Databricks Databricks Certified Data Engineer Professional Databricks Certified Data Engineer Professional Exam Online Training
Databricks Databricks Certified Data Engineer Professional Online Training
The questions for Databricks Certified Data Engineer Professional were last updated at Feb 22,2026.
- Exam Code: Databricks Certified Data Engineer Professional
- Exam Name: Databricks Certified Data Engineer Professional Exam
- Certification Provider: Databricks
- Latest update: Feb 22,2026
You are currently asked to work on building a data pipeline, you have noticed that you are currently working on a very large scale ETL many data dependencies, which of the following tools can be used to address this problem?
- A . AUTO LOADER
- B . JOBS and TASKS
- C . SQL Endpoints
- D . DELTA LIVE TABLES
- E . STRUCTURED STREAMING with MULTI HOP
You are currently asked to work on building a data pipeline, you have noticed that you are currently working on a very large scale ETL many data dependencies, which of the following tools can be used to address this problem?
- A . AUTO LOADER
- B . JOBS and TASKS
- C . SQL Endpoints
- D . DELTA LIVE TABLES
- E . STRUCTURED STREAMING with MULTI HOP
You are currently asked to work on building a data pipeline, you have noticed that you are currently working on a very large scale ETL many data dependencies, which of the following tools can be used to address this problem?
- A . AUTO LOADER
- B . JOBS and TASKS
- C . SQL Endpoints
- D . DELTA LIVE TABLES
- E . STRUCTURED STREAMING with MULTI HOP
You are currently asked to work on building a data pipeline, you have noticed that you are currently working on a very large scale ETL many data dependencies, which of the following tools can be used to address this problem?
- A . AUTO LOADER
- B . JOBS and TASKS
- C . SQL Endpoints
- D . DELTA LIVE TABLES
- E . STRUCTURED STREAMING with MULTI HOP
You are currently asked to work on building a data pipeline, you have noticed that you are currently working on a very large scale ETL many data dependencies, which of the following tools can be used to address this problem?
- A . AUTO LOADER
- B . JOBS and TASKS
- C . SQL Endpoints
- D . DELTA LIVE TABLES
- E . STRUCTURED STREAMING with MULTI HOP
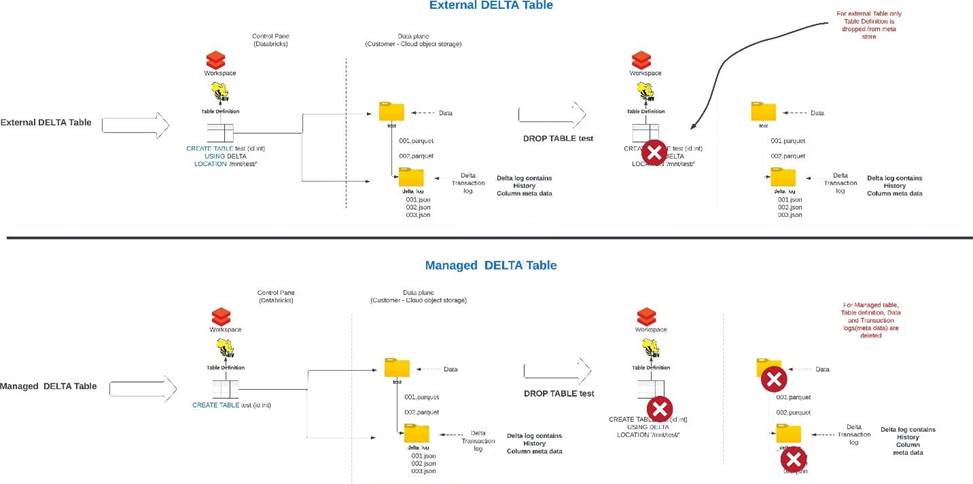
When you drop a managed table using SQL syntax DROP TABLE table_name how does it impact metadata, history, and data stored in the table?
- A . Drops table from meta store, drops metadata, history, and data in storage.
- B . Drops table from meta store and data from storage but keeps metadata and history in storage
- C . Drops table from meta store, meta data and history but keeps the data in storage
- D . Drops table but keeps meta data, history and data in storage
- E . Drops table and history but keeps meta data and data in storage
Which of the following approaches can the data engineer use to obtain a version-controllable con-figuration of the Job’s schedule and configuration?
- A . They can link the Job to notebooks that are a part of a Databricks Repo.
- B . They can submit the Job once on a Job cluster.
- C . They can download the JSON equivalent of the job from the Job’s page.
- D . They can submit the Job once on an all-purpose cluster.
- E . They can download the XML description of the Job from the Job’s page
What is the underlying technology that makes the Auto Loader work?
- A . Loader
- B . Delta Live Tables
- C . Structured Streaming
- D . DataFrames
- E . Live DataFames
You are currently looking at a table that contains data from an e-commerce platform, each row contains a list of items(Item number) that were present in the cart, when the customer makes a change to the cart the entire information is saved as a separate list and appended to an existing list for the duration of the customer session, to identify all the items customer bought you have to make a unique list of items, you were asked to create a unique item’s list that was added to the cart by the user, fill in the blanks of below query by choosing the appropriate higher-order function?
Note: See below sample data and expected output.
Schema: cartId INT, items Array<INT>
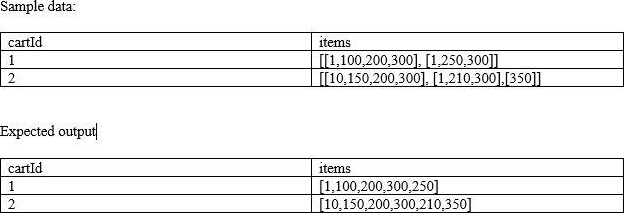
Fill in the blanks:
Fill in the blanks:
SELECT cartId, _(_(items)) FROM carts
- A . ARRAY_UNION, ARRAY_DISCINT
- B . ARRAY_DISTINCT, ARRAY_UNION
- C . ARRAY_DISTINCT, FLATTEN
- D . FLATTEN, ARRAY_DISTINCT
- E . ARRAY_DISTINCT, ARRAY_FLATTEN

When building a DLT s pipeline you have two options to create a live tables, what is the main difference between CREATE STREAMING LIVE TABLE vs CREATE LIVE TABLE?
- A . CREATE STREAMING LIVE table is used in MULTI HOP Architecture
- B . CREATE LIVE TABLE is used when working with Streaming data sources and Incremental data
- C . CREATE STREAMING LIVE TABLE is used when working with Streaming data sources and Incremental data
- D . There is no difference both are the same, CREATE STRAMING LIVE will be deprecated soon
- E . CREATE LIVE TABLE is used in DELTA LIVE TABLES, CREATE STREAMING LIVE can only used in Structured Streaming applications
Latest Databricks Certified Data Engineer Professional Dumps Valid Version with 278 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
