Topic 1, Mountkirk Games Case Study 1
Company Overview
Mountkirk Games makes online, session-based, multiplayer games for the most popular mobile platforms.
Company Background
Mountkirk Games builds all of their games with some server-side integration, and has historically used cloud providers to lease physical servers. A few of their games were more popular than expected, and they had problems scaling their application servers, MySQL databases, and analytics tools.
Mountkirk’s current model is to write game statistics to files and send them through an ETL tool that loads them into a centralized MySQL database for reporting.
Solution Concept
Mountkirk Gamesis building a new game, which they expect to be very popular. They plan to deploy the game’s backend on Google Compute Engine so they can capture streaming metrics, run intensive analytics, and take advantage of its autoscaling server environment and integrate with a managed NoSQL database.
Technical Requirements
Requirements for Game Backend Platform


CEO Statement
Our last successful game did not scale well with our previous cloud provider, resulting in lower user adoption and affecting the game’s reputation. Our investors want more key performance indicators (KPIs) to evaluate the speed and stability of the game, as well as other metrics that provide deeper insight into usage patterns so we can adapt the game to target users.
CTO Statement
Our current technology stack cannot provide the scale we need, so we want to replace MySQL and move to an environment that provides autoscaling, low latency load balancing, and frees us up from managing physical servers.
CFO Statement
We are not capturing enough user demographic data, usage metrics, and other KPIs. As a result, we do not engage the right users, we are not confident that our marketing is targeting the right users, and we are not selling enough premium Blast-Ups inside the games, which dramatically impacts our revenue.
For this question, refer to the Mountkirk Games case study.
Mountkirk Games wants you to design their new testing strategy .
How should the test coverage differ from their existing backends on the other platforms?
- A . Tests should scale well beyond the prior approaches.
- B . Unit tests are no longer required, only end-to-end tests.
- C . Tests should be applied after the release is in the production environment.
- D . Tests should include directly testing the Google Cloud Platform (GCP) infrastructure.
A
Explanation:
From Scenario:
A few of their games were more popular than expected, and they had problems scaling their application servers, MySQL databases, and analytics tools.
Requirements for Game Analytics Platform include: Dynamically scale up or down based on game activity
For this question, refer to the Mountkirk Games case study.
Mountkirk Games wants to set up a real-time analytics platform for their new game. The new platform must meet their technical requirements .
Which combination of Google technologies will meet all of their requirements?
- A . Container Engine, Cloud Pub/Sub, and Cloud SQL
- B . Cloud Dataflow, Cloud Storage, Cloud Pub/Sub, and BigQuery
- C . Cloud SQL, Cloud Storage, Cloud Pub/Sub, and Cloud Dataflow
- D . Cloud Dataproc, Cloud Pub/Sub, Cloud SQL, and Cloud Dataflow
- E . Cloud Pub/Sub, Compute Engine, Cloud Storage, and Cloud Dataproc
B
Explanation:
A real time requires Stream / Messaging so Pub/Sub, Analytics by Big Query.
Ingest millions of streaming events per second from anywhere in the world with Cloud Pub/Sub, powered by Google’s unique, high-speed private network. Process the streams with Cloud Dataflow to ensure reliable, exactly-once, low-latency data transformation. Stream the transformed data into BigQuery, the cloud-native data warehousing service, for immediate analysis via SQL or popular visualization tools.
From scenario: They plan to deploy the game’s backend on Google Compute Engine so they can capture streaming metrics, run intensive analytics.
Requirements for Game Analytics Platform
✑ Dynamically scale up or down based on game activity
✑ Process incoming data on the fly directly from the game servers
✑ Process data that arrives late because of slow mobile networks
✑ Allow SQL queries to access at least 10 TB of historical data
✑ Process files that are regularly uploaded by users’ mobile devices
✑ Use only fully managed services
References: https://cloud.google.com/solutions/big-data/stream-analytics/
For this question, refer to the Mountkirk Games case study.
Mountkirk Games’ gaming servers are not automatically scaling properly. Last month, they rolled out a new feature, which suddenly became very popular. A record number of users are trying to use the service, but many of them are getting 503 errors and very slow response times .
What should they investigate first?
- A . Verify that the database is online.
- B . Verify that the project quota hasn’t been exceeded.
- C . Verify that the new feature code did not introduce any performance bugs.
- D . Verify that the load-testing team is not running their tool against production.
B
Explanation:
503 is service unavailable error. If the database was online everyone would get the 503 error.
https://cloud.google.com/docs/quota#capping_usage
For this question, refer to the Mountkirk Games case study.
Mountkirk Games has deployed their new backend on Google Cloud Platform (GCP). You want to create a thorough testing process for new versions of the backend before they are released to the public. You want the testing environment to scale in an economical way .
How should you design the process?
- A . Create a scalable environment in GCP for simulating production load.
- B . Use the existing infrastructure to test the GCP-based backend at scale.
- C . Build stress tests into each component of your application using resources internal to GCP to simulate load.
- D . Create a set of static environments in GCP to test different levels of load ― for example, high, medium, and low.
A
Explanation:
From scenario: Requirements for Game Backend Platform
✑ Dynamically scale up or down based on game activity
✑ Connect to a managed NoSQL database service
✑ Run customize Linux distro
For this question, refer to the Mountkirk Games case study.
Mountkirk Games wants to set up a continuous delivery pipeline. Their architecture includes many small services that they want to be able to update and roll back quickly.
Mountkirk Games has the following requirements:
• Services are deployed redundantly across multiple regions in the US and Europe.
• Only frontend services are exposed on the public internet.
• They can provide a single frontend IP for their fleet of services.
• Deployment artifacts are immutable.
Which set of products should they use?
- A . Google Cloud Storage, Google Cloud Dataflow, Google Compute Engine
- B . Google Cloud Storage, Google App Engine, Google Network Load Balancer
- C . Google Kubernetes Registry, Google Container Engine, Google HTTP(S) Load Balancer
- D . Google Cloud Functions, Google Cloud Pub/Sub, Google Cloud Deployment Manager
For this question, refer to the Mountkirk Games case study.
Mountkirk Games needs to create a repeatable and configurable mechanism for deploying isolated application environments. Developers and testers can access each other’s environments and resources, but they cannot access staging or production resources. The staging environment needs access to some services from production.
What should you do to isolate development environments from staging and production?
- A . Create a project for development and test and another for staging and production.
- B . Create a network for development and test and another for staging and production.
- C . Create one subnetwork for development and another for staging and production.
- D . Create one project for development, a second for staging and a third for production.
Topic 2, TerramEarth Case Study
Company Overview
TerramEarth manufactures heavy equipment for the mining and agricultural industries: about 80% of their business is from mining and 20% from agriculture. They currently have over 500 dealers and service centers in 100 countries. Their mission is to build products that make their customers more productive.
Company background
TerramEarth was formed in 1946, when several small, family owned companies combined to retool after World War II. The company cares about their employees and customers and considers them to be extended members of their family.
TerramEarth is proud of their ability to innovate on their core products and find new markets as their customers’ needs change. For the past 20 years, trends in the industry have been largely toward increasing productivity by using larger vehicles with a human operator.
Solution Concept
There are 20 million TerramEarth vehicles in operation that collect 120 fields of data per second. Data is stored locally on the vehicle and can be accessed for analysis when a vehicle is serviced. The data is downloaded via a maintenance port. This same port can be used to adjust operational parameters, allowing the vehicles to be upgraded in the field with new computing modules.
Approximately 200,000 vehicles are connected to a cellular network, allowing TerramEarth to collect data directly. At a rate of 120 fields of data per second with 22 hours of operation per day, Terram Earth collects a total of about 9 TB/day from these connected vehicles.
Existing Technical Environment
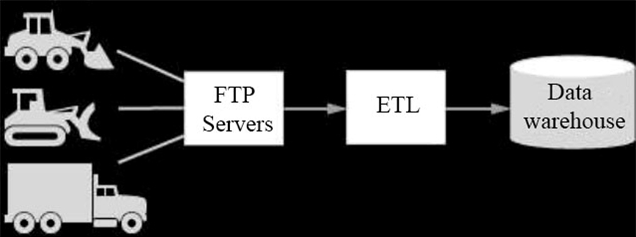

TerramEarth’s existing architecture is composed of Linux-based systems that reside in a data center. These systems gzip CSV files from the field and upload via FTP, transform and aggregate them, and place the data in their data warehouse. Because this process takes time, aggregated reports are based on data that is 3 weeks old.
With this data, TerramEarth has been able to preemptively stock replacement parts and reduce unplanned downtime of their vehicles by 60%. However, because the data is stale, some customers are without their vehicles for up to 4 weeks while they wait for replacement parts.
Business Requirements
– Decrease unplanned vehicle downtime to less than 1 week, without increasing the cost of carrying surplus inventory
– Support the dealer network with more data on how their customers use their equipment to better position new products and services
– Have the ability to partner with different companies C especially with seed and fertilizer suppliers in the fast-growing agricultural business C to create compelling joint offerings for their customers.
CEO Statement
We have been successful in capitalizing on the trend toward larger vehicles to increase the productivity of our customers. Technological change is occurring rapidly, and TerramEarth has taken advantage of connected devices technology to provide our customers with better services, such as our intelligent farming equipment. With this technology, we have been able to increase farmers’ yields by 25%, by using past trends to adjust how our vehicles operate. These advances have led to the rapid growth of our agricultural product line, which we expect will generate 50% of our revenues by 2020.
CTO Statement
Our competitive advantage has always been in the manufacturing process, with our ability to build better vehicles for lower cost than our competitors. However, new products with different approaches are constantly being developed, and I’m concerned that we lack the skills to undergo the next wave of transformations in our industry. Unfortunately, our CEO doesn’t take technology obsolescence seriously and he considers the many new companies in our industry to be niche players. My goals are to build our skills while addressing immediate market needs through incremental innovations.
For this question refer to the TerramEarth case study.
Which of TerramEarth’s legacy enterprise processes will experience significant change as a result of increased Google Cloud Platform adoption?
- A . Opex/capex allocation, LAN changes, capacity planning
- B . Capacity planning, TCO calculations, opex/capex allocation
- C . Capacity planning, utilization measurement, data center expansion
- D . Data Center expansion, TCO calculations, utilization measurement
B
Explanation:
Capacity planning, TCO calculations, opex/capex allocation From the case study, it can conclude that Management (CXO) all concern rapid provision of resources (infrastructure) for growing as well as cost management, such as Cost optimization in Infrastructure, trade up front capital expenditures (Capex) for ongoing operating expenditures (Opex), and Total cost of ownership (TCO)
For this question, refer to the TerramEarth case study.
TerramEarth has equipped unconnected trucks with servers and sensors to collet telemetry data. Next year they want to use the data to train machine learning models. They want to store this data in the cloud while reducing costs .
What should they do?
- A . Have the vehicle’ computer compress the data in hourly snapshots, and store it in a Google Cloud storage (GCS) Nearline bucket.
- B . Push the telemetry data in Real-time to a streaming dataflow job that compresses the data, and store it in Google BigQuery.
- C . Push the telemetry data in real-time to a streaming dataflow job that compresses the data, and store it in Cloud Bigtable.
- D . Have the vehicle’s computer compress the data in hourly snapshots, a Store it in a GCS Coldline bucket.
D
Explanation:
Coldline Storage is the best choice for data that you plan to access at most once a year, due to its slightly lower availability, 90-day minimum storage duration, costs for data access, and higher per-operation costs. For example:
Cold Data Storage – Infrequently accessed data, such as data stored for legal or regulatory reasons, can be stored at low cost as Coldline Storage, and be available when you need it.
Disaster recovery – In the event of a disaster recovery event, recovery time is key. Cloud Storage provides low latency access to data stored as Coldline Storage. References: https://cloud.google.com/storage/docs/storage-classes
For this question, refer to the TerramEarth case study.
TerramEarth plans to connect all 20 million vehicles in the field to the cloud. This increases the volume to 20 million 600 byte records a second for 40 TB an hour .
How should you design the data ingestion?
- A . Vehicles write data directly to GCS.
- B . Vehicles write data directly to Google Cloud Pub/Sub.
- C . Vehicles stream data directly to Google BigQuery.
- D . Vehicles continue to write data using the existing system (FTP).
B
Explanation:
https://cloud.google.com/solutions/data-lifecycle-cloud-platform https://cloud.google.com/solutions/designing-connected-vehicle-platform
For this question, refer to the TerramEarth case study.
TerramEarth’s CTO wants to use the raw data from connected vehicles to help identify approximately when a vehicle in the development team to focus their failure. You want to allow analysts to centrally query the vehicle data .
Which architecture should you recommend?
