investment (ROI) related information. So the option suggesting it is OUT.
>> Does NOT provide any information w.r.t how APIs are reused, whether there is effective usage of APIs or not etc…
>> Does NOT prodive any prediction information as such to help us proactively identify any future policy violations.
So, the kind of data/information we can get from such metrics is on past API invocations to
help identify anomalies and usage patterns across various APIs.
Reference: https://usermanual.wiki/Document/APAAppNetstudentManual02may2018.991784750.pdf
What is most likely NOT a characteristic of an integration test for a REST API implementation?
- A . The test needs all source and/or target systems configured and accessible
- B . The test runs immediately after the Mule application has been compiled and packaged
- C . The test is triggered by an external HTTP request
- D . The test prepares a known request payload and validates the response payload
B
Explanation:
Correct Answer. The test runs immediately after the Mule application has been compiled and packaged
*****************************************
>> Integration tests are the last layer of tests we need to add to be fully covered.
>> These tests actually run against Mule running with your full configuration in place and are tested from external source as they work in PROD.
>> These tests exercise the application as a whole with actual transports enabled. So, external systems are affected when these tests run.
So, these tests do NOT run immediately after the Mule application has been compiled and packaged.
FYI… Unit Tests are the one that run immediately after the Mule application has been compiled and packaged.
Reference: https://docs.mulesoft.com/mule-runtime/3.9/testing-strategies#integration-testing
What API policy would LEAST likely be applied to a Process API?
- A . Custom circuit breaker
- B . Client ID enforcement
- C . Rate limiting
- D . JSON threat protection
D
Explanation:
Correct Answer. JSON threat protection
*****************************************
Fact: Technically, there are no restrictions on what policy can be applied in what layer. Any policy can be applied on any layer API. However, context should also be considered properly before blindly applying the policies on APIs.
That is why, this question asked for a policy that would LEAST likely be applied to a Process API.
From the given options:
>> All policies except "JSON threat protection" can be applied without hesitation to the APIs in Process tier.
>> JSON threat protection policy ideally fits for experience APIs to prevent suspicious JSON payload coming from external API clients. This covers more of a security aspect by trying to avoid possibly malicious and harmful JSON payloads from external clients calling experience APIs.
As external API clients are NEVER allowed to call Process APIs directly and also these kind of malicious and harmful JSON payloads are always stopped at experience API layer only using this policy, it is LEAST LIKELY that this same policy is again applied on Process
Layer API.
Reference: https://docs.mulesoft.com/api-manager/2.x/policy-mule3-provided-policies
An organization has several APIs that accept JSON data over HTTP POST. The APIs are all publicly available and are associated with several mobile applications and web applications.
The organization does NOT want to use any authentication or compliance policies for these APIs, but at the same time, is worried that some bad actor could send payloads that could somehow compromise the applications or servers running the API implementations.
What out-of-the-box Anypoint Platform policy can address exposure to this threat?
- A . Shut out bad actors by using HTTPS mutual authentication for all API invocations
- B . Apply an IP blacklist policy to all APIs; the blacklist will Include all bad actors
- C . Apply a Header injection and removal policy that detects the malicious data before it is used
- D . Apply a JSON threat protection policy to all APIs to detect potential threat vectors
D
Explanation:
Correct Answer. Apply a JSON threat protection policy to all APIs to detect potential threat vectors
*****************************************
>> Usually, if the APIs are designed and developed for specific consumers (known consumers/customers) then we would IP Whitelist the same to ensure that traffic only comes from them.
>> However, as this scenario states that the APIs are publicly available and being used by so many mobile and web applications, it is NOT possible to identify and blacklist all possible bad actors.
>> So, JSON threat protection policy is the best chance to prevent any bad JSON payloads from such bad actors.
The implementation of a Process API must change.
What is a valid approach that minimizes the impact of this change on API clients?
