Databricks Databricks Certified Data Engineer Professional Databricks Certified Data Engineer Professional Exam Online Training
Databricks Databricks Certified Data Engineer Professional Online Training
The questions for Databricks Certified Data Engineer Professional were last updated at Feb 22,2026.
- Exam Code: Databricks Certified Data Engineer Professional
- Exam Name: Databricks Certified Data Engineer Professional Exam
- Certification Provider: Databricks
- Latest update: Feb 22,2026
Why does AUTO LOADER require schema location?
- A . Schema location is used to store user provided schema
- B . Schema location is used to identify the schema of target table
- C . AUTO LOADER does not require schema location, because its supports Schema evolution
- D . Schema location is used to store schema inferred by AUTO LOADER
- E . Schema location is used to identify the schema of target table and source table
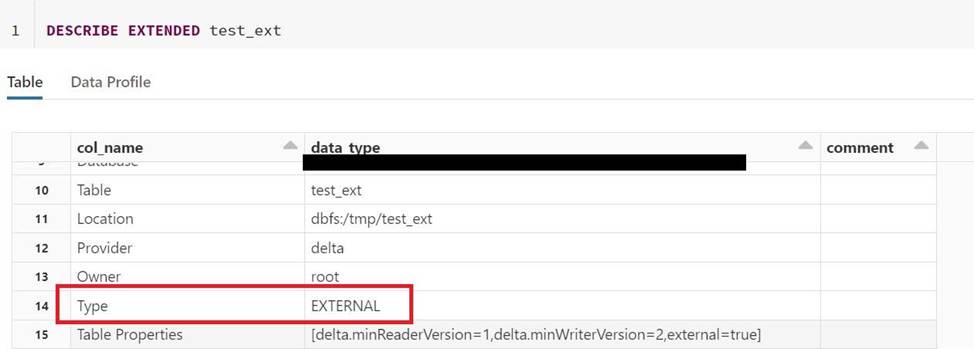
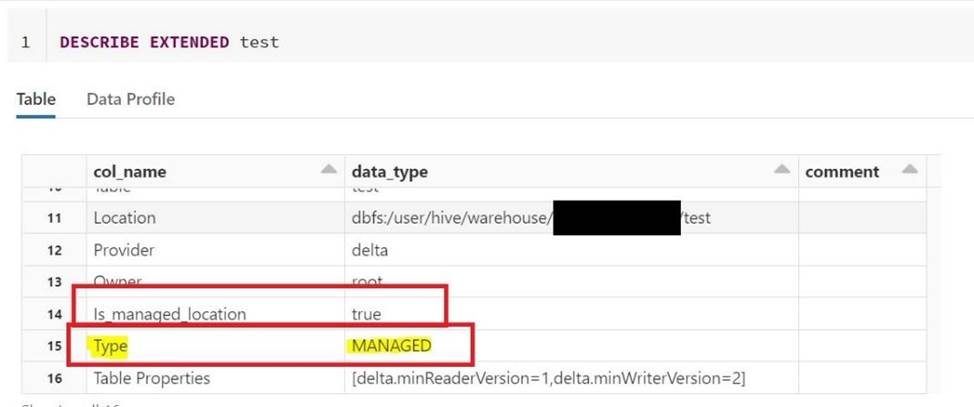
How to determine if a table is a managed table vs external table?
- A . Run IS_MANAGED(‘table_name’) function
- B . All external tables are stored in data lake, managed tables are stored in DELTA lake
- C . All managed tables are stored in unity catalog
- D . Run SQL command DESCRIBE EXTENDED table_name and check type
- E . Run SQL command SHOW TABLES to see the type of the table
In order to use Unity catalog features, which of the following steps needs to be taken on man-aged/external tables in the Databricks workspace?
- A . Enable unity catalog feature in workspace settings
- B . Migrate/upgrade objects in workspace managed/external tables/view to unity catalog
- C . Upgrade to DBR version 15.0
- D . Copy data from workspace to unity catalog
- E . Upgrade workspace to Unity catalog
Data science team members are using a single cluster to perform data analysis, although cluster size was chosen to handle multiple users and auto-scaling was enabled, the team realized queries are still running slow, what would be the suggested fix for this?
- A . Setup multiple clusters so each team member has their own cluster
- B . Disable the auto-scaling feature
- C . Use High concurrency mode instead of the standard mode
- D . Increase the size of the driver node
Kevin is the owner of the schema sales, Steve wanted to create new table in sales schema called regional_sales so Kevin grants the create table permissions to Steve. Steve creates the new table called regional_sales in sales schema, who is the owner of the table regional_sales
- A . Kevin is the owner of sales schema, all the tables in the schema will be owned by Kevin
- B . Steve is the owner of the table
- C . By default ownership is assigned DBO
- D . By default ownership is assigned to DEFAULT_OWNER
- E . Kevin and Smith both are owners of table
You are currently working with the second team and both teams are looking to modify the same notebook, you noticed that the second member is copying the notebooks to the personal folder to edit and replace the collaboration notebook, which notebook feature do you recommend to make the process easier to collaborate.