A)
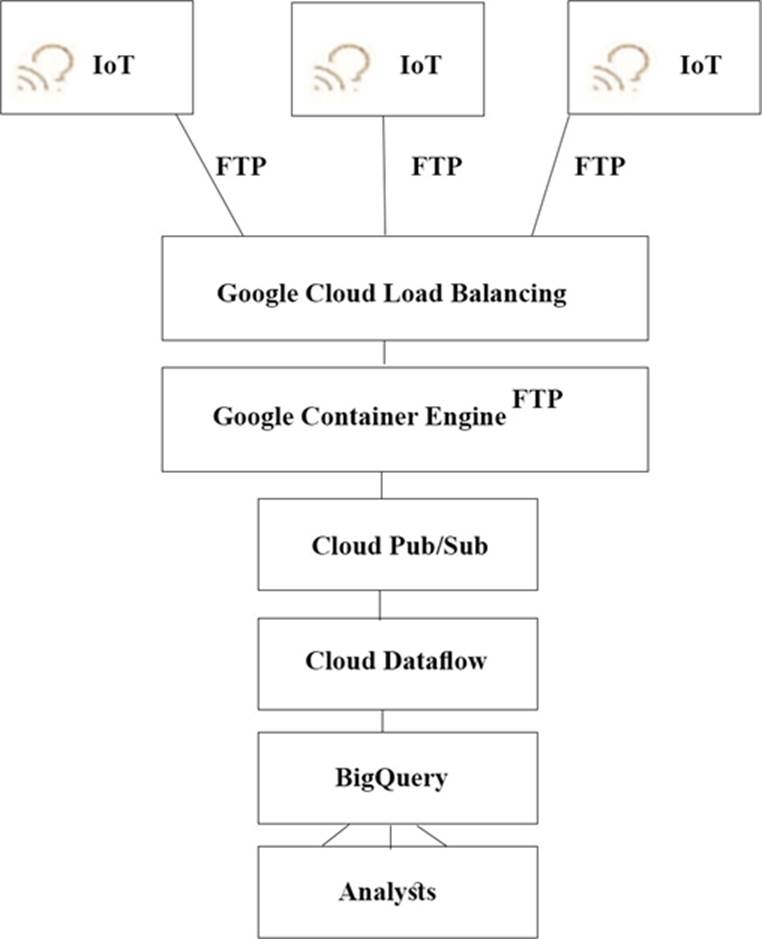

B)
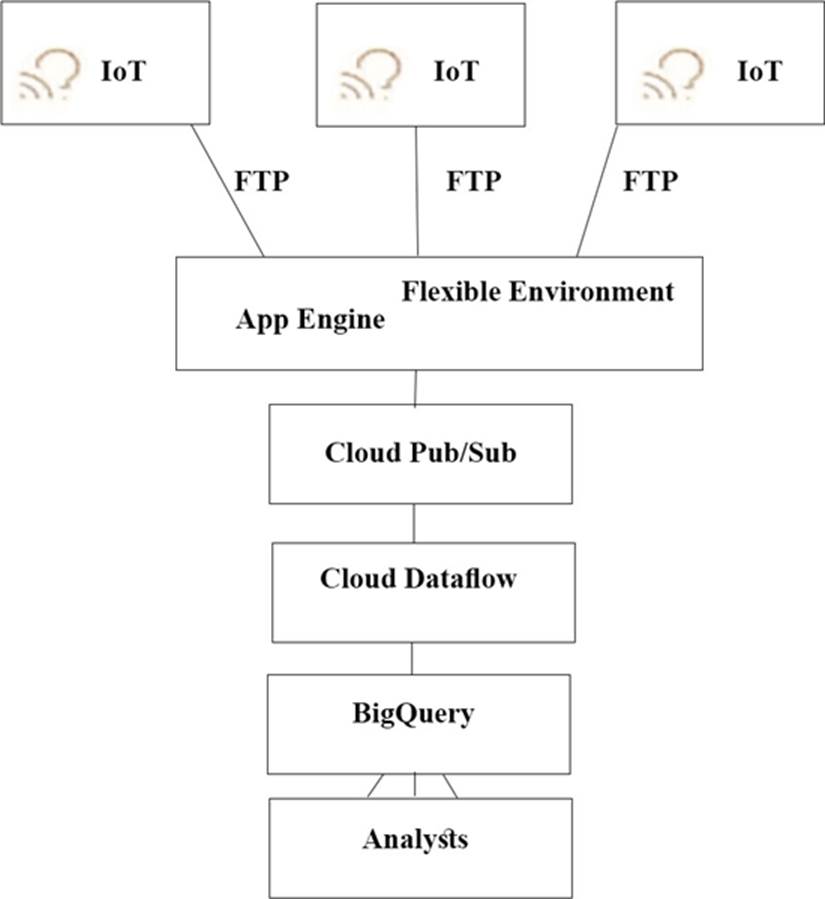

C)
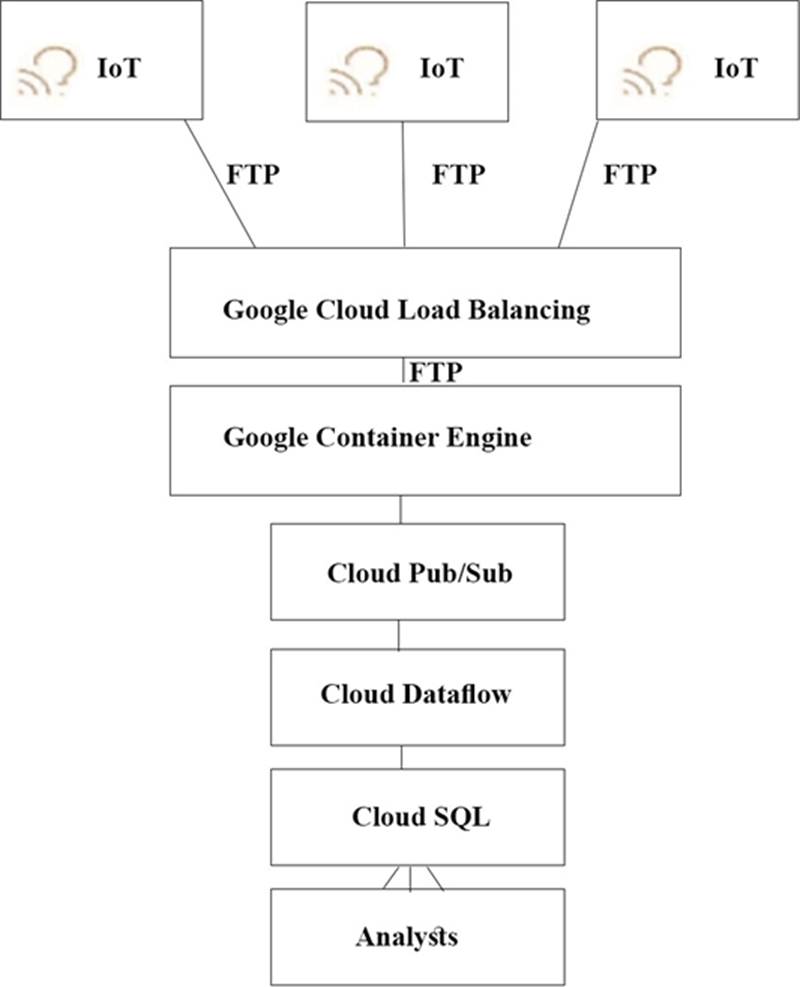

D)
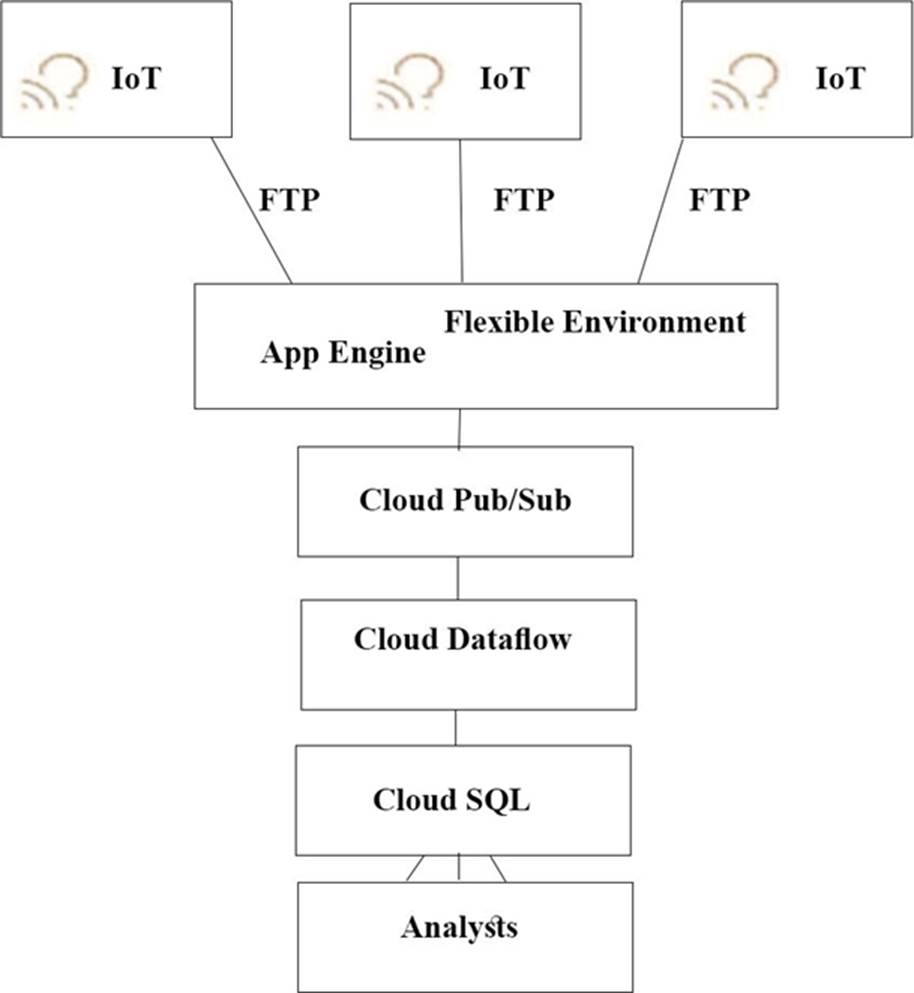

- A . Option A
- B . Option B
- C . Option C
- D . Option D
A
Explanation:
The push endpoint can be a load balancer.
A container cluster can be used.
Cloud Pub/Sub for Stream Analytics
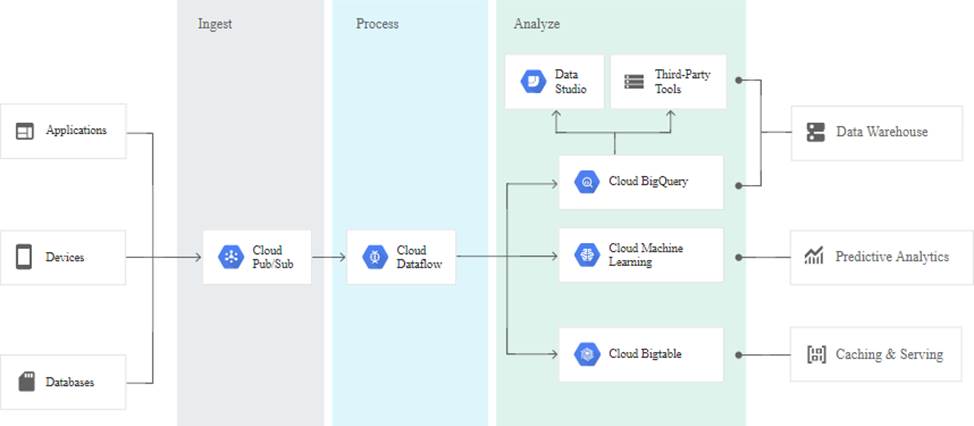

References:
https://cloud.google.com/pubsub/
https://cloud.google.com/solutions/iot/
https://cloud.google.com/solutions/designing-connected-vehicle-platform
https://cloud.google.com/solutions/designing-connected-vehicle-platform#data_ingestion
http://www.eweek.com/big-data-and-analytics/google-touts-value-of-cloud-iot-core-for-analyzing-connected-car-data
https://cloud.google.com/solutions/iot/
For this question, refer to the TerramEarth case study
You analyzed TerramEarth’s business requirement to reduce downtime, and found that they can achieve a majority of time saving by reducing customers’ wait time for parts You decided to focus on reduction of the 3 weeks aggregate reporting time.
Which modifications to the company’s processes should you recommend?
- A . Migrate from CSV to binary format, migrate from FTP to SFTP transport, and develop machine learning analysis of metrics.
- B . Migrate from FTP to streaming transport, migrate from CSV to binary format, and develop machine learning analysis of metrics.
- C . Increase fleet cellular connectivity to 80%, migrate from FTP to streaming transport, and develop machine learning analysis of metrics.
- D . Migrate from FTP to SFTP transport, develop machine learning analysis of metrics, and increase dealer local inventory by a fixed factor.
C
Explanation:
The Avro binary format is the preferred format for loading compressed data. Avro data is faster to load because the data can be read in parallel, even when the data blocks are compressed.
Cloud Storage supports streaming transfers with the gsutil tool or boto library, based on HTTP chunked transfer encoding. Streaming data lets you stream data to and from your Cloud Storage account as soon as it becomes available without requiring that the data be first saved to a separate file. Streaming transfers are useful if you have a process that generates data and you do not want to buffer it locally before uploading it, or if you want to send the result from a computational pipeline directly into Cloud Storage.
References:
https://cloud.google.com/storage/docs/streaming
https://cloud.google.com/bigquery/docs/loading-data
For this question, refer to the TerramEarth case study.
TerramEarth’s 20 million vehicles are scattered around the world. Based on the vehicle’s location its telemetry data is stored in a Google Cloud Storage (GCS) regional bucket (US. Europe, or Asia). The CTO has asked you to run a report on the raw telemetry data to determine why vehicles are breaking down after 100 K miles. You want to run this job on all the data .
What is the most cost-effective way to run this job?
- A . Move all the data into 1 zone, then launch a Cloud Dataproc cluster to run the job.
- B . Move all the data into 1 region, then launch a Google Cloud Dataproc cluster to run the job.
- C . Launch a cluster in each region to preprocess and compress the raw data, then move the data into a multi region bucket and use a Dataproc cluster to finish the job.