- A . Update the RAML definition of the current Process API and notify API client developers by sending them links to the updated RAML definition
- B . Postpone changes until API consumers acknowledge they are ready to migrate to a new Process API or API version
- C . Implement required changes to the Process API implementation so that whenever possible, the Process API’s RAML definition remains unchanged
- D . Implement the Process API changes in a new API implementation, and have the old API implementation return an HTTP status code 301 – Moved Permanently to inform API clients they should be calling the new API implementation
C
Explanation:
Correct Answer. Implement required changes to the Process API implementation so that, whenever possible, the Process API’s RAML definition remains unchanged.
*****************************************
Key requirement in the question is:
>> Approach that minimizes the impact of this change on API clients Based on above:
>> Updating the RAML definition would possibly impact the API clients if the changes require any thing mandatory from client side. So, one should try to avoid doing that until really necessary.
>> Implementing the changes as a completely different API and then redirectly the clients with 3xx status code is really upsetting design and heavily impacts the API clients.
>> Organisations and IT cannot simply postpone the changes required until all API consumers acknowledge they are ready to migrate to a new Process API or API version. This is unrealistic and not possible.
The best way to handle the changes always is to implement required changes to the API implementations so that, whenever possible, the API’s RAML definition remains unchanged.
What condition requires using a CloudHub Dedicated Load Balancer?
- A . When cross-region load balancing is required between separate deployments of the same Mule application
- B . When custom DNS names are required for API implementations deployed to customer-hosted Mule runtimes
- C . When API invocations across multiple CloudHub workers must be load balanced
- D . When server-side load-balanced TLS mutual authentication is required between API implementations and API clients
D
Explanation:
Correct Answer. When server-side load-balanced TLS mutual authentication is required between API implementations and API clients
*****************************************
Fact/ Memory Tip: Although there are many benefits of CloudHub Dedicated Load balancer, TWO important things that should come to ones mind for considering it are:
>> Having URL endpoints with Custom DNS names on CloudHub deployed apps
>> Configuring custom certificates for both HTTPS and Two-way (Mutual) authentication. Coming to the options provided for this question:
>> We CANNOT use DLB to perform cross-region load balancing between separate deployments of the same Mule application.
>> We can have mapping rules to have more than one DLB URL pointing to same Mule app. But vicevera (More than one Mule app having same DLB URL) is NOT POSSIBLE
>> It is true that DLB helps to setup custom DNS names for Cloudhub deployed Mule apps but NOT true for apps deployed to Customer-hosted Mule Runtimes.
>> It is true to that we can load balance API invocations across multiple CloudHub workers using DLB but it is NOT A MUST. We can achieve the same (load balancing) using SLB (Shared Load Balancer) too. We DO NOT necessarily require DLB for achieve it.
So the only right option that fits the scenario and requires us to use DLB is when TLS mutual authentication is required between API implementations and API clients.
Reference: https://docs.mulesoft.com/runtime-manager/cloudhub-dedicated-load-balancer
When designing an upstream API and its implementation, the development team has been advised to NOT set timeouts when invoking a downstream API, because that downstream API has no SLA that can be relied upon. This is the only downstream API dependency of that upstream API.
Assume the downstream API runs uninterrupted without crashing .
What is the impact of this advice?
- A . An SLA for the upstream API CANNOT be provided
- B . The invocation of the downstream API will run to completion without timing out
- C . A default timeout of 500 ms will automatically be applied by the Mule runtime in which the upstream API implementation executes
- D . A toad-dependent timeout of less than 1000 ms will be applied by the Mule runtime in which the downstream API implementation executes
A
Explanation:
Correct Answer. An SLA for the upstream API CANNOT be provided.
*****************************************
>> First thing first, the default HTTP response timeout for HTTP connector is 10000 ms (10 seconds). NOT 500 ms.
>> Mule runtime does NOT apply any such "load-dependent" timeouts. There is no such behavior currently in Mule.
>> As there is default 10000 ms time out for HTTP connector, we CANNOT always guarantee that the invocation of the downstream API will run to completion without timing out due to its unreliable SLA times. If the response time crosses 10 seconds then the request may time out.
