Databricks Databricks Certified Data Engineer Professional Databricks Certified Data Engineer Professional Exam Online Training
Databricks Databricks Certified Data Engineer Professional Online Training
The questions for Databricks Certified Data Engineer Professional were last updated at Feb 22,2026.
- Exam Code: Databricks Certified Data Engineer Professional
- Exam Name: Databricks Certified Data Engineer Professional Exam
- Certification Provider: Databricks
- Latest update: Feb 22,2026
Data engineering team has provided 10 queries and asked Data Analyst team to build a dashboard and refresh the data every day at 8 AM, identify the best approach to set up data refresh for this dashaboard?
- A . Each query requires a separate task and setup 10 tasks under a single job to run at 8 AM to refresh the dashboard
- B . The entire dashboard with 10 queries can be refreshed at once, single schedule needs to be set up to refresh at 8 AM.
- C . Setup JOB with linear dependency to all load all 10 queries into a table so the dashboard can be refreshed at once.
- D . A dashboard can only refresh one query at a time, 10 schedules to set up the refresh.
- E . Use Incremental refresh to run at 8 AM every day.
What is the best way to query external csv files located on DBFS Storage to inspect the data using SQL?
- A . SELECT * FROM ‘dbfs:/location/csv_files/’ FORMAT = ‘CSV’
- B . SELECT CSV. * from ‘dbfs:/location/csv_files/’
- C . SELECT * FROM CSV. ‘dbfs:/location/csv_files/’
- D . You can not query external files directly, us COPY INTO to load the data into a table first
- E . SELECT * FROM ‘dbfs:/location/csv_files/’ USING CSV
You have written a notebook to generate a summary data set for reporting, Notebook was scheduled using the job cluster, but you realized it takes 8 minutes to start the cluster, what feature can be used to start the cluster in a timely fashion so your job can run immediatley?
- A . Setup an additional job to run ahead of the actual job so the cluster is running second job starts
- B . Use the Databricks cluster pools feature to reduce the startup time
- C . Use Databricks Premium edition instead of Databricks standard edition
- D . Pin the cluster in the cluster UI page so it is always available to the jobs
- E . Disable auto termination so the cluster is always running

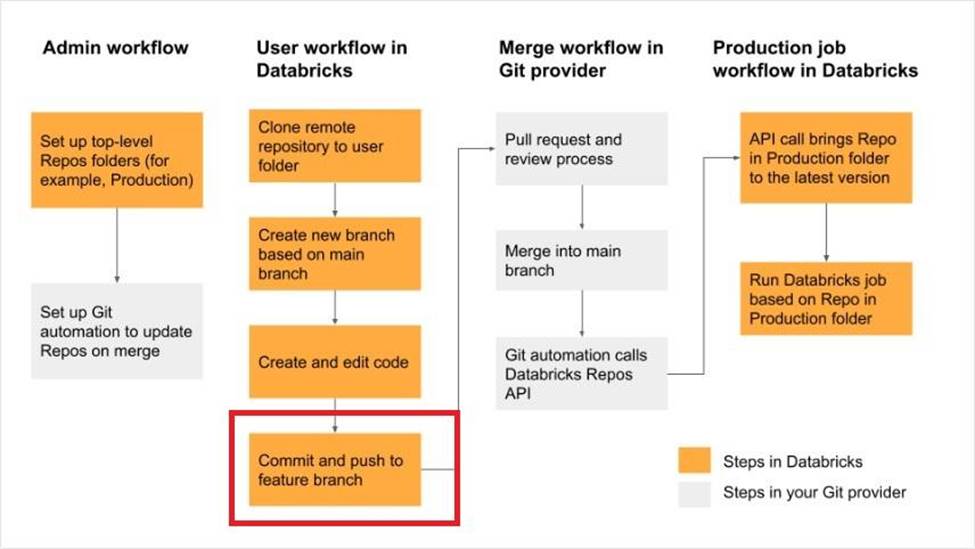
Which of the following developer operations in CI/CD flow can be implemented in Databricks Re-pos?
- A . Delete branch
- B . Trigger Databricks CICD pipeline
- C . Commit and push code
- D . Create a pull request
- E . Approve the pull request
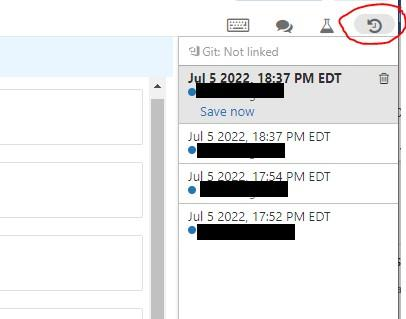
You noticed that colleague is manually copying the notebook with _bkp to store the previous versions, which of the following feature would you recommend instead.
- A . Databricks notebooks support change tracking and versioning
- B . Databricks notebooks should be copied to a local machine and setup source control locally to version the notebooks
- C . Databricks notebooks can be exported into dbc archive files and stored in data lake
- D . Databricks notebook can be exported as HTML and imported at a later time
You noticed that colleague is manually copying the notebook with _bkp to store the previous versions, which of the following feature would you recommend instead.
- A . Databricks notebooks support change tracking and versioning
- B . Databricks notebooks should be copied to a local machine and setup source control locally to version the notebooks
- C . Databricks notebooks can be exported into dbc archive files and stored in data lake
- D . Databricks notebook can be exported as HTML and imported at a later time
You noticed that colleague is manually copying the notebook with _bkp to store the previous versions, which of the following feature would you recommend instead.
- A . Databricks notebooks support change tracking and versioning
- B . Databricks notebooks should be copied to a local machine and setup source control locally to version the notebooks
- C . Databricks notebooks can be exported into dbc archive files and stored in data lake
- D . Databricks notebook can be exported as HTML and imported at a later time
You noticed that colleague is manually copying the notebook with _bkp to store the previous versions, which of the following feature would you recommend instead.
- A . Databricks notebooks support change tracking and versioning
- B . Databricks notebooks should be copied to a local machine and setup source control locally to version the notebooks
- C . Databricks notebooks can be exported into dbc archive files and stored in data lake
- D . Databricks notebook can be exported as HTML and imported at a later time
You noticed that colleague is manually copying the notebook with _bkp to store the previous versions, which of the following feature would you recommend instead.
- A . Databricks notebooks support change tracking and versioning
- B . Databricks notebooks should be copied to a local machine and setup source control locally to version the notebooks
- C . Databricks notebooks can be exported into dbc archive files and stored in data lake
- D . Databricks notebook can be exported as HTML and imported at a later time
You noticed that colleague is manually copying the notebook with _bkp to store the previous versions, which of the following feature would you recommend instead.
- A . Databricks notebooks support change tracking and versioning
- B . Databricks notebooks should be copied to a local machine and setup source control locally to version the notebooks
- C . Databricks notebooks can be exported into dbc archive files and stored in data lake
- D . Databricks notebook can be exported as HTML and imported at a later time
Latest Databricks Certified Data Engineer Professional Dumps Valid Version with 278 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