- D . Launch a cluster in each region to preprocess and compress the raw data, then move the data into a region bucket and use a Cloud Dataproc cluster to finish the jo
D
Explanation:
Storageguarantees 2 replicates which are geo diverse (100 miles apart) which can get better remote latency and availability.
More importantly, is that multiregional heavily leverages Edge caching and CDNs to provide the content to the end users.
All this redundancy and caching means that Multiregional comes with overhead to sync and ensure consistency between geo-diverse areas. As such, it’s much better for write-once-read-many scenarios. This means frequently accessed (e.g. “hot” objects) around the world, such as website content, streaming videos, gaming or mobile applications.
References: https://medium.com/google-cloud/google-cloud-storage-what-bucket-class-for-the-best-performance-5c847ac8f9f2
For this question refer to the TerramEarth case study
Operational parameters such as oil pressure are adjustable on each of TerramEarth’s vehicles to increase their efficiency, depending on their environmental conditions. Your primary goal is to increase the operating efficiency of all 20 million cellular and unconnected vehicles in the field How can you accomplish this goal?
- A . Have your engineers inspect the data for patterns, and then create an algorithm with rules that make operational adjustments automatically.
- B . Capture all operating data, train machine learning models that identify ideal operations, and run locally to make operational adjustments automatically.
- C . Implement a Google Cloud Dataflow streaming job with a sliding window, and use Google Cloud Messaging (GCM) to make operational adjustments automatically.
- D . Capture all operating data, train machine learning models that identify ideal operations, and host in Google Cloud Machine Learning (ML) Platform to make operational adjustments automatically.
For this question, refer to the TerramEarth case study.
To speed up data retrieval, more vehicles will be upgraded to cellular connections and be able to transmit data to the ETL process. The current FTP process is error-prone and restarts the data transfer from the start of the file when connections fail, which happens often. You want to improve the reliability of the solution and minimize data transfer time on the cellular connections .
What should you do?
- A . Use one Google Container Engine cluster of FTP servers. Save the data to a Multi-Regional bucket. Run the ETL process using data in the bucket.
- B . Use multiple Google Container Engine clusters running FTP servers located in different regions. Save the data to Multi-Regional buckets in us, eu, and asia. Run the ETL process using the data in the bucket.
- C . Directly transfer the files to different Google Cloud Multi-Regional Storage bucket locations in us, eu, and asia using Google APIs over HTTP(S). Run the ETL process using the data in the bucket.
- D . Directly transfer the files to a different Google Cloud Regional Storage bucket location in us, eu, and asia using Google APIs over HTTP(S). Run the ETL process to retrieve the data from each Regional bucket.
D
Explanation:
https://cloud.google.com/storage/docs/locations
Your agricultural division is experimenting with fully autonomous vehicles.
You want your architecture to promote strong security during vehicle operation.
Which two architecture should you consider? Choose 2 answers:
- A . Treat every micro service call between modules on the vehicle as untrusted.
- B . Require IPv6 for connectivity to ensure a secure address space.
- C . Use a trusted platform module (TPM) and verify firmware and binaries on boot.
- D . Use a functional programming language to isolate code execution cycles.
- E . Use multiple connectivity subsystems for redundancy.
- F . Enclose the vehicle’s drive electronics in a Faraday cage to isolate chips.
For this question, refer to the TerramEarth case study.
The TerramEarth development team wants to create an API to meet the company’s business requirements. You want the development team to focus their development effort on business value versus creating a custom framework .
Which method should they use?
- A . Use Google App Engine with Google Cloud Endpoints. Focus on an API for dealers and partners.
- B . Use Google App Engine with a JAX-RS Jersey Java-based framework. Focus on an API for the public.
- C . Use Google App Engine with the Swagger (open API Specification) framework. Focus on an API for the public.
- D . Use Google Container Engine with a Django Python container. Focus on an API for the public.
- E . Use Google Container Engine with a Tomcat container with the Swagger (Open API Specification) framework. Focus on an API for dealers and partners.
A
Explanation:
For this question, refer to the TerramEarth case study
Your development team has created a structured API to retrieve vehicle data. They want to allow third parties to develop tools for dealerships that use this vehicle event data. You want to support delegated authorization against this data .
What should you do?
- A . Build or leverage an OAuth-compatible access control system.
- B . Build SAML 2.0 SSO compatibility into your authentication system.
- C . Restrict data access based on the source IP address of the partner systems.
- D . Create secondary credentials for each dealer that can be given to the trusted third party.
A
Explanation:
https://cloud.google.com/appengine/docs/flexible/go/authorizing-apps
https://cloud.google.com/docs/enterprise/best-practices-for-enterprise-organizations#delegate_application_authorization_with_oauth2
Delegate application authorization with OAuth2
Cloud Platform APIs support OAuth 2.0, and scopes provide granular authorization over the methods that are supported. Cloud Platform supports both service-account and user-account OAuth, also called three-legged OAuth.
References: https://cloud.google.com/docs/enterprise/best-practices-for-enterprise-organizations#delegate_application_authorization_with_oauth2 https://cloud.google.com/appengine/docs/flexible/go/authorizing-apps
Topic 3, JencoMart Case Study
Company Overview
JencoMart is a global retailer with over 10,000 stores in 16 countries. The stores carry a range of goods, such as groceries, tires, and jewelry. One of the company’s core values is excellent customer service. In addition, they recently introduced an environmental policy to reduce their carbon output by 50% over the next 5 years.
Company Background
JencoMart started as a general store in 1931, and has grown into one of the world’s leading brands, known for great value and customer service. Over time, the company transitioned from only physical stores to a stores and online hybrid model, with 25% of sales online. Currently, JencoMart has little presence in Asia, but considers that market key for future growth.
Solution Concept
JencoMart wants to migrate several critical applications to the cloud but has not completed a technical review to determine their suitability for the cloud and the engineering required for migration. They currently host all of these applications on infrastructure that is at its end of life and is no longer supported.
Existing Technical Environment
JencoMart hosts all of its applications in 4 data centers: 3 in North American and 1 in Europe; most applications are dual-homed.
JencoMart understands the dependencies and resource usage metrics of their on-premises architecture.
Application: Customer loyalty portal
LAMP (Linux, Apache, MySQL and PHP) application served from the two JencoMart-owned U.S. data centers.
Database
– Oracle Database stores user profiles
– 20 TB
– Complex table structure
– Well maintained, clean data
– Strong backup strategy
– PostgreSQL database stores user credentials
– Single-homed in US West
– No redundancy
– Backed up every 12 hours
– 100% uptime service level agreement (SLA)
– Authenticates all users
Compute
– 30 machines in US West Coast, each machine has:
– Twin, dual core CPUs
– 32 GB of RAM
– Twin 250 GB HDD (RAID 1)
– 20 machines in US East Coast, each machine has:
– Single, dual-core CPU
– 24 GB of RAM
– Twin 250 GB HDD (RAID 1)
Storage
– Access to shared 100 TB SAN in each location
– Tape backup every week
Business Requirements
– Optimize for capacity during peak periods and value during off-peak periods
– Guarantee service availability and support
– Reduce on-premises footprint and associated financial and environmental impact
– Move to outsourcing model to avoid large upfront costs associated with infrastructure purchase
– Expand services into Asia
Technical Requirements
– Assess key application for cloud suitability
– Modify applications for the cloud
– Move applications to a new infrastructure
– Leverage managed services wherever feasible
– Sunset 20% of capacity in existing data centers
– Decrease latency in Asia
CEO Statement
JencoMart will continue to develop personal relationships with our customers as more people access the web. The future of our retail business is in the global market and the connection between online and in-store experiences. As a large, global company, we also have a responsibility to the environment through “green” initiatives and policies.
CTO Statement
The challenges of operating data centers prevent focus on key technologies critical to our long-term success. Migrating our data services to a public cloud infrastructure will allow us to focus on big data and machine learning to improve our service to customers.
CFO Statement
Since its founding, JencoMart has invested heavily in our data services infrastructure. However, because of changing market trends, we need to outsource our infrastructure to ensure our long-term success. This model will allow us to respond to increasing customer demand during peak periods and reduce costs.
For this question, refer to the JencoMart case study.
JencoMart has built a version of their application on Google Cloud Platform that serves traffic to Asia. You want to measure success against their business and technical goals .
Which metrics should you track?
- A . Error rates for requests from Asia
- B . Latency difference between US and Asia
- C . Total visits, error rates, and latency from Asia
- D . Total visits and average latency for users in Asia
- E . The number of character sets present in the database
For this question, refer to the JencoMart case study
A few days after JencoMart migrates the user credentials database to Google Cloud Platform and shuts down the old server, the new database server stops responding to SSH connections. It is still serving database requests to the application servers correctly .
What three steps should you take to diagnose the problem? Choose 3 answers
- A . Delete the virtual machine (VM) and disks and create a new one.
- B . Delete the instance, attach the disk to a new VM, and investigate.
- C . Take a snapshot of the disk and connect to a new machine to investigate.
- D . Check inbound firewall rules for the network the machine is connected to.
- E . Connect the machine to another network with very simple firewall rules and investigate.
- F . Print the Serial Console output for the instance for troubleshooting, activate the interactive console, and investigate.
C,D,F
Explanation:
https://cloud.google.com/compute/docs/troubleshooting/troubleshooting-ssh
D: Handling "Unable to connect on port 22" error message Possible causes include:
There is no firewall rule allowing SSH access on the port. SSH access on port 22 is enabled on all Compute Engine instances by default. If you have disabled access, SSH from the Browser will not work. If you run sshd on a port other than 22, you need to enable the access to that port with a custom firewall rule.
The firewall rule allowing SSH access is enabled, but is not configured to allow connections from GCP Console services. Source IP addresses for browser-based SSH sessions are dynamically allocated by GCP Console and can vary from session to session.
References:
https://cloud.google.com/compute/docs/ssh-in-browser
https://cloud.google.com/compute/docs/ssh-in-browser
For this question, refer to the JencoMart case study.
JencoMart has decided to migrate user profile storage to Google Cloud Datastore and the application servers to Google Compute Engine (GCE). During the migration, the existing infrastructure will need access to Datastore to upload the data .
What service account key-management strategy should you recommend?
- A . Provision service account keys for the on-premises infrastructure and for the GCE virtual machines (VMs).
- B . Authenticate the on-premises infrastructure with a user account and provision service account keys for the VMs.
- C . Provision service account keys for the on-premises infrastructure and use Google Cloud Platform (GCP) managed keys for the VMs
- D . Deploy a custom authentication service on GCE/Google Container Engine (GKE) for the on-premises infrastructure and use GCP managed keys for the VMs.
C
Explanation:
https://cloud.google.com/iam/docs/understanding-service-accounts
Migrating data to Google Cloud Platform
Let’s say that you have some data processing that happens on another cloud provider and you want to transfer the processed data to Google Cloud Platform. You can use a service account from the virtual machines on the external cloud to push the data to Google Cloud Platform. To do this, you must create and download a service account key when you create the service account and then use that key from the external process to call the Cloud Platform APIs.
References: https://cloud.google.com/iam/docs/understanding-service-accounts#migrating_data_to_google_cloud_platform
For this question, refer to the JencoMart case study.
The JencoMart security team requires that all Google Cloud Platform infrastructure is deployed using a least privilege model with separation of duties for administration between production and development resources .
What Google domain and project structure should you recommend?
- A . Create two G Suite accounts to manage users: one for development/test/staging and one for production. Each account should contain one project for every application.
- B . Create two G Suite accounts to manage users: one with a single project for all development applications and one with a single project for all production applications.
- C . Create a single G Suite account to manage users with each stage of each application in its own project.
- D . Create a single G Suite account to manage users with one project for the development/test/staging environment and one project for the production environment.
C
Explanation:
Note: The principle of least privilege and separation of duties are concepts that, although semantically different, are intrinsically related from the standpoint of security. The intent behind both is to prevent people from having higher privilege levels than they actually need
✑ Principle of Least Privilege: Users should only have the least amount of privileges required to perform their job and no more. This reduces authorization exploitation
by limiting access to resources such as targets, jobs, or monitoring templates for which they are not authorized.
✑ Separation of Duties: Beyond limiting user privilege level, you also limit user duties, or the specific jobs they can perform. No user should be given responsibility for more than one related function. This limits the ability of a user to perform a malicious action and then cover up that action.
References: https://cloud.google.com/kms/docs/separation-of-duties
For this question, refer to the JencoMart case study.
The migration of JencoMart’s application to Google Cloud Platform (GCP) is progressing too slowly. The infrastructure is shown in the diagram. You want to maximize throughput .
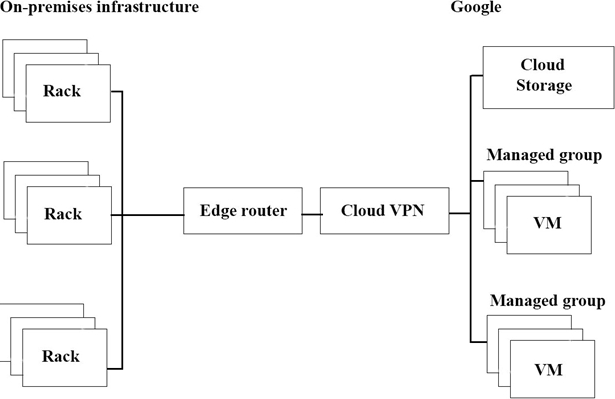

What are three potential bottlenecks? (Choose 3 answers.)