The main impact due to this is that a proper SLA for the upstream API CANNOT be provided.
Reference: https://docs.mulesoft.com/http-connector/1.5/http-documentation#parameters-3
An organization wants to make sure only known partners can invoke the organization’s APIs. To achieve this security goal, the organization wants to enforce a Client ID Enforcement policy in API Manager so that only registered partner applications can invoke the organization’s APIs.
In what type of API implementation does MuleSoft recommend adding an API proxy to enforce the Client ID Enforcement policy, rather than embedding the policy directly in the application’s JVM?
- A . A Mule 3 application using APIkit
- B . A Mule 3 or Mule 4 application modified with custom Java code
- C . A Mule 4 application with an API specification
- D . A Non-Mule application
D
Explanation:
Correct Answer. A Non-Mule application
*****************************************
>> All type of Mule applications (Mule 3/ Mule 4/ with APIkit/ with Custom Java Code etc) running on Mule Runtimes support the Embedded Policy Enforcement on them.
>> The only option that cannot have or does not support embedded policy enforcement and must have API Proxy is for Non-Mule Applications.
So, Non-Mule application is the right answer.
An organization wants to make sure only known partners can invoke the organization’s APIs. To achieve this security goal, the organization wants to enforce a Client ID Enforcement policy in API Manager so that only registered partner applications can invoke the organization’s APIs.
In what type of API implementation does MuleSoft recommend adding an API proxy to enforce the Client ID Enforcement policy, rather than embedding the policy directly in the application’s JVM?
- A . A Mule 3 application using APIkit
- B . A Mule 3 or Mule 4 application modified with custom Java code
- C . A Mule 4 application with an API specification
- D . A Non-Mule application
D
Explanation:
Correct Answer. A Non-Mule application
*****************************************
>> All type of Mule applications (Mule 3/ Mule 4/ with APIkit/ with Custom Java Code etc) running on Mule Runtimes support the Embedded Policy Enforcement on them.
>> The only option that cannot have or does not support embedded policy enforcement and must have API Proxy is for Non-Mule Applications.
So, Non-Mule application is the right answer.
An organization wants to make sure only known partners can invoke the organization’s APIs. To achieve this security goal, the organization wants to enforce a Client ID Enforcement policy in API Manager so that only registered partner applications can invoke the organization’s APIs.
In what type of API implementation does MuleSoft recommend adding an API proxy to enforce the Client ID Enforcement policy, rather than embedding the policy directly in the application’s JVM?
- A . A Mule 3 application using APIkit
- B . A Mule 3 or Mule 4 application modified with custom Java code
- C . A Mule 4 application with an API specification
- D . A Non-Mule application
D
Explanation:
Correct Answer. A Non-Mule application
*****************************************
>> All type of Mule applications (Mule 3/ Mule 4/ with APIkit/ with Custom Java Code etc) running on Mule Runtimes support the Embedded Policy Enforcement on them.
>> The only option that cannot have or does not support embedded policy enforcement and must have API Proxy is for Non-Mule Applications.
So, Non-Mule application is the right answer.
An organization wants to make sure only known partners can invoke the organization’s APIs. To achieve this security goal, the organization wants to enforce a Client ID Enforcement policy in API Manager so that only registered partner applications can invoke the organization’s APIs.
In what type of API implementation does MuleSoft recommend adding an API proxy to enforce the Client ID Enforcement policy, rather than embedding the policy directly in the application’s JVM?
- A . A Mule 3 application using APIkit
- B . A Mule 3 or Mule 4 application modified with custom Java code
- C . A Mule 4 application with an API specification
- D . A Non-Mule application
D
Explanation:
Correct Answer. A Non-Mule application
*****************************************
>> All type of Mule applications (Mule 3/ Mule 4/ with APIkit/ with Custom Java Code etc) running on Mule Runtimes support the Embedded Policy Enforcement on them.
>> The only option that cannot have or does not support embedded policy enforcement and must have API Proxy is for Non-Mule Applications.