- A . Databricks notebooks should be copied to a local machine and setup source control locally to version the notebooks
- B . Databricks notebooks support automatic change tracking and versioning
- C . Databricks Notebooks support real-time coauthoring on a single notebook
- D . Databricks notebooks can be exported into dbc archive files and stored in data lake
- E . Databricks notebook can be exported as HTML and imported at a later time
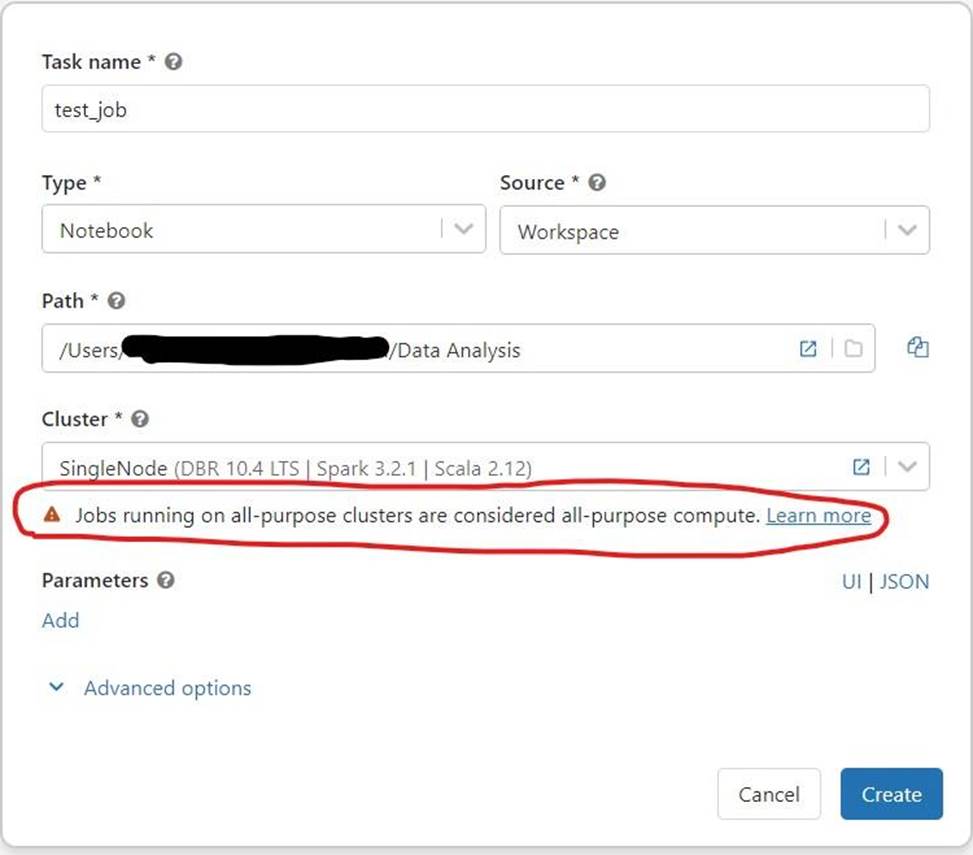
Your colleague was walking you through how a job was setup, but you noticed a warning message that said, “Jobs running on all-purpose cluster are considered all purpose compute", the colleague was not sure why he was getting the warning message, how do you best explain this warning mes-sage?
- A . All-purpose clusters cannot be used for Job clusters, due to performance issues.
- B . All-purpose clusters take longer to start the cluster vs a job cluster
- C . All-purpose clusters are less expensive than the job clusters
- D . All-purpose clusters are more expensive than the job clusters
- E . All-purpose cluster provide interactive messages that can not be viewed in a job
Which of the following functions can be used to convert JSON string to Struct data type?
- A . TO_STRUCT (json value)
- B . FROM_JSON (json value)
- C . FROM_JSON (json value, schema of json)
- D . CONVERT (json value, schema of json)
- E . CAST (json value as STRUCT)
Which of the following functions can be used to convert JSON string to Struct data type?
- A . TO_STRUCT (json value)
- B . FROM_JSON (json value)
- C . FROM_JSON (json value, schema of json)
- D . CONVERT (json value, schema of json)
- E . CAST (json value as STRUCT)
You are asked to write a python function that can read data from a delta table and return the Data-Frame, which of the following is correct?
- A . Python function cannot return a DataFrame
- B . Write SQL UDF to return a DataFrame
- C . Write SQL UDF that can return tabular data
- D . Python function will result in out of memory error due to data volume
- E . Python function can return a DataFrame
Latest Databricks Certified Data Engineer Professional Dumps Valid Version with 278 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