- A . A single VPN tunnel, which limits throughput
- B . A tier of Google Cloud Storage that is not suited for this task
- C . A copy command that is not suited to operate over long distances
- D . Fewer virtual machines (VMs) in GCP than on-premises machines
- E . A separate storage layer outside the VMs, which is not suited for this task
- F . Complicated internet connectivity between the on-premises infrastructure and GCP
For this question, refer to the JencoMart case study.
JencoMart wants to move their User Profiles database to Google Cloud Platform .
Which Google Database should they use?
- A . Cloud Spanner
- B . Google BigQuery
- C . Google Cloud SQL
- D . Google Cloud Datastore
D
Explanation:
https://cloud.google.com/datastore/docs/concepts/overview
Common workloads for Google Cloud Datastore:
✑ User profiles
✑ Product catalogs
✑ Game state
References: https://cloud.google.com/storage-options/ https://cloud.google.com/datastore/docs/concepts/overview
Topic 4, Dress4Win case study
Company Overview
Dress4win is a web-based company that helps their users organize and manage their personal wardrobe using a website and mobile application. The company also cultivates an active social network that connects their users with designers and retailers. They monetize their services through advertising, e-commerce, referrals, and a premium app model.
Company Background
Dress4win’s application has grown from a few servers in the founder’s garage to several hundred servers and appliances in a collocated data center. However, the capacity of their infrastructure is now insufficient for the application’s rapid growth. Because of this growth and the company’s desire to innovate faster, Dress4win is committing to a full migration to a public cloud.
Solution Concept
For the first phase of their migration to the cloud, Dress4win is considering moving their development and test environments. They are also considering building a disaster recovery site, because their current infrastructure is at a single location. They are not sure which components of their architecture they can migrate as is and which components they need to change before migrating them.
Existing Technical Environment
The Dress4win application is served out of a single data center location.
– Databases:
– MySQL – user data, inventory, static data
– Redis – metadata, social graph, caching
– Application servers:
– Tomcat – Java micro-services
– Nginx – static content
– Apache Beam – Batch processing
– Storage appliances:
– iSCSI for VM hosts
– Fiber channel SAN – MySQL databases
– NAS – image storage, logs, backups
– Apache Hadoop/Spark servers:
– Data analysis
– Real-time trending calculations
– MQ servers:
– Messaging
– Social notifications
– Events
– Miscellaneous servers:
– Jenkins, monitoring, bastion hosts, security scanners
Business Requirements
– Build a reliable and reproducible environment with scaled parity of production.
– Improve security by defining and adhering to a set of security and Identity and Access Management (IAM) best practices for cloud.
– Improve business agility and speed of innovation through rapid provisioning of new resources.
– Analyze and optimize architecture for performance in the cloud.
– Migrate fully to the cloud if all other requirements are met.
Technical Requirements
– Evaluate and choose an automation framework for provisioning resources in cloud.
– Support failover of the production environment to cloud during an emergency.
– Identify production services that can migrate to cloud to save capacity.
– Use managed services whenever possible.
– Encrypt data on the wire and at rest.
– Support multiple VPN connections between the production data center and cloud environment.
CEO Statement
Our investors are concerned about our ability to scale and contain costs with our current infrastructure. They are also concerned that a new competitor could use a public cloud platform to offset their up-front investment and freeing them to focus on developing better features.
CTO Statement
We have invested heavily in the current infrastructure, but much of the equipment is approaching the end of its useful life. We are consistently waiting weeks for new gear to be racked before we can start new projects. Our traffic patterns are highest in the mornings and weekend evenings; during other times, 80% of our capacity is sitting idle.
CFO Statement
Our capital expenditure is now exceeding our quarterly projections. Migrating to the cloud will likely cause an initial increase in spending, but we expect to fully transition before our next hardware refresh cycle. Our total cost of ownership (TCO) analysis over the next 5 years puts a cloud strategy between 30 to 50% lower than our current model.
The current Dress4win system architecture has high latency to some customers because it is located in one data center.
As of a future evaluation and optimizing for performance in the cloud, Dresss4win wants to distribute it’s system architecture to multiple locations when Google cloud platform.
Which approach should they use?
- A . Use regional managed instance groups and a global load balancer to increase performance because the regional managed instance group can grow instances in each region separately based on traffic.
- B . Use a global load balancer with a set of virtual machines that forward the requests to a closer group of
virtual machines managed by your operations team. - C . Use regional managed instance groups and a global load balancer to increase reliability by providing
automatic failover between zones in different regions. - D . Use a global load balancer with a set of virtual machines that forward the requests to a closer group of
virtual machines as part of a separate managed instance groups.
Dress4win has end to end tests covering 100% of their endpoints.
They want to ensure that the move of cloud does not introduce any new bugs.
Which additional testing methods should the developers employ to prevent an outage?
- A . They should run the end to end tests in the cloud staging environment to determine if the code is working as intended.
- B . They should enable google stack driver debugger on the application code to show errors in the code
- C . They should add additional unit tests and production scale load tests on their cloud staging environment.
- D . They should add canary tests so developers can measure how much of an impact the new release causes to latency
For this question, refer to the Dress4Win case study.
Dress4Win has configured a new uptime check with Google Stackdriver for several of their legacy services. The Stackdriver dashboard is not reporting the services as healthy .
What should they do?
- A . Install the Stackdriver agent on all of the legacy web servers.
- B . In the Cloud Platform Console download the list of the uptime servers’ IP addresses and create an inbound firewall rule
- C . Configure their load balancer to pass through the User-Agent HTTP header when the value matches GoogleStackdriverMonitoring-UptimeChecks (https://cloud.google.com/monitoring)
- D . Configure their legacy web servers to allow requests that contain user-Agent HTTP header when the value matches GoogleStackdriverMonitoring― UptimeChecks (https://cloud.google.com/monitoring)
For this question, refer to the Dress4Win case study.
As part of their new application experience, Dress4Wm allows customers to upload images of themselves. The customer has exclusive control over who may view these images. Customers should be able to upload images with minimal latency and also be shown their images quickly on the main application page when they log in .
Which configuration should Dress4Win use?
- A . Store image files in a Google Cloud Storage bucket. Use Google Cloud Datastore to maintain metadata that maps each customer’s ID and their image files.
- B . Store image files in a Google Cloud Storage bucket. Add custom metadata to the uploaded images in Cloud Storage that contains the customer’s unique ID.
- C . Use a distributed file system to store customers’ images. As storage needs increase, add more persistent disks and/or nodes. Assign each customer a unique ID, which sets each file’s owner attribute, ensuring privacy of images.
- D . Use a distributed file system to store customers’ images. As storage needs increase, add more persistent disks and/or nodes. Use a Google Cloud SQL database to maintain metadata that maps each customer’s ID to their image files.
For this question, refer to the Dress4Win case study.
At Dress4Win, an operations engineer wants to create a tow-cost solution to remotely archive copies of database backup files. The database files are compressed tar files stored in their current data center .
How should he proceed?
- A . Create a cron script using gsutil to copy the files to a Coldline Storage bucket.
- B . Create a cron script using gsutil to copy the files to a Regional Storage bucket.
- C . Create a Cloud Storage Transfer Service Job to copy the files to a Coldline Storage bucket.
- D . Create a Cloud Storage Transfer Service job to copy the files to a Regional Storage bucket.
C
Explanation:
Follow these rules of thumb when deciding whether to use gsutil or Storage Transfer Service:
✑ When transferring data from an on-premises location, use gsutil.
✑ When transferring data from another cloud storage provider, use Storage Transfer Service.
✑ Otherwise, evaluate both tools with respect to your specific scenario.
Use this guidance as a starting point. The specific details of your transfer scenario will also help you determine which tool is more appropriate https://cloud.google.com/storage-transfer/docs/overview
For this question, refer to the Dress4Win case study.
As part of Dress4Win’s plans to migrate to the cloud, they want to be able to set up a managed logging and monitoring system so they can handle spikes in their traffic load. They want to ensure that:
• The infrastructure can be notified when it needs to scale up and down to handle the ebb and flow of usage throughout the day
• Their administrators are notified automatically when their application reports errors.
• They can filter their aggregated logs down in order to debug one piece of the application across many hosts
Which Google StackDriver features should they use?
- A . Logging, Alerts, Insights, Debug
- B . Monitoring, Trace, Debug, Logging
- C . Monitoring, Logging, Alerts, Error Reporting
- D . Monitoring, Logging, Debug, Error Report
For this question, refer to the Dress4Win case study.
Dress4Win has asked you to recommend machine types they should deploy their application servers to .
How should you proceed?
- A . Perform a mapping of the on-premises physical hardware cores and RAM to the nearest machine types in the cloud.
- B . Recommend that Dress4Win deploy application servers to machine types that offer the highest RAM to CPU ratio available.
- C . Recommend that Dress4Win deploy into production with the smallest instances available, monitor them over time, and scale the machine type up until the desired performance is reached.
- D . Identify the number of virtual cores and RAM associated with the application server virtual machines align them to a custom machine type in the cloud, monitor performance, and scale the machine types up until the desired performance is reached.
For this question, refer to the Dress4Win case study.
You want to ensure Dress4Win’s sales and tax records remain available for infrequent viewing by auditors for at least 10 years. Cost optimization is your top priority .
Which cloud services should you choose?
- A . Google Cloud Storage Coldline to store the data, and gsutil to access the data.
- B . Google Cloud Storage Nearline to store the data, and gsutil to access the data.
- C . Google Bigtabte with US or EU as location to store the data, and gcloud to access the data.
- D . BigQuery to store the data, and a web server cluster in a managed instance group to access the data. Google Cloud SQL mirrored across two distinct regions to store the data, and a Redis cluster in a managed instance group to access the data.
A
Explanation:
References: https://cloud.google.com/storage/docs/storage-classes
For this question, refer to the Dress4Win case study.
Dress4Win would like to become familiar with deploying applications to the cloud by successfully deploying some applications quickly, as is. They have asked for your recommendation .
What should you advise?
- A . Identify self-contained applications with external dependencies as a first move to the cloud.
- B . Identify enterprise applications with internal dependencies and recommend these as a first move to the cloud.
- C . Suggest moving their in-house databases to the cloud and continue serving requests to on-premise applications.
- D . Recommend moving their message queuing servers to the cloud and continue handling requests to on-premise applications.
A
Explanation:
https://cloud.google.com/blog/products/gcp/the-five-phases-of-migrating-to-google-cloud-platform
For this question, refer to the Dress4Win case study.
The Dress4Win security team has disabled external SSH access into production virtual machines (VMs) on Google Cloud Platform (GCP). The operations team needs to remotely manage the VMs, build and push Docker containers, and manage Google Cloud Storage objects .
What can they do?
- A . Grant the operations engineers access to use Google Cloud Shell.
- B . Configure a VPN connection to GCP to allow SSH access to the cloud VMs.
- C . Develop a new access request process that grants temporary SSH access to cloud VMs when an operations engineer needs to perform a task.
- D . Have the development team build an API service that allows the operations team to execute specific remote procedure calls to accomplish their tasks.
For this question, refer to the Dress4Win case study.
Dress4Win has asked you for advice on how to migrate their on-premises MySQL
deployment to the cloud. They want to minimize downtime and performance impact to their on-premises solution during the migration .
Which approach should you recommend?
- A . Create a dump of the on-premises MySQL master server, and then shut it down, upload it to the cloud environment, and load into a new MySQL cluster.
- B . Setup a MySQL replica server/slave in the cloud environment, and configure it for asynchronous replication from the MySQL master server on-premises until cutover.
- C . Create a new MySQL cluster in the cloud, configure applications to begin writing to both on-premises and cloud MySQL masters, and destroy the original cluster at cutover.
- D . Create a dump of the MySQL replica server into the cloud environment, load it into: Google Cloud Datastore, and configure applications to read/write to Cloud Datastore at cutover.
For this question, refer to the Dress4Win case study.
Dress4Win has end-to-end tests covering 100% of their endpoints. They want to ensure that the move to the cloud does not introduce any new bugs .
Which additional testing methods should the developers employ to prevent an outage?
- A . They should enable Google Stackdriver Debugger on the application code to show errors in the code.
- B . They should add additional unit tests and production scale load tests on their cloud staging environment.
- C . They should run the end-to-end tests in the cloud staging environment to determine if the code is working as intended.
- D . They should add canary tests so developers can measure how much of an impact the new release causes to latency.
Topic 5, Misc Questions
Your company has a Google Cloud project that uses BigQuery for data warehousing They
have a VPN tunnel between the on-premises environment and Google Cloud that is configured with Cloud VPN. The security team wants to avoid data exfiltration by malicious insiders, compromised code, and accidental oversharing .
What should they do?
- A . Configure Private Google Access for on-premises only.
- B . Perform the following tasks:
1) Create a service account.
2) Give the BigQuery JobUser role and Storage Reader role to the service account.
3) Remove all other IAM access from the project. - C . Configure VPC Service Controls and configure Private Google Access.
- D . Configure Private Google Access.
You need to develop procedures to verify resilience of disaster recovery for remote recovery using GCP. Your production environment is hosted on-premises. You need to establish a secure, redundant connection between your on premises network and the GCP network.
What should you do?
- A . Verify that Dedicated Interconnect can replicate files to GCP. Verify that direct peering can establish a
secure connection between your networks if Dedicated Interconnect fails. - B . Verify that Dedicated Interconnect can replicate files to GCP. Verify that Cloud VPN can establish a secure connection between your networks if Dedicated Interconnect fails.
- C . Verify that the Transfer Appliance can replicate files to GCP. Verify that direct peering can establish a
secure connection between your networks if the Transfer Appliance fails. - D . Verify that the Transfer Appliance can replicate files to GCP. Verify that Cloud VPN can establish a secure connection between your networks if the Transfer Appliance fails.