So, Non-Mule application is the right answer.
An organization wants to make sure only known partners can invoke the organization’s APIs. To achieve this security goal, the organization wants to enforce a Client ID Enforcement policy in API Manager so that only registered partner applications can invoke the organization’s APIs.
In what type of API implementation does MuleSoft recommend adding an API proxy to enforce the Client ID Enforcement policy, rather than embedding the policy directly in the application’s JVM?
- A . A Mule 3 application using APIkit
- B . A Mule 3 or Mule 4 application modified with custom Java code
- C . A Mule 4 application with an API specification
- D . A Non-Mule application
D
Explanation:
Correct Answer. A Non-Mule application
*****************************************
>> All type of Mule applications (Mule 3/ Mule 4/ with APIkit/ with Custom Java Code etc) running on Mule Runtimes support the Embedded Policy Enforcement on them.
>> The only option that cannot have or does not support embedded policy enforcement and must have API Proxy is for Non-Mule Applications.
So, Non-Mule application is the right answer.
An organization wants to make sure only known partners can invoke the organization’s APIs. To achieve this security goal, the organization wants to enforce a Client ID Enforcement policy in API Manager so that only registered partner applications can invoke the organization’s APIs.
In what type of API implementation does MuleSoft recommend adding an API proxy to enforce the Client ID Enforcement policy, rather than embedding the policy directly in the application’s JVM?
- A . A Mule 3 application using APIkit
- B . A Mule 3 or Mule 4 application modified with custom Java code
- C . A Mule 4 application with an API specification
- D . A Non-Mule application
D
Explanation:
Correct Answer. A Non-Mule application
*****************************************
>> All type of Mule applications (Mule 3/ Mule 4/ with APIkit/ with Custom Java Code etc) running on Mule Runtimes support the Embedded Policy Enforcement on them.
>> The only option that cannot have or does not support embedded policy enforcement and must have API Proxy is for Non-Mule Applications.
So, Non-Mule application is the right answer.
An organization wants to make sure only known partners can invoke the organization’s APIs. To achieve this security goal, the organization wants to enforce a Client ID Enforcement policy in API Manager so that only registered partner applications can invoke the organization’s APIs.
In what type of API implementation does MuleSoft recommend adding an API proxy to enforce the Client ID Enforcement policy, rather than embedding the policy directly in the application’s JVM?
- A . A Mule 3 application using APIkit
- B . A Mule 3 or Mule 4 application modified with custom Java code
- C . A Mule 4 application with an API specification
- D . A Non-Mule application
D
Explanation:
Correct Answer. A Non-Mule application
*****************************************
>> All type of Mule applications (Mule 3/ Mule 4/ with APIkit/ with Custom Java Code etc) running on Mule Runtimes support the Embedded Policy Enforcement on them.
>> The only option that cannot have or does not support embedded policy enforcement and must have API Proxy is for Non-Mule Applications.
So, Non-Mule application is the right answer.
Make consumption of assets at the rate of production
Explanation:
Correct Answer.
Make consumption of assets at the rate of production
Explanation:
Correct Answer.
Make consumption of assets at the rate of production
Explanation:
Correct Answer.
Make consumption of assets at the rate of production
Explanation:
Correct Answer.
Which of the following sequence is correct?
- A . API Client implementes logic to call an API >> API Consumer requests access to API >> API Implementation routes the request to >> API
- B . API Consumer requests access to API >> API Client implementes logic to call an API >> API routes the request to >> API Implementation
- C . API Consumer implementes logic to call an API >> API Client requests access to API >> API Implementation routes the request to >> API
- D . API Client implementes logic to call an API >> API Consumer requests access to API >> API routes the request to >> API Implementation
B
Explanation:
Correct Answer. API Consumer requests access to API >> API Client implementes logic to call an API >> API routes the request to >> API Implementation
*****************************************
>> API consumer does not implement any logic to invoke APIs. It is just a role. So, the option stating "API Consumer implementes logic to call an API" is INVALID.
