Hortonworks Apache Hadoop Developer Hadoop 2.0 Certification exam for Pig and Hive Developer Online Training
Hortonworks Apache Hadoop Developer Online Training
The questions for Apache Hadoop Developer were last updated at Dec 13,2025.
- Exam Code: Apache Hadoop Developer
- Exam Name: Hadoop 2.0 Certification exam for Pig and Hive Developer
- Certification Provider: Hortonworks
- Latest update: Dec 13,2025
What types of algorithms are difficult to express in MapReduce v1 (MRv1)?
- A . Algorithms that require applying the same mathematical function to large numbers of individual binary records.
- B . Relational operations on large amounts of structured and semi-structured data.
- C . Algorithms that require global, sharing states.
- D . Large-scale graph algorithms that require one-step link traversal.
- E . Text analysis algorithms on large collections of unstructured text (e.g, Web crawls).
What types of algorithms are difficult to express in MapReduce v1 (MRv1)?
- A . Algorithms that require applying the same mathematical function to large numbers of individual binary records.
- B . Relational operations on large amounts of structured and semi-structured data.
- C . Algorithms that require global, sharing states.
- D . Large-scale graph algorithms that require one-step link traversal.
- E . Text analysis algorithms on large collections of unstructured text (e.g, Web crawls).
You need to create a job that does frequency analysis on input data. You will do this by writing a Mapper that uses TextInputFormat and splits each value (a line of text from an input file) into individual characters. For each one of these characters, you will emit the character as a key and an InputWritable as the value.
As this will produce proportionally more intermediate data than input data, which two resources should you expect to be bottlenecks?
- A . Processor and network I/O
- B . Disk I/O and network I/O
- C . Processor and RAM
- D . Processor and disk I/O
Which one of the following statements regarding the components of YARN is FALSE?
- A . A Container executes a specific task as assigned by the ApplicationMaster
- B . The ResourceManager is responsible for scheduling and allocating resources
- C . A client application submits a YARW job to the ResourceManager
- D . The ResourceManager monitors and restarts any failed Containers
You are developing a combiner that takes as input Text keys, IntWritable values, and emits Text keys, IntWritable values.
Which interface should your class implement?
- A . Combiner <Text, IntWritable, Text, IntWritable>
- B . Mapper <Text, IntWritable, Text, IntWritable>
- C . Reducer <Text, Text, IntWritable, IntWritable>
- D . Reducer <Text, IntWritable, Text, IntWritable>
- E . Combiner <Text, Text, IntWritable, IntWritable>
Which one of the following Hive commands uses an HCatalog table named x?
- A . SELECT * FROM x;
- B . SELECT x.-FROM org.apache.hcatalog.hive.HCatLoader(‘x’);
- C . SELECT * FROM org.apache.hcatalog.hive.HCatLoader(‘x’);
- D . Hive commands cannot reference an HCatalog table
Given the following Pig command:
logevents = LOAD 'input/my.log' AS (date:chararray, levehstring, code:int, message:string);
Which one of the following statements is true?
- A . The logevents relation represents the data from the my.log file, using a comma as the parsing delimiter
- B . The logevents relation represents the data from the my.log file, using a tab as the parsing delimiter
- C . The first field of logevents must be a properly-formatted date string or table return an error
- D . The statement is not a valid Pig command
Consider the following two relations, A and B.
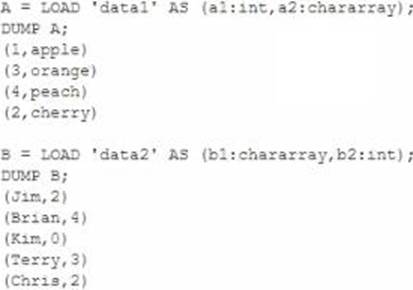
- A . C = DOIN B BY a1, A by b2;
- B . C = JOIN A by al, B by b2;
- C . C = JOIN A a1, B b2;
- D . C = JOIN A SO, B $1;
Given the following Hive commands:

Which one of the following statements Is true?
- A . The file mydata.txt is copied to a subfolder of /apps/hive/warehouse
- B . The file mydata.txt is moved to a subfolder of /apps/hive/warehouse
- C . The file mydata.txt is copied into Hive’s underlying relational database 0.
- D . The file mydata.txt does not move from Its current location in HDFS
In a MapReduce job, the reducer receives all values associated with same key.
Which statement best describes the ordering of these values?
- A . The values are in sorted order.
- B . The values are arbitrarily ordered, and the ordering may vary from run to run of the same MapReduce job.
- C . The values are arbitrary ordered, but multiple runs of the same MapReduce job will always have the same ordering.
- D . Since the values come from mapper outputs, the reducers will receive contiguous sections of sorted values.
Latest Apache Hadoop Developer Dumps Valid Version with 108 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