B
Explanation:
https://cloud.google.com/interconnect/docs/how-to/direct-peering
You are developing an application using different microservices that should remain internal to the cluster. You want to be able to configure each microservice with a specific number of replicas. You also want to be able to address a specific microservice from any other microservice in a uniform way, regardless of the number of replicas the microservice scales to. You need to implement this solution on Google Kubernetes Engine .
What should you do?
- A . Deploy each microservice as a Deployment. Expose the Deployment in the cluster using a Service, and use the Service DNS name to address it from other microservices within the cluster.
- B . Deploy each microservice as a Deployment. Expose the Deployment in the cluster using an Ingress, and use the Ingress IP address to address the Deployment from other microservices within the cluster.
- C . Deploy each microservice as a Pod. Expose the Pod in the cluster using a Service, and use the Service DNS name to address the microservice from other microservices within the cluster.
- D . Deploy each microservice as a Pod. Expose the Pod in the cluster using an Ingress, and use the Ingress IP address name to address the Pod from other microservices within the cluster.
A
Explanation:
https://kubernetes.io/docs/concepts/services-networking/ingress/
You have deployed several instances on Compute Engine. As a security requirement, instances cannot have a public IP address. There is no VPN connection between Google Cloud and your office, and you need to connect via SSH into a specific machine without violating the security requirements .
What should you do?
- A . Configure Cloud NAT on the subnet where the instance is hosted. Create an SSH connection to the Cloud NAT IP address to reach the instance.
- B . Add all instances to an unmanaged instance group. Configure TCP Proxy Load Balancing with the instance group as a backend. Connect to the instance using the TCP Proxy IP.
- C . Configure Identity-Aware Proxy (IAP) for the instance and ensure that you have the role of IAP-secured Tunnel User. Use the gcloud command line tool to ssh into the instance.
- D . Create a bastion host in the network to SSH into the bastion host from your office location. From the bastion host, SSH into the desired instance.
C
Explanation:
https://cloud.google.com/iap/docs/using-tcp-forwarding#tunneling_with_ssh
Leveraging the BeyondCorp security model. "This January, we enhanced context-aware access capabilities in Cloud Identity-Aware Proxy (IAP) to help you protect SSH and RDP access to your virtual machines (VMs)―without needing to provide your VMs with public IP addresses, and without having to set up bastion hosts. " https://cloud.google.com/blog/products/identity-security/cloud-iap-enables-context-aware-access-to-vms-via-ssh-and-rdp-without-bastion-hosts
Reference: https://cloud.google.com/solutions/connecting-securely
You need to reduce the number of unplanned rollbacks of erroneous production deployments in your company’s web hosting platform. Improvement to the QA/Test processes accomplished an 80% reduction .
Which additional two approaches can you take to further reduce the rollbacks? Choose 2 answers
- A . Introduce a green-blue deployment model.
- B . Replace the QA environment with canary releases.
- C . Fragment the monolithic platform into microservices.
- D . Reduce the platform’s dependency on relational database systems.
- E . Replace the platform’s relational database systems with a NoSQL database.
Your application needs to process credit card transactions. You want the smallest scope of Payment Card Industry (PCI) compliance without compromising the ability to analyze transactional data and trends relating to which payment methods are used .
How should you design your architecture?
- A . Create a tokenizer service and store only tokenized data.
- B . Create separate projects that only process credit card data.
- C . Create separate subnetworks and isolate the components that process credit card data.
- D . Streamline the audit discovery phase by labeling all of the virtual machines (VMs) that process PCI data.
- E . Enable Logging export to Google BigQuery and use ACLs and views to scope the data shared with the auditor.
A
Explanation:
https://cloud.google.com/solutions/pci-dss-compliance-in-gcp
Your company is moving 75 TB of data into Google Cloud. You want to use Cloud Storage and follow Googlerecommended practices .
What should you do?
- A . Move your data onto a Transfer Appliance. Use a Transfer Appliance Rehydrator to decrypt the data into Cloud Storage.
- B . Move your data onto a Transfer Appliance. Use Cloud Dataprep to decrypt the data into Cloud Storage.
- C . Install gsutil on each server that contains data. Use resumable transfers to upload the data into Cloud Storage.
- D . Install gsutil on each server containing data. Use streaming transfers to upload the data
into Cloud
Storage.
A
Explanation:
https://cloud.google.com/transfer-appliance/docs/2.0/faq
You have been asked to select the storage system for the click-data of your company’s large portfolio of websites. This data is streamed in from a custom website analytics package at a typical rate of 6,000 clicks per minute, with bursts of up to 8,500 clicks per second. It must been stored for future analysis by your data science and user experience
teams .
Which storage infrastructure should you choose?
- A . Google Cloud SQL
- B . Google Cloud Bigtable
- C . Google Cloud Storage
- D . Google cloud Datastore
C
Explanation:
https://cloud.google.com/bigquery/docs/loading-data-cloud-storage
You need to design a solution for global load balancing based on the URL path being requested. You need to ensure operations reliability and end-to-end in-transit encryption based on Google best practices.
What should you do?
- A . Create a cross-region load balancer with URL Maps.
- B . Create an HTTPS load balancer with URL maps.
- C . Create appropriate instance groups and instances. Configure SSL proxy load balancing.
- D . Create a global forwarding rule. Configure SSL proxy balancing.
B
Explanation:
Reference https://cloud.google.com/load-balancing/docs/https/url-map
You need to set up Microsoft SQL Server on GCP. Management requires that there’s no downtime in case of a data center outage in any of the zones within a GCP region .
What should you do?
- A . Configure a Cloud SQL instance with high availability enabled.
- B . Configure a Cloud Spanner instance with a regional instance configuration.
- C . Set up SQL Server on Compute Engine, using Always On Availability Groups using Windows Failover
Clustering. Place nodes in different subnets. - D . Set up SQL Server Always On Availability Groups using Windows Failover Clustering.
Place nodes in different zones.
D
Explanation:
https://cloud.google.com/sql/docs/sqlserver/configure-ha
You have developed a non-critical update to your application that is running in a managed instance group, and have created a new instance template with the update that you want to release. To prevent any possible impact to the application, you don’t want to update any running instances. You want any new instances that are created by the managed instance group to contain the new update .
What should you do?
- A . Start a new rolling restart operation.
- B . Start a new rolling replace operation.
- C . Start a new rolling update. Select the Proactive update mode.
- D . Start a new rolling update. Select the Opportunistic update mode.
D
Explanation:
In certain scenarios, an opportunistic update is useful because you don’t want to cause instability to the system if it can be avoided. For example, if you have a non-critical update that can be applied as necessary without any urgency and you have a MIG that is actively being autoscaled, perform an opportunistic update so that Compute Engine does not actively tear down your existing instances to apply the update. When resizing down, the autoscaler preferentially terminates instances with the old template as well as instances that are not yet in a RUNNING state.
Your company is developing a new application that will allow globally distributed users to
upload pictures and share them with other selected users. The application will support millions of concurrent users. You want to allow developers to focus on just building code without having to create and maintain the underlying infrastructure .
Which service should you use to deploy the application?
- A . App Engine
- B . Cloud Endpoints
- C . Compute Engine
- D . Google Kubernetes Engine
A
Explanation:
Reference:
https://cloud.google.com/terms/services
https://cloud.google.com/appengine/docs/standard/go/how-requests-are-handled
You have developed an application using Cloud ML Engine that recognizes famous paintings from uploaded images. You want to test the application and allow specific people to upload images for the next 24 hours. Not all users have a Google Account .
How should you have users upload images?
- A . Have users upload the images to Cloud Storage. Protect the bucket with a password that expires after 24 hours.
- B . Have users upload the images to Cloud Storage using a signed URL that expires after 24 hours.
- C . Create an App Engine web application where users can upload images. Configure App Engine to disable the application after 24 hours. Authenticate users via Cloud Identity.
- D . Create an App Engine web application where users can upload images for the next 24 hours. Authenticate users via Cloud Identity.
B
Explanation:
https://cloud.google.com/blog/products/storage-data-transfer/uploading-images-directly-to-cloud-storage-by-using-signed-url
Your development team has installed a new Linux kernel module on the batch servers in Google Compute Engine (GCE) virtual machines (VMs) to speed up the nightly batch process. Two days after the installation, 50% of web application deployed in the same
nightly batch run. You want to collect details on the failure to pass back to the development team .
Which three actions should you take? Choose 3 answers
- A . Use Stackdriver Logging to search for the module log entries.
- B . Read the debug GCE Activity log using the API or Cloud Console.
- C . Use gcloud or Cloud Console to connect to the serial console and observe the logs.
- D . Identify whether a live migration event of the failed server occurred, using in the activity log.
- E . Adjust the Google Stackdriver timeline to match the failure time, and observe the batch server metrics.
- F . Export a debug VM into an image, and run the image on a local server where kernel log messages will be displayed on the native screen.
A,C,E
Explanation:
https://www.flexera.com/blog/cloud/2013/12/google-compute-engine-live-migration-passes-the-test/
"With live migration, the virtual machines are moved without any downtime or noticeable service degradation"
You want to enable your running Google Kubernetes Engine cluster to scale as demand for your application changes.
What should you do?
- A . Add additional nodes to your Kubernetes Engine cluster using the following command:
gcloud container clusters resize
CLUSTER_Name C -size 10 - B . Add a tag to the instances in the cluster with the following command:
gcloud compute instances add-tags
INSTANCE – -tags enable-
autoscaling max-nodes-10 - C . Update the existing Kubernetes Engine cluster with the following command:
gcloud alpha container clusters
update mycluster – -enable
autoscaling – -min-nodes=1 – -max-nodes=10 - D . Create a new Kubernetes Engine cluster with the following command:
gcloud alpha container clusters
create mycluster – -enable-
autoscaling – -min-nodes=1 – -max-nodes=10
and redeploy your application
C
Explanation:
https://cloud.google.com/kubernetes-engine/docs/concepts/cluster-autoscaler
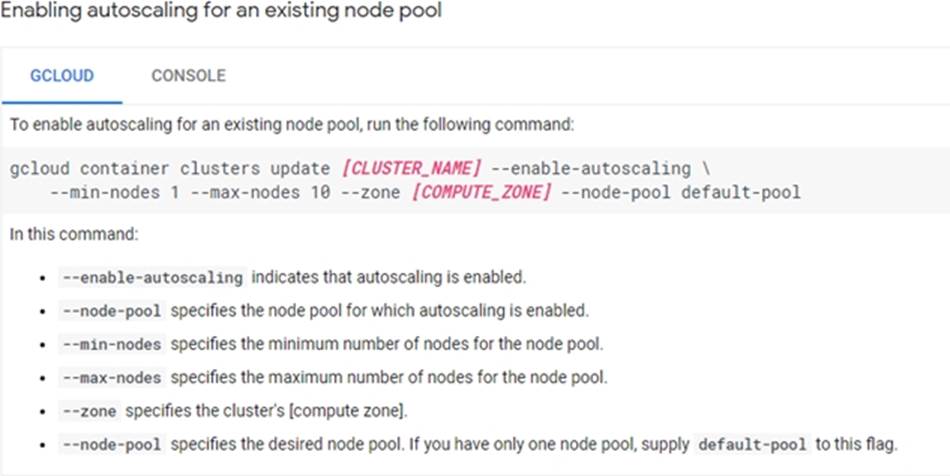

You are tasked with building an online analytical processing (OLAP) marketing analytics and reporting tool.
This requires a relational database that can operate on hundreds of terabytes of data .
What is the Google recommended tool for such applications?
- A . Cloud Spanner, because it is globally distributed
- B . Cloud SQL, because it is a fully managed relational database
- C . Cloud Firestore, because it offers real-time synchronization across devices
- D . BigQuery, because it is designed for large-scale processing of tabular data
D
Explanation:
Reference: https://cloud.google.com/files/BigQueryTechnicalWP.pdf
You want to automate the creation of a managed instance group and a startup script to install the OS package dependencies. You want to minimize the startup time for VMs in the instance group.
What should you do?
- A . Use Terraform to create the managed instance group and a startup script to install the
OS package
dependencies. - B . Create a custom VM image with all OS package dependencies. Use Deployment
Manager to create the managed instance group with the VM image. - C . Use Puppet to create the managed instance group and install the OS package dependencies.
- D . Use Deployment Manager to create the managed instance group and Ansible to install the OS package dependencies.
B
Explanation:
"Custom images are more deterministic and start more quickly than instances with startup scripts. However, startup scripts are more flexible and let you update the apps and settings in your instances more easily."
https://cloud.google.com/compute/docs/instance-templates/create-instance-templates#using_custom_or_public_images_in_your_instance_templates
The operations manager asks you for a list of recommended practices that she should consider when migrating a J2EE application to the cloud .
Which three practices should you recommend? Choose 3 answers
- A . Port the application code to run on Google App Engine.
- B . Integrate Cloud Dataflow into the application to capture real-time metrics.
- C . Instrument the application with a monitoring tool like Stackdriver Debugger.
- D . Select an automation framework to reliably provision the cloud infrastructure.
- E . Deploy a continuous integration tool with automated testing in a staging environment.
- F . Migrate from MySQL to a managed NoSQL database like Google Cloud Datastore or Bigtable.
A,E,F
Explanation:
References:
https://cloud.google.com/appengine/docs/standard/java/tools/uploadinganapp https://cloud.google.com/appengine/docs/standard/java/building-app/cloud-sql
Your customer is moving an existing corporate application to Google Cloud Platform from an on-premises data center. The business owners require minimal user disruption. There are strict security team requirements for storing passwords .
What authentication strategy should they use?