>> API Implementation does not route any requests. It is a final piece of logic where
functionality of target systems is exposed. So, the requests should be routed to the API implementation by some other entity. So, the options stating "API Implementation routes the request to >> API" is INVALID
>> The statements in one of the options are correct but sequence is wrong. The sequence is given as "API Client implementes logic to call an API >> API Consumer requests access to API >> API routes the request to >> API Implementation". Here, the statements in the options are VALID but sequence is WRONG.
>> Right option and sequence is the one where API consumer first requests access to API on Anypoint Exchange and obtains client credentials. API client then writes logic to call an API by using the access client credentials requested by API consumer and the requests will be routed to API implementation via the API which is managed by API Manager.
Refer to the exhibit.
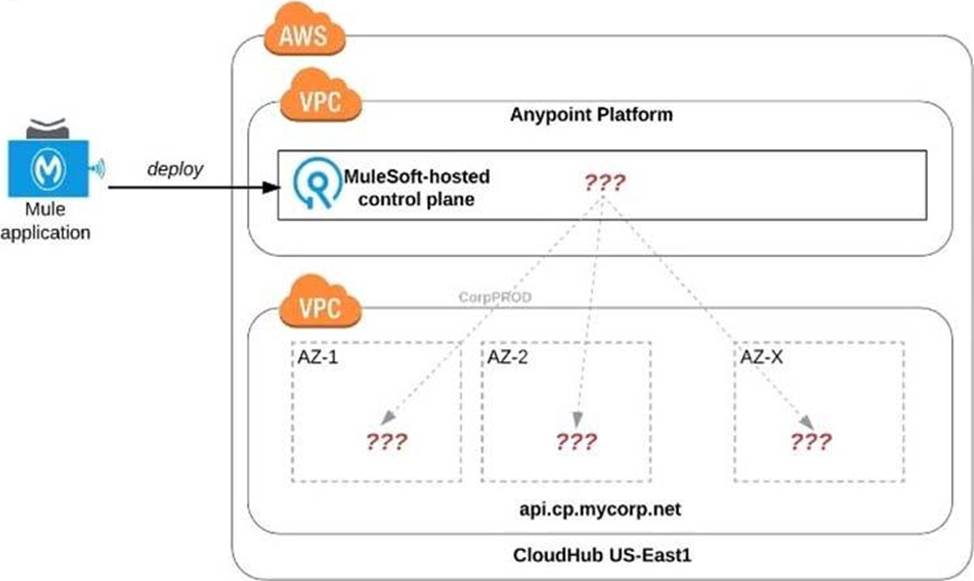

An organization uses one specific CloudHub (AWS) region for all CloudHub deployments.
How are CloudHub workers assigned to availability zones (AZs) when the organization’s Mule applications are deployed to CloudHub in that region?
- A . Workers belonging to a given environment are assigned to the same AZ within that region
- B . AZs are selected as part of the Mule application’s deployment configuration
- C . Workers are randomly distributed across available AZs within that region
- D . An AZ is randomly selected for a Mule application, and all the Mule application’s CloudHub workers are assigned to that one AZ
D
Explanation:
Correct Answer. Workers are randomly distributed across available AZs within that region.
*****************************************
>> Currently, we only have control to choose which AWS Region to choose but there is no control at all using any configurations or deployment options to decide what Availability
Zone (AZ) to assign to what worker.
>> There are NO fixed or implicit rules on platform too w.r.t assignment of AZ to workers based on environment or application.
>> They are completely assigned in random. However, cloudhub definitely ensures that HA is achieved by assigning the workers to more than on AZ so that all workers are not assigned to same AZ for same application.
https://help.mulesoft.com/s/question/0D52T000051rqDj/one-cloudhub-aws-region-how-cloudhub-workers-are-assigned-to-availability-zones-azs-
Graphical user interface, application
Description automatically generated
Bottom of Form
Top of Form
An organization makes a strategic decision to move towards an IT operating model that emphasizes consumption of reusable IT assets using modern APIs (as defined by MuleSoft).