- A . Use G Suite Password Sync to replicate passwords into Google.
- B . Federate authentication via SAML 2.0 to the existing Identity Provider.
- C . Provision users in Google using the Google Cloud Directory Sync tool.
- D . Ask users to set their Google password to match their corporate password.
B
Explanation:
https://cloud.google.com/solutions/authenticating-corporate-users-in-a-hybrid-environment
Your applications will be writing their logs to BigQuery for analysis. Each application should have its own table.
Any logs older than 45 days should be removed. You want to optimize storage and follow Google recommended practices .
What should you do?
- A . Configure the expiration time for your tables at 45 days
- B . Make the tables time-partitioned, and configure the partition expiration at 45 days
- C . Rely on BigQuery’s default behavior to prune application logs older than 45 days
- D . Create a script that uses the BigQuery command line tool (bq) to remove records older than 45 days
B
Explanation:
https://cloud.google.com/bigquery/docs/managing-partitioned-tables
Your web application uses Google Kubernetes Engine to manage several workloads. One workload requires a consistent set of hostnames even after pod scaling and relaunches.
Which feature of Kubernetes should you use to accomplish this?
- A . StatefulSets
- B . Role-based access control
- C . Container environment variables
- D . Persistent Volumes
A
Explanation:
https://kubernetes.io/docs/tutorials/stateful-application/basic-stateful-set/
A lead software engineer tells you that his new application design uses websockets and HTTP sessions that are not distributed across the web servers. You want to help him ensure his application will run property on Google Cloud Platform .
What should you do?
- A . Help the engineer to convert his websocket code to use HTTP streaming.
- B . Review the encryption requirements for websocket connections with the security team.
- C . Meet with the cloud operations team and the engineer to discuss load balancer options.
- D . Help the engineer redesign the application to use a distributed user session service that does not rely on websockets and HTTP sessions.
C
Explanation:
Google Cloud Platform (GCP) HTTP(S) load balancing provides global load balancing for HTTP(S) requests destined for your instances.
The HTTP(S) load balancer has native support for the WebSocket protocol.
You are using Cloud CDN to deliver static HTTP(S) website content hosted on a Compute Engine instance group. You want to improve the cache hit ratio.
What should you do?
- A . Customize the cache keys to omit the protocol from the key.
- B . Shorten the expiration time of the cached objects.
- C . Make sure the HTTP(S) header “Cache-Region” points to the closest region of your users.
- D . Replicate the static content in a Cloud Storage bucket. Point CloudCDN toward a load balancer on that bucket.
A
Explanation:
Reference https://cloud.google.com/cdn/docs/bestpractices#using_custom_cache_keys_to_improve_cache_hit_ratio
You are working at a financial institution that stores mortgage loan approval documents on Cloud Storage. Any change to these approval documents must be uploaded as a separate approval file, so you want to ensure that these documents cannot be deleted or overwritten for the next 5 years .
What should you do?
- A . Create a retention policy on the bucket for the duration of 5 years. Create a lock on the retention policy.
- B . Create the bucket with uniform bucket-level access, and grant a service account the role of Object Writer. Use the service account to upload new files.
- C . Use a customer-managed key for the encryption of the bucket. Rotate the key after 5 years.
- D . Create the bucket with fine-grained access control, and grant a service account the role of Object Writer. Use the service account to upload new files.
A
Explanation:
Reference: https://cloud.google.com/storage/docs/using-bucket-lock
Your company is developing a web-based application. You need to make sure that production deployments are linked to source code commits and are fully auditable .
What should you do?
- A . Make sure a developer is tagging the code commit with the date and time of commit
- B . Make sure a developer is adding a comment to the commit that links to the deployment.
- C . Make the container tag match the source code commit hash.
- D . Make sure the developer is tagging the commits with: latest
You have been engaged by your client to lead the migration of their application infrastructure to GCP. One of their current problems is that the on-premises high performance SAN is requiring frequent and expensive upgrades to keep up with the variety of workloads that are identified as follows: 20TB of log archives retained for legal reasons; 500 GB of VM boot/data volumes and templates; 500 GB of image thumbnails; 200 GB of customer session state data that allows customers to restart sessions even if off-line for several days.
Which of the following best reflects your recommendations for a cost-effective storage allocation?
- A . Local SSD for customer session state datA. Lifecycle-managed Cloud Storage for log archives, thumbnails, and VM boot/data volumes.
- B . Memcache backed by Cloud Datastore for the customer session state datA. Lifecycle-managed Cloud
Storage for log archives, thumbnails, and VM boot/data volumes. - C . Memcache backed by Cloud SQL for customer session state datA. Assorted local SSD-backed instances for VM boot/data volumes. Cloud Storage for log archives and thumbnails.
- D . Memcache backed by Persistent Disk SSD storage for customer session state datA. Assorted local SSDbacked instances for VM boot/data volumes. Cloud Storage for log archives and thumbnails.
B
Explanation:
https://cloud.google.com/compute/docs/disks
Your company has an application deployed on Anthos clusters (formerly Anthos GKE) that is running multiple microservices. The cluster has both Anthos Service Mesh and Anthos Config Management configured. End users inform you that the application is responding very slowly. You want to identify the microservice that is causing the delay .
What should you do?
- A . Use the Service Mesh visualization in the Cloud Console to inspect the telemetry between the microservices.
- B . Use Anthos Config Management to create a ClusterSelector selecting the relevant cluster. On the Google Cloud Console page for Google Kubernetes Engine, view the Workloads and filter on the cluster. Inspect the configurations of the filtered workloads.
- C . Use Anthos Config Management to create a namespaceSelector selecting the relevant cluster namespace. On the Google Cloud Console page for Google Kubernetes Engine, visit the workloads and filter on the namespace. Inspect the configurations of the filtered workloads.
- D . Reinstall istio using the default istio profile in order to collect request latency. Evaluate the telemetry between the microservices in the Cloud Console.
A
Explanation:
The Anthos Service Mesh pages in the Google Cloud Console provide both summary and in-depth metrics, charts, and graphs that enable you to observe service behavior. You can monitor the overall health of your services, or drill down on a specific service to set a service level objective (SLO) or troubleshoot an issue.
https://cloud.google.com/service-mesh/docs/observability/explore-dashboard
https://cloud.google.com/anthos/service-mesh
Your company pushes batches of sensitive transaction data from its application server VMs to Cloud Pub/Sub for processing and storage .
What is the Google-recommended way for your application to authenticate to the required Google Cloud services?
- A . Ensure that VM service accounts are granted the appropriate Cloud Pub/Sub IAM roles.
- B . Ensure that VM service accounts do not have access to Cloud Pub/Sub, and use VM access scopes to
grant the appropriate Cloud Pub/Sub IAM roles. - C . Generate an OAuth2 access token for accessing Cloud Pub/Sub, encrypt it, and store it
in Cloud Storage for access from each VM. - D . Create a gateway to Cloud Pub/Sub using a Cloud Function, and grant the Cloud Function service account the appropriate Cloud Pub/Sub IAM roles.
Your company pushes batches of sensitive transaction data from its application server VMs to Cloud Pub/Sub for processing and storage .
What is the Google-recommended way for your application to authenticate to the required Google Cloud services?
- A . Ensure that VM service accounts are granted the appropriate Cloud Pub/Sub IAM roles.
- B . Ensure that VM service accounts do not have access to Cloud Pub/Sub, and use VM access scopes to
grant the appropriate Cloud Pub/Sub IAM roles. - C . Generate an OAuth2 access token for accessing Cloud Pub/Sub, encrypt it, and store it
in Cloud Storage for access from each VM. - D . Create a gateway to Cloud Pub/Sub using a Cloud Function, and grant the Cloud Function service account the appropriate Cloud Pub/Sub IAM roles.
Your company pushes batches of sensitive transaction data from its application server VMs to Cloud Pub/Sub for processing and storage .
What is the Google-recommended way for your application to authenticate to the required Google Cloud services?
- A . Ensure that VM service accounts are granted the appropriate Cloud Pub/Sub IAM roles.
- B . Ensure that VM service accounts do not have access to Cloud Pub/Sub, and use VM access scopes to
grant the appropriate Cloud Pub/Sub IAM roles. - C . Generate an OAuth2 access token for accessing Cloud Pub/Sub, encrypt it, and store it
in Cloud Storage for access from each VM. - D . Create a gateway to Cloud Pub/Sub using a Cloud Function, and grant the Cloud Function service account the appropriate Cloud Pub/Sub IAM roles.
Your company pushes batches of sensitive transaction data from its application server VMs to Cloud Pub/Sub for processing and storage .
What is the Google-recommended way for your application to authenticate to the required Google Cloud services?
- A . Ensure that VM service accounts are granted the appropriate Cloud Pub/Sub IAM roles.
- B . Ensure that VM service accounts do not have access to Cloud Pub/Sub, and use VM access scopes to
grant the appropriate Cloud Pub/Sub IAM roles. - C . Generate an OAuth2 access token for accessing Cloud Pub/Sub, encrypt it, and store it
in Cloud Storage for access from each VM. - D . Create a gateway to Cloud Pub/Sub using a Cloud Function, and grant the Cloud Function service account the appropriate Cloud Pub/Sub IAM roles.
Your company pushes batches of sensitive transaction data from its application server VMs to Cloud Pub/Sub for processing and storage .
What is the Google-recommended way for your application to authenticate to the required Google Cloud services?
- A . Ensure that VM service accounts are granted the appropriate Cloud Pub/Sub IAM roles.
- B . Ensure that VM service accounts do not have access to Cloud Pub/Sub, and use VM access scopes to
grant the appropriate Cloud Pub/Sub IAM roles. - C . Generate an OAuth2 access token for accessing Cloud Pub/Sub, encrypt it, and store it
in Cloud Storage for access from each VM. - D . Create a gateway to Cloud Pub/Sub using a Cloud Function, and grant the Cloud Function service account the appropriate Cloud Pub/Sub IAM roles.
Your company pushes batches of sensitive transaction data from its application server VMs to Cloud Pub/Sub for processing and storage .
What is the Google-recommended way for your application to authenticate to the required Google Cloud services?
- A . Ensure that VM service accounts are granted the appropriate Cloud Pub/Sub IAM roles.
- B . Ensure that VM service accounts do not have access to Cloud Pub/Sub, and use VM access scopes to
grant the appropriate Cloud Pub/Sub IAM roles. - C . Generate an OAuth2 access token for accessing Cloud Pub/Sub, encrypt it, and store it
in Cloud Storage for access from each VM. - D . Create a gateway to Cloud Pub/Sub using a Cloud Function, and grant the Cloud Function service account the appropriate Cloud Pub/Sub IAM roles.
Your company pushes batches of sensitive transaction data from its application server VMs to Cloud Pub/Sub for processing and storage .
What is the Google-recommended way for your application to authenticate to the required Google Cloud services?
- A . Ensure that VM service accounts are granted the appropriate Cloud Pub/Sub IAM roles.
- B . Ensure that VM service accounts do not have access to Cloud Pub/Sub, and use VM access scopes to
grant the appropriate Cloud Pub/Sub IAM roles. - C . Generate an OAuth2 access token for accessing Cloud Pub/Sub, encrypt it, and store it
in Cloud Storage for access from each VM. - D . Create a gateway to Cloud Pub/Sub using a Cloud Function, and grant the Cloud Function service account the appropriate Cloud Pub/Sub IAM roles.
Migrate all virtual machines into Compute Engine.
Explanation:
The framework illustrated in the preceding diagram has four phases:
• Assess. In this phase, you assess your source environment, assess the workloads that you want to migrate to Google Cloud, and assess which VMs support each workload.
• Plan. In this phase, you create the basic infrastructure for Migrate for Compute Engine, such as provisioning the resource hierarchy and setting up network access.
• Deploy. In this phase, you migrate the VMs from the source environment to Compute Engine.
• Optimize. In this phase, you begin to take advantage of the cloud technologies and capabilities.
Reference: https://cloud.google.com/architecture/migrating-vms-migrate-for-compute-engine-getting-started
Your organization requires that metrics from all applications be retained for 5 years for future analysis in possible legal proceedings .
Which approach should you use?
- A . Grant the security team access to the logs in each Project.
- B . Configure Stackdriver Monitoring for all Projects, and export to BigQuery.
- C . Configure Stackdriver Monitoring for all Projects with the default retention policies.
- D . Configure Stackdriver Monitoring for all Projects, and export to Google Cloud Storage.
D
Explanation:
Overview of storage classes, price, and use cases https://cloud.google.com/storage/docs/storage-classes
Why export logs? https://cloud.google.com/logging/docs/export/
StackDriver Quotas and Limits for Monitoring https://cloud.google.com/monitoring/quotas
The BigQuery pricing. https://cloud.google.com/bigquery/pricing
You created a pipeline that can deploy your source code changes to your infrastructure in instance groups for self healing.
One of the changes negatively affects your key performance indicator.
You are not sure how to fix it and investigation could take up to a week.
What should you do?
- A . Log in to a server, and iterate a fix locally
- B . Change the instance group template to the previous one, and delete all instances.
- C . Revert the source code change and rerun the deployment pipeline
- D . Log into the servers with the bad code change, and swap in the previous code
Your company is designing its application landscape on Compute Engine. Whenever a zonal outage occurs, the application should be restored in another zone as quickly as possible with the latest application data. You need to design the solution to meet this requirement .
What should you do?
- A . Create a snapshot schedule for the disk containing the application data. Whenever a zonal outage occurs, use the latest snapshot to restore the disk in the same zone.
- B . Configure the Compute Engine instances with an instance template for the application, and use a regional persistent disk for the application data. Whenever a zonal outage occurs, use the instance template to spin up the application in another zone in the same region. Use the regional persistent disk for the application data.
- C . Create a snapshot schedule for the disk containing the application data. Whenever a zonal outage occurs, use the latest snapshot to restore the disk in another zone within the same region.
- D . Configure the Compute Engine instances with an instance template for the application, and use a regional persistent disk for the application data. Whenever a zonal outage occurs, use the instance template to spin up the application in another region. Use the regional persistent disk for the application data,
B
Explanation:
Regional persistent disk is a storage option that provides synchronous replication of data between two zones in a region. Regional persistent disks can be a good building block to use when you implement HA services in Compute Engine. https://cloud.google.com/compute/docs/disks/high-availability-regional-persistent-disk
You team needs to create a Google Kubernetes Engine (GKE) cluster to host a newly built application that requires access to third-party services on the internet. Your company does not allow any Compute Engine instance to have a public IP address on Google Cloud. You need to create a deployment strategy that adheres to these guidelines .
What should you do?
- A . Create a Compute Engine instance, and install a NAT Proxy on the instance. Configure all workloads on GKE to pass through this proxy to access third-party services on the Internet
- B . Configure the GKE cluster as a private cluster, and configure Cloud NAT Gateway for the cluster subnet
- C . Configure the GKE cluster as a route-based cluster. Configure Private Google Access on the Virtual Private Cloud (VPC)
- D . Configure the GKE cluster as a private cluster. Configure Private Google Access on the Virtual Private Cloud (VPC)
B
Explanation:
A Cloud NAT gateway can perform NAT for nodes and Pods in a private cluster, which is a type of VPC-native cluster. The Cloud NAT gateway must be configured to apply to at least the following subnet IP address ranges for the subnet that your cluster uses:
Subnet primary IP address range (used by nodes)
Subnet secondary IP address range used for Pods in the cluster Subnet secondary IP address range used for Services in the cluster
The simplest way to provide NAT for an entire private cluster is to configure a Cloud NAT gateway to apply to all of the cluster’s subnet’s IP address ranges. https://cloud.google.com/nat/docs/overview
Your customer support tool logs all email and chat conversations to Cloud Bigtable for retention and analysis.
What is the recommended approach for sanitizing this data of personally identifiable information or payment card information before initial storage?
- A . Hash all data using SHA256
- B . Encrypt all data using elliptic curve cryptography
- C . De-identify the data with the Cloud Data Loss Prevention API
- D . Use regular expressions to find and redact phone numbers, email addresses, and credit card numbers
C
Explanation:
Reference: https://cloud.google.com/solutions/pci-dss-compliance-ingcp#
You are managing an application deployed on Cloud Run for Anthos, and you need to define a strategy for deploying new versions of the application. You want to evaluate the new code with a subset of production traffic to decide whether to proceed with the rollout .
What should you do?
- A . Deploy a new revision to Cloud Run with the new version. Configure traffic percentage between revisions.
- B . Deploy a new service to Cloud Run with the new version. Add a Cloud Load Balancing instance in front of both services.
- C . In the Google Cloud Console page for Cloud Run, set up continuous deployment using Cloud Build for the development branch. As part of the Cloud Build trigger, configure the substitution variable TRAFFIC_PERCENTAGE with the percentage of traffic you want directed to a new version.
- D . In the Google Cloud Console, configure Traffic Director with a new Service that points to the new version of the application on Cloud Run. Configure Traffic Director to send a small percentage of traffic to the new version of the application.
A
Explanation:
https://cloud.google.com/run/docs/rollouts-rollbacks-traffic-migration
Your architecture calls for the centralized collection of all admin activity and VM system logs within your project.
How should you collect these logs from both VMs and services?
- A . All admin and VM system logs are automatically collected by Stackdriver.
- B . Stackdriver automatically collects admin activity logs for most services. The Stackdriver Logging agent must be installed on each instance to collect system logs.
- C . Launch a custom syslogd compute instance and configure your GCP project and VMs to forward all logs to it.
- D . Install the Stackdriver Logging agent on a single compute instance and let it collect all audit and access logs for your environment.
B
Explanation:
https://cloud.google.com/logging/docs/agent/default-logs
Your customer is receiving reports that their recently updated Google App Engine application is taking approximately 30 seconds to load for some of their users. This behavior was not reported before the update .
What strategy should you take?
- A . Work with your ISP to diagnose the problem.
- B . Open a support ticket to ask for network capture and flow data to diagnose the problem, then roll back your application.
- C . Roll back to an earlier known good release initially, then use Stackdriver Trace and logging to diagnose the problem in a development/test/staging environment.
- D . Roll back to an earlier known good release, then push the release again at a quieter period to investigate. Then use Stackdriver Trace and logging to diagnose the problem.
C
Explanation:
Stackdriver Logging allows you to store, search, analyze, monitor, and alert on log data and events from Google Cloud Platform and Amazon Web Services (AWS). Our API also allows ingestion of any custom log data from any source. Stackdriver Logging is a fully managed service that performs at scale and can ingest application and system log data from thousands of VMs. Even better, you can analyze all that log data in real time.
References: https://cloud.google.com/logging/
Your organization wants to control IAM policies for different departments independently, but centrally.
Which approach should you take?
- A . Multiple Organizations with multiple Folders
- B . Multiple Organizations, one for each department
- C . A single Organization with Folder for each department
- D . A single Organization with multiple projects, each with a central owner
C
Explanation:
Folders are nodes in the Cloud Platform Resource Hierarchy. A folder can contain projects, other folders, or a combination of both. You can use folders to group projects under an organization in a hierarchy. For example, your organization might contain multiple departments, each with its own set of GCP resources. Folders allow you to group these resources on a per-department basis. Folders are used to group resources that share common IAM policies. While a folder can contain multiple folders or resources, a given folder or resource can have exactly one parent.
References: https://cloud.google.com/resource-manager/docs/creating-managing-folders
You want to optimize the performance of an accurate, real-time, weather-charting application. The data comes from 50,000 sensors sending 10 readings a second, in the format of a timestamp and sensor reading. Where should you store the data?
- A . Google BigQuery
- B . Google Cloud SQL
- C . Google Cloud Bigtable
- D . Google Cloud Storage
C
Explanation:
It is time-series data, So Big Table. https://cloud.google.com/bigtable/docs/schema-design-time-series
Google Cloud Bigtable is a scalable, fully-managed NoSQL wide-column database that is suitable for both real-time access and analytics workloads.
Good for:
✑ Low-latency read/write access
✑ High-throughput analytics
✑ Native time series support
✑ Common workloads:
✑ IoT, finance, adtech
✑ Personalization, recommendations
✑ Monitoring
✑ Geospatial datasets
✑ Graphs
References: https://cloud.google.com/storage-options/
Your organization has a 3-tier web application deployed in the same network on Google Cloud Platform. Each tier (web, API, and database) scales independently of the others Network traffic should flow through the web to the API tier and then on to the database tier. Traffic should not flow between the web and the database tier .
How should you configure the network?
- A . Add each tier to a different subnetwork.
- B . Set up software based firewalls on individual VMs.
- C . Add tags to each tier and set up routes to allow the desired traffic flow.
- D . Add tags to each tier and set up firewall rules to allow the desired traffic flow.
D
Explanation:
https://aws.amazon.com/blogs/aws/building-three-tier-architectures-with-security-groups/
Google Cloud Platform (GCP) enforces firewall rules through rules and tags. GCP rules and tags can be defined once and used across all regions.
References:
https://cloud.google.com/docs/compare/openstack/ https://aws.amazon.com/it/blogs/aws/building-three-tier-architectures-with-security-groups/
You are running a cluster on Kubernetes Engine to serve a web application. Users are reporting that a specific part of the application is not responding anymore. You notice that all pods of your deployment keep restarting after 2 seconds. The application writes logs to standard output. You want to inspect the logs to find the cause of the issue .
Which approach can you take?
- A . Review the Stackdriver logs for each Compute Engine instance that is serving as a node in the cluster.
- B . Review the Stackdriver logs for the specific Kubernetes Engine container that is serving the unresponsive part of the application.
- C . Connect to the cluster using gcloud credentials and connect to a container in one of the pods to read the logs.
- D . Review the Serial Port logs for each Compute Engine instance that is serving as a node in the cluster.
One of the developers on your team deployed their application in Google Container Engine with the Dockerfile below.
They report that their application deployments are taking too long.


You want to optimize this Dockerfile for faster deployment times without adversely affecting the app’s functionality.
Which two actions should you take? Choose 2 answers.
- A . Remove Python after running pip.
- B . Remove dependencies from requirements.txt.
- C . Use a slimmed-down base image like Alpine linux.
- D . Use larger machine types for your Google Container Engine node pools.
- E . Copy the source after the package dependencies (Python and pip) are installed.
C,E
Explanation:
The speed of deployment can be changed by limiting the size of the uploaded app, limiting the complexity of the build necessary in the Dockerfile, if present, and by ensuring a fast and reliable internet connection.
Note: Alpine Linux is built around musl libc and busybox. This makes it smaller and more resource efficient than traditional GNU/Linux distributions. A container requires no more than 8 MB and a minimal installation to disk requires around 130 MB of storage. Not only do you get a fully-fledged Linux environment but a large selection of packages from the repository.
References:
https://groups.google.com/forum/#!topic/google-appengine/hZMEkmmObDU
https://www.alpinelinux.org/about/
You need to evaluate your team readiness for a new GCP project. You must perform the evaluation and create a skills gap plan incorporates the business goal of cost optimization. Your team has deployed two GCP projects successfully to date .
What should you do?
- A . Allocate budget for team training. Set a deadline for the new GCP project.
- B . Allocate budget for team training. Create a roadmap for your team to achieve Google Cloud certification based on job role.
- C . Allocate budget to hire skilled external consultants. Set a deadline for the new GCP project.
- D . Allocate budget to hire skilled external consultants. Create a roadmap for your team to achieve Google Cloud certification based on job role.
B
Explanation:
https://services.google.com/fh/files/misc/cloud_center_of_excellence.pdf
You are using Cloud Shell and need to install a custom utility for use in a few weeks.
Where can you store the file so it is in the default execution path and persists across sessions?
- A . ~/bin
- B . Cloud Storage
- C . /google/scripts
- D . /usr/local/bin
A
Explanation:
https://medium.com/google-cloud/no-localhost-no-problem-using-google-cloud-shell-as-my-full-time-development-environment-22d5a1942439
Your web application has several VM instances running within a VPC. You want to restrict communications between instances to only the paths and ports you authorize, but you don’t want to rely on static IP addresses or subnets because the app can autoscale .
How should you restrict communications?
- A . Use separate VPCs to restrict traffic
- B . Use firewall rules based on network tags attached to the compute instances
- C . Use Cloud DNS and only allow connections from authorized hostnames
- D . Use service accounts and configure the web application particular service accounts to have access
You deploy your custom java application to google app engine.
It fails to deploy and gives you the following stack trace:


- A . Recompile the CLoakedServlet class using and MD5 hash instead of SHA1
- B . Digitally sign all of your JAR files and redeploy your application.
- C . Upload missing JAR files and redeploy your application
Your company is building a new architecture to support its data-centric business focus. You are responsible for setting up the network. Your company’s mobile and web-facing applications will be deployed on-premises, and all data analysis will be conducted in GCP. The plan is to process and load 7 years of archived .csv files totaling 900 TB of data and then continue loading 10 TB of data daily. You currently have an existing 100-MB internet connection.
What actions will meet your company’s needs?
- A . Compress and upload both achieved files and files uploaded daily using the qsutil Cm option.
- B . Lease a Transfer Appliance, upload archived files to it, and send it, and send it to Google to transfer
archived data to Cloud Storage. Establish a connection with Google using a Dedicated Interconnect or
Direct Peering connection and use it to upload files daily. - C . Lease a Transfer Appliance, upload archived files to it, and send it, and send it to Google to transfer
archived data to Cloud Storage. Establish one Cloud VPN Tunnel to VPC networks over the public internet, and compares and upload files daily using the gsutil Cm option. - D . Lease a Transfer Appliance, upload archived files to it, and send it to Google to transfer archived data to Cloud Storage. Establish a Cloud VPN Tunnel to VPC networks over the public internet, and compress and upload files daily.
B
Explanation:
https://cloud.google.com/interconnect/docs/how-to/direct-peering
To reduce costs, the Director of Engineering has required all developers to move their development infrastructure resources from on-premises virtual machines (VMs) to Google Cloud Platform. These resources go through multiple start/stop events during the day and require state to persist. You have been asked to design the process of running a development environment in Google Cloud while providing cost visibility to the finance department .
Which two steps should you take? Choose 2 answers
- A . Use the –no-auto-delete flag on all persistent disks and stop the VM.
- B . Use the -auto-delete flag on all persistent disks and terminate the VM.
- C . Apply VM CPU utilization label and include it in the BigQuery billing export.
- D . Use Google BigQuery billing export and labels to associate cost to groups.
- E . Store all state into local SSD, snapshot the persistent disks, and terminate the VM.
- F . Store all state in Google Cloud Storage, snapshot the persistent disks, and terminate the VM.
A,D
Explanation:
https://cloud.google.com/billing/docs/how-to/export-data-bigquery
You write a Python script to connect to Google BigQuery from a Google Compute Engine virtual machine. The script is printing errors that it cannot connect to BigQuery .
What should you do to fix the script?
- A . Install the latest BigQuery API client library for Python
- B . Run your script on a new virtual machine with the BigQuery access scope enabled
- C . Create a new service account with BigQuery access and execute your script with that user
- D . Install the bq component for gccloud with the command gcloud components install bq.