What best describes each modern API in relation to this new IT operating model?
- A . Each modern API has its own software development lifecycle, which reduces the need for documentation and automation
- B . Each modem API must be treated like a product and designed for a particular target audience (for instance, mobile app developers)
- C . Each modern API must be easy to consume, so should avoid complex authentication mechanisms such as SAML or JWT D
- D . Each modern API must be REST and HTTP based
B
Explanation:
Correct Answers:
An organization makes a strategic decision to move towards an IT operating model that emphasizes consumption of reusable IT assets using modern APIs (as defined by MuleSoft).
What best describes each modern API in relation to this new IT operating model?
- A . Each modern API has its own software development lifecycle, which reduces the need for documentation and automation
- B . Each modem API must be treated like a product and designed for a particular target audience (for instance, mobile app developers)
- C . Each modern API must be easy to consume, so should avoid complex authentication mechanisms such as SAML or JWT D
- D . Each modern API must be REST and HTTP based
B
Explanation:
Correct Answers:
An organization is deploying their new implementation of the OrderStatus System API to multiple workers in CloudHub. This API fronts the organization’s on-premises Order Management System, which is accessed by the API implementation over an IPsec tunnel.
What type of error typically does NOT result in a service outage of the OrderStatus System API?
- A . A CloudHub worker fails with an out-of-memory exception
- B . API Manager has an extended outage during the initial deployment of the API implementation
- C . The AWS region goes offline with a major network failure to the relevant AWS data centers
- D . The Order Management System is Inaccessible due to a network outage in the organization’s on-premises data center
A
Explanation:
Correct Answer. A CloudHub worker fails with an out-of-memory exception.
*****************************************
>> An AWS Region itself going down will definitely result in an outage as it does not matter how many workers are assigned to the Mule App as all of those in that region will go down. This is a complete downtime and outage.
>> Extended outage of API manager during initial deployment of API implementation will of course cause issues in proper application startup itself as the API Autodiscovery might fail or API policy templates and polices may not be downloaded to embed at the time of applicaiton startup etc… there are many reasons that could cause issues.
>> A network outage onpremises would of course cause the Order Management System not accessible and it does not matter how many workers are assigned to the app they all will fail and cause outage for sure.
The only option that does NOT result in a service outage is if a cloudhub worker fails with an out-of-memory exception. Even if a worker fails and goes down, there are still other workers to handle the requests and keep the API UP and Running. So, this is the right answer.
Due to a limitation in the backend system, a system API can only handle up to 500 requests per second .
What is the best type of API policy to apply to the system API to avoid overloading the backend system?
- A . Rate limiting
- B . HTTP caching
- C . Rate limiting – SLA based
- D . Spike control
D
Explanation:
Correct Answer. Spike control
*****************************************
>> First things first, HTTP Caching policy is for purposes different than avoiding the backend system from overloading. So this is OUT.
>> Rate Limiting and Throttling/ Spike Control policies are designed to limit API access, but have different intentions.
>> Rate limiting protects an API by applying a hard limit on its access.
>> Throttling/ Spike Control shapes API access by smoothing spikes in traffic.
That is why, Spike Control is the right option.
A company requires Mule applications deployed to CloudHub to be isolated between non-production and production environments. This is so Mule applications deployed to non-production environments can only access backend systems running in their customer-hosted non-production environment, and so Mule applications deployed to production environments can only access backend systems running in their customer-hosted production environment .
How does MuleSoft recommend modifying Mule applications, configuring environments, or changing infrastructure to support this type of per-environment isolation between Mule applications and backend systems?
- A . Modify properties of Mule applications deployed to the production Anypoint Platform environments to prevent access from non-production Mule applications
- B . Configure firewall rules in the infrastructure inside each customer-hosted environment so that only IP addresses from the corresponding Anypoint Platform environments are allowed to communicate with corresponding backend systems
- C . Create non-production and production environments in different Anypoint Platform
business groups - D . Create separate Anypoint VPCs for non-production and production environments, then configure connections to the backend systems in the corresponding customer-hosted environments
D
Explanation:
Correct Answer. Create separate Anypoint VPCs for non-production and production environments, then configure connections to the backend systems in the corresponding customer-hosted environments.
*****************************************
>> Creating different Business Groups does NOT make any difference w.r.t accessing the non-prod and prod customer-hosted environments. Still they will be accessing from both Business Groups unless process network restrictions are put in place.
>> We need to modify or couple the Mule Application Implementations with the environment. In fact, we should never implements application coupled with environments by binding them in the properties. Only basic things like endpoint URL etc should be bundled in properties but not environment level access restrictions.
>> IP addresses on CloudHub are dynamic until unless a special static addresses are assigned. So it is not possible to setup firewall rules in customer-hosted infrastrcture. More over, even if static IP addresses are assigned, there could be 100s of applications running on cloudhub and setting up rules for all of them would be a hectic task, non-maintainable and definitely got a good practice.
>> The best practice recommended by Mulesoft (In fact any cloud provider), is to have your Anypoint VPCs seperated for Prod and Non-Prod and perform the VPC peering or VPN tunneling for these Anypoint VPCs to respective Prod and Non-Prod customer-hosted
environment networks.
https://docs.mulesoft.com/runtime-manager/virtual-private-cloud
Bottom of Form
Top of Form
What correctly characterizes unit tests of Mule applications?
- A . They test the validity of input and output of source and target systems
- B . They must be run in a unit testing environment with dedicated Mule runtimes for the environment
- C . They must be triggered by an external client tool or event source
- D . They are typically written using MUnit to run in an embedded Mule runtime that does not require external connectivity
D
Explanation:
Correct Answer. They are typically written using MUnit to run in an embedded Mule runtime that does not require external connectivity.
*****************************************
Below TWO are characteristics of Integration Tests but NOT unit tests:
>> They test the validity of input and output of source and target systems.
>> They must be triggered by an external client tool or event source.
It is NOT TRUE that Unit Tests must be run in a unit testing environment with dedicated Mule runtimes for the environment.
MuleSoft offers MUnit for writing Unit Tests and they run in an embedded Mule Runtime without needing any separate/ dedicated Runtimes to execute them. They also do NOT need any external connectivity as MUnit supports mocking via stubs. https://dzone.com/articles/munit-framework
A company uses a hybrid Anypoint Platform deployment model that combines the EU control plane with customer-hosted Mule runtimes. After successfully testing a Mule API implementation in the Staging environment, the Mule API implementation is set with environment-specific properties and must be promoted to the Production environment .
What is a way that MuleSoft recommends to configure the Mule API implementation and automate its promotion to the Production environment?
- A . Bundle properties files for each environment into the Mule API implementation’s deployable archive, then promote the Mule API implementation to the Production environment using Anypoint CLI or the Anypoint Platform REST APIsB.
- B . Modify the Mule API implementation’s properties in the API Manager Properties tab, then promote the Mule API implementation to the Production environment using API Manager
- C . Modify the Mule API implementation’s properties in Anypoint Exchange, then promote the Mule API implementation to the Production environment using Runtime Manager
- D . Use an API policy to change properties in the Mule API implementation deployed to the Staging environment and another API policy to deploy the Mule API implementation to the Production environment
A
Explanation:
Correct Answer. Bundle properties files for each environment into the Mule API implementation’s deployable archive, then promote the Mule API implementation to the Production environment using Anypoint CLI or the Anypoint Platform REST APIs
*****************************************
>> Anypoint Exchange is for asset discovery and documentation. It has got no provision to modify the properties of Mule API implementations at all.
>> API Manager is for managing API instances, their contracts, policies and SLAs. It has also got no provision to modify the properties of API implementations.
>> API policies are to address Non-functional requirements of APIs and has again got no provision to modify the properties of API implementations.
So, the right way and recommended way to do this as part of development practice is to bundle properties files for each environment into the Mule API implementation and just point and refer to respective file per environment.