B
Explanation:
The error is most like caused by the access scope issue. When create new instance, you have the default Compute engine default service account but most serves access including BigQuery is not enable. Create an instance Most access are not enabled by default You have default service account but don’t have the permission (scope) you can stop the instance, edit, change scope and restart it to enable the scope access. Of course, if you Run your script on a new virtual machine with the BigQuery access scope enabled, it also works
https://cloud.google.com/compute/docs/access/service-accounts
Your company’s test suite is a custom C++ application that runs tests throughout each day on Linux virtual machines. The full test suite takes several hours to complete, running on a limited number of on premises servers reserved for testing. Your company wants to move the testing infrastructure to the cloud, to reduce the amount of time it takes to fully test a change to the system, while changing the tests as little as possible .
Which cloud infrastructure should you recommend?
- A . Google Compute Engine unmanaged instance groups and Network Load Balancer
- B . Google Compute Engine managed instance groups with auto-scaling
- C . Google Cloud Dataproc to run Apache Hadoop jobs to process each test
- D . Google App Engine with Google Stackdriver for logging
B
Explanation:
https://cloud.google.com/compute/docs/instance-groups/
Google Compute Engine enables users to launch virtual machines (VMs) on demand. VMs can be launched from the standard images or custom images created by users.
Managed instance groups offer autoscaling capabilities that allow you to automatically add or remove instances from a managed instance group based on increases or decreases in load. Autoscaling helps your applications gracefully handle increases in traffic and reduces cost when the need for resources is lower.
The application reliability team at your company has added a debug feature to their backend service to send all server events to Google Cloud Storage for eventual analysis. The event records are at least 50 KB and at most 15 MB and are expected to peak at 3,000 events per second. You want to minimize data loss.
Which process should you implement?
- A . • Append metadata to file body.
• Compress individual files.
• Name files with serverName-Timestamp.
• Create a new bucket if bucket is older than 1 hour and save individual files to the new bucket. Otherwise, save files to existing bucket - B . • Batch every 10,000 events with a single manifest file for metadata.
• Compress event files and manifest file into a single archive file.
• Name files using serverName-EventSequence.
• Create a new bucket if bucket is older than 1 day and save the single archive file to the new bucket. Otherwise, save the single archive file to existing bucket. - C . • Compress individual files.
• Name files with serverName-EventSequence.
• Save files to one bucket
• Set custom metadata headers for each object after saving. - D . • Append metadata to file body.
• Compress individual files.
• Name files with a random prefix pattern.
• Save files to one bucket
D
Explanation:
In order to maintain a high request rate, avoid using sequential names. Using completely random object names will give you the best load distribution. Randomness after a common prefix is effective under the prefix
https://cloud.google.com/storage/docs/request-rate
You need to deploy an application on Google Cloud that must run on a Debian Linux environment. The application requires extensive configuration in order to operate correctly. You want to ensure that you can install Debian distribution updates with minimal manual intervention whenever they become available .
What should you do?
- A . Create a Compute Engine instance template using the most recent Debian image. Create an instance from this template, and install and configure the application as part of the startup script. Repeat this process whenever a new Google-managed Debian image becomes available.
- B . Create a Debian-based Compute Engine instance, install and configure the application, and use OS patch management to install available updates.
- C . Create an instance with the latest available Debian image. Connect to the instance via SSH, and install and configure the application on the instance. Repeat this process
whenever a new Google-managed Debian image becomes available. - D . Create a Docker container with Debian as the base image. Install and configure the application as part of the Docker image creation process. Host the container on Google Kubernetes Engine and restart the container whenever a new update is available.
B
Explanation:
Reference: https://cloud.google.com/compute/docs/os-patch-management
You want to establish a Compute Engine application in a single VPC across two regions. The application must communicate over VPN to an on-premises network .
How should you deploy the VPN?
- A . Use VPC Network Peering between the VPC and the on-premises network.
- B . Expose the VPC to the on-premises network using IAM and VPC Sharing.
- C . Create a global Cloud VPN Gateway with VPN tunnels from each region to the on-premises peer gateway.
- D . Deploy Cloud VPN Gateway in each region. Ensure that each region has at least one VPN tunnel to the on-premises peer gateway.
D
Explanation:
https://cloud.google.com/vpn/docs/how-to/creating-static-vpns
Your company uses the Firewall Insights feature in the Google Network Intelligence Center. You have several firewall rules applied to Compute Engine instances. You need to evaluate the efficiency of the applied firewall ruleset. When you bring up the Firewall Insights page in the Google Cloud Console, you notice that there are no log rows to display .
What should you do to troubleshoot the issue?
- A . Enable Virtual Private Cloud (VPC) flow logging.
- B . Enable Firewall Rules Logging for the firewall rules you want to monitor.
- C . Verify that your user account is assigned the compute.networkAdmin Identity and
Access Management (IAM) role. - D . Install the Google Cloud SDK, and verify that there are no Firewall logs in the command line output.
B
Explanation:
Reference: https://cloud.google.com/network-intelligence-center/docs/firewall-insights/how-to/using-firewall- insights
A development team at your company has created a dockerized HTTPS web application. You need to deploy the application on Google Kubernetes Engine (GKE) and make sure that the application scales automatically.
How should you deploy to GKE?
- A . Use the Horizontal Pod Autoscaler and enable cluster autoscaling. Use an Ingress resource to loadbalance the HTTPS traffic.
- B . Use the Horizontal Pod Autoscaler and enable cluster autoscaling on the Kubernetes cluster. Use a
Service resource of type LoadBalancer to load-balance the HTTPS traffic. - C . Enable autoscaling on the Compute Engine instance group. Use an Ingress resource to load balance the HTTPS traffic.
- D . Enable autoscaling on the Compute Engine instance group. Use a Service resource of type LoadBalancer to load-balance the HTTPS traffic.
B
Explanation:
https://cloud.google.com/kubernetes-engine/docs/tutorials/http-balancer https://cloud.google.com/kubernetes-engine/docs/concepts/network-overview#ext-lb
You need to upload files from your on-premises environment to Cloud Storage. You want the files to be
encrypted on Cloud Storage using customer-supplied encryption keys .
What should you do?
- A . Supply the encryption key in a .boto configuration file. Use gsutil to upload the files.
- B . Supply the encryption key using gcloud config. Use gsutil to upload the files to that bucket.
- C . Use gsutil to upload the files, and use the flag –encryption-key to supply the encryption key.
- D . Use gsutil to create a bucket, and use the flag –encryption-key to supply the encryption key. Use gsutil to upload the files to that bucket.
A
Explanation:
https://cloud.google.com/storage/docs/encryption/customer-supplied-keys#gsutil
You are migrating third-party applications from optimized on-premises virtual machines to Google Cloud. You are unsure about the optimum CPU and memory options. The application have a consistent usage patterns across multiple weeks. You want to optimize resource usage for the lowest cost .
What should you do?
- A . Create a Compute engine instance with CPU and Memory options similar to your application’s current on-premises virtual machine. Install the cloud monitoring agent, and deploy the third party application. Run a load with normal traffic levels on third party application and follow the Rightsizing Recommendations in the Cloud Console
- B . Create an App Engine flexible environment, and deploy the third party application using a Docker file and a custom runtime. Set CPU and memory options similar to your application’s current on-premises virtual machine in the app.yaml file.
- C . Create an instance template with the smallest available machine type, and use an image of the third party application taken from the current on-premises virtual machine. Create a managed instance group that uses average CPU to autoscale the number of instances in the group. Modify the average CPU utilization threshold to optimize the number of instances running.
- D . Create multiple Compute Engine instances with varying CPU and memory options. Install the cloud monitoring agent and deploy the third-party application on each of them. Run a load test with high traffic levels on the application and use the results to determine the optimal settings.
D
Explanation:
Create a Compute engine instance with CPU and Memory options similar to your application’s current on-premises virtual machine. Install the cloud monitoring agent, and deploy the third party application. Run a load with normal traffic levels on third party application and follow the Rightsizing Recommendations in the Cloud Console https://cloud.google.com/migrate/compute-engine/docs/4.9/concepts/planning-a-migration/cloud-instance-rightsizing?hl=en
Your company is designing its data lake on Google Cloud and wants to develop different ingestion pipelines to collect unstructured data from different sources. After the data is stored in Google Cloud, it will be processed in several data pipelines to build a recommendation engine for end users on the website. The structure of the data retrieved from the source systems can change at any time. The data must be stored exactly as it was retrieved for reprocessing purposes in case the data structure is incompatible with the current processing pipelines. You need to design an architecture to support the use case after you retrieve the data .
What should you do?
- A . Send the data through the processing pipeline, and then store the processed data in a BigQuery table for reprocessing.
- B . Store the data in a BigQuery table. Design the processing pipelines to retrieve the data from the table.
- C . Send the data through the processing pipeline, and then store the processed data in a Cloud Storage bucket for reprocessing.
- D . Store the data in a Cloud Storage bucket. Design the processing pipelines to retrieve the data from the bucket
You have an application that makes HTTP requests to Cloud Storage. Occasionally the requests fail with HTTP status codes of 5xx and 429.
How should you handle these types of errors?
- A . Use gRPC instead of HTTP for better performance.
- B . Implement retry logic using a truncated exponential backoff strategy.
- C . Make sure the Cloud Storage bucket is multi-regional for geo-redundancy.
- D . Monitor https://status.cloud.google.com/feed.atom and only make requests if Cloud
Storage is not reporting
an incident.
B
Explanation:
Reference https://cloud.google.com/storage/docs/json_api/v1/status-codes
You have an outage in your Compute Engine managed instance group: all instance keep restarting after 5 seconds. You have a health check configured, but autoscaling is disabled. Your colleague, who is a Linux expert, offered to look into the issue. You need to make sure that he can access the VMs .
What should you do?
- A . Grant your colleague the IAM role of project Viewer
- B . Perform a rolling restart on the instance group
- C . Disable the health check for the instance group. Add his SSH key to the project-wide SSH keys
- D . Disable autoscaling for the instance group. Add his SSH key to the project-wide SSH Keys
C
Explanation:
https://cloud.google.com/compute/docs/instance-groups/autohealing-instances-in-migs Health checks used for autohealing should be conservative so they don’t preemptively delete and recreate your instances. When an autohealer health check is too aggressive, the autohealer might mistake busy instances for failed instances and unnecessarily restart them, reducing availability
Your operations team has asked you to help diagnose a performance issue in a production application that runs on Compute Engine. The application is dropping requests that reach it
when under heavy load. The process list for affected instances shows a single application process that is consuming all available CPU, and autoscaling has reached the upper limit of instances. There is no abnormal load on any other related systems, including the database. You want to allow production traffic to be served again as quickly as possible .
Which action should you recommend?
- A . Change the autoscaling metric to agent.googleapis.com/memory/percent_used.
- B . Restart the affected instances on a staggered schedule.
- C . SSH to each instance and restart the application process.
- D . Increase the maximum number of instances in the autoscaling group.
D
Explanation:
Reference: https://cloud.google.com/blog/products/sap-google-cloud/best-practices-for-sap-app-server- autoscaling-on-google-cloud
You are implementing a single Cloud SQL MySQL second-generation database that contains business-critical transaction data. You want to ensure that the minimum amount of data is lost in case of catastrophic failure .
Which two features should you implement? (Choose two.)
- A . Sharding
- B . Read replicas
- C . Binary logging
- D . Automated backups
- E . Semisynchronous replication
C,D
Explanation:
Backups help you restore lost data to your Cloud SQL instance. Additionally, if an instance is having a problem, you can restore it to a previous state by using the backup to overwrite it. Enable automated backups for any instance that contains necessary data. Backups protect your data from loss or damage.
Enabling automated backups, along with binary logging, is also required for some operations, such as clone and replica creation.
Reference: https://cloud.google.com/sql/docs/mysql/backup-recovery/backups
The database administration team has asked you to help them improve the performance of their new database server running on Google Compute Engine. The database is for importing and normalizing their performance statistics and is built with MySQL running on Debian Linux. They have an n1-standard-8 virtual machine with 80 GB of SSD persistent disk .
What should they change to get better performance from this system?
- A . Increase the virtual machine’s memory to 64 GB.
- B . Create a new virtual machine running PostgreSQL.
- C . Dynamically resize the SSD persistent disk to 500 GB.
- D . Migrate their performance metrics warehouse to BigQuery.
- E . Modify all of their batch jobs to use bulk inserts into the database.
Your BigQuery project has several users. For audit purposes, you need to see how many queries each user ran in the last month.
- A . Connect Google Data Studio to BigQuery. Create a dimension for the users and a metric for the amount of queries per user.
- B . In the BigQuery interface, execute a query on the JOBS table to get the required information.
- C . Use ‘bq show’ to list all jobs. Per job, use ‘bq Is’ to list job information and get the required information.
- D . Use Cloud Audit Logging to view Cloud Audit Logs, and create a filter on the query
operation to get the required information.
D
Explanation:
https://cloud.google.com/bigquery/docs/managing-jobs
A recent audit that a new network was created in Your GCP project. In this network, a GCE instance has an SSH port open the world. You want to discover this network’s origin .
What should you do?
- A . Search for Create VM entry in the Stackdriver alerting console.
- B . Navigate to the Activity page in the Home section. Set category to Data Access and search for Create VM entry.
- C . In the logging section of the console, specify GCE Network as the logging section.
Search for the Create Insert entry. - D . Connect to the GCE instance using project SSH Keys. Identify previous logins in system logs, and match these with the project owners list.