The responses to some HTTP requests can be cached depending on the HTTP verb used in the request. According to the HTTP specification, for what HTTP verbs is this safe to do?
- A . PUT, POST, DELETE
- B . GET, HEAD, POST
- C . GET, PUT, OPTIONS
- D . GET, OPTIONS, HEAD
D
Explanation:
Correct Answer. GET, OPTIONS, HEAD


http://restcookbook.com/HTTP%20Methods/idempotency/
An API implementation is deployed to CloudHub.
What conditions can be alerted on using the default Anypoint Platform functionality, where the alert conditions depend on the end-to-end request processing of the API implementation?
- A . When the API is invoked by an unrecognized API client
- B . When a particular API client invokes the API too often within a given time period
- C . When the response time of API invocations exceeds a threshold
- D . When the API receives a very high number of API invocations
C
Explanation:
Correct Answer. When the response time of API invocations exceeds a threshold
*****************************************
>> Alerts can be setup for all the given options using the default Anypoint Platform functionality
>> However, the question insists on an alert whose conditions depend on the end-to-end request processing of the API implementation.
>> Alert w.r.t "Response Times" is the only one which requires end-to-end request
processing of API implementation in order to determine if the threshold is exceeded or not.
Reference: https://docs.mulesoft.com/api-manager/2.x/using-api-alerts
A REST API is being designed to implement a Mule application.
What standard interface definition language can be used to define REST APIs?
- A . Web Service Definition Language(WSDL)
- B . OpenAPI Specification (OAS)
- C . YAML
- D . AsyncAPI Specification
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
A system API is deployed to a primary environment as well as to a disaster recovery (DR) environment, with different DNS names in each environment. A process API is a client to the system API and is being rate limited by the system API, with different limits in each of the environments. The system API’s DR environment provides only 20% of the rate limiting offered by the primary environment .
What is the best API fault-tolerant invocation strategy to reduce overall errors in the process API, given these conditions and constraints?
- A . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
- B . Invoke the system API deployed to the primary environment; add retry logic to the process API to handle intermittent failures by invoking the system API deployed to the DR environment
- C . In parallel, invoke the system API deployed to the primary environment and the system API deployed to the DR environment; add timeout and retry logic to the process API to avoid intermittent failures; add logic to the process API to combine the results
- D . Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke a copy of the process API deployed to the DR environment
A
Explanation:
Correct Answer. Invoke the system API deployed to the primary environment; add timeout and retry logic to the process API to avoid intermittent failures; if it still fails, invoke the system API deployed to the DR environment
*****************************************
There is one important consideration to be noted in the question which is – System API in DR environment provides only 20% of the rate limiting offered by the primary environment. So, comparitively, very less calls will be allowed into the DR environment API opposed to its primary environment. With this in mind, lets analyse what is the right and best fault-tolerant invocation strategy.
What best describes the Fully Qualified Domain Names (FQDNs), also known as DNS entries, created when a Mule application is deployed to the CloudHub Shared Worker Cloud?
- A . A fixed number of FQDNs are created, IRRESPECTIVE of the environment and VPC design
- B . The FQDNs are determined by the application name chosen, IRRESPECTIVE of the region
- C . The FQDNs are determined by the application name, but can be modified by an administrator after deployment
- D . The FQDNs are determined by both the application name and the Anypoint Platform organization
B
Explanation:
Correct Answer. The FQDNs are determined by the application name chosen,
IRRESPECTIVE of the region
*****************************************
>> When deploying applications to Shared Worker Cloud, the FQDN are always determined by application name chosen.
>> It does NOT matter what region the app is being deployed to.
>> Although it is fact and true that the generated FQDN will have the region included in it (Ex: exp-salesorder-api.au-s1.cloudhub.io), it does NOT mean that the same name can be used when deploying to another CloudHub region.
>> Application name should be universally unique irrespective of Region and Organization and solely determines the FQDN for Shared Load Balancers.