Databricks Databricks Certified Data Engineer Professional Databricks Certified Data Engineer Professional Exam Online Training
Databricks Databricks Certified Data Engineer Professional Online Training
The questions for Databricks Certified Data Engineer Professional were last updated at Feb 24,2026.
- Exam Code: Databricks Certified Data Engineer Professional
- Exam Name: Databricks Certified Data Engineer Professional Exam
- Certification Provider: Databricks
- Latest update: Feb 24,2026
table(table_name))
- A . format, checkpointlocation, schemalocation, overwrite
- B . cloudfiles.format, checkpointlocation, cloudfiles.schemalocation, overwrite
- C . cloudfiles.format, cloudfiles.schemalocation, checkpointlocation, mergeSchema
- D . cloudfiles.format, cloudfiles.schemalocation, checkpointlocation, append
- E . cloudfiles.format, cloudfiles.schemalocation, checkpointlocation, overwrite
Which of the following scenarios is the best fit for AUTO LOADER?
- A . Efficiently process new data incrementally from cloud object storage
- B . Efficiently move data incrementally from one delta table to another delta table
- C . Incrementally process new data from streaming data sources like Kafka into delta lake
- D . Incrementally process new data from relational databases like MySQL
- E . Efficiently copy data from one data lake location to another data lake location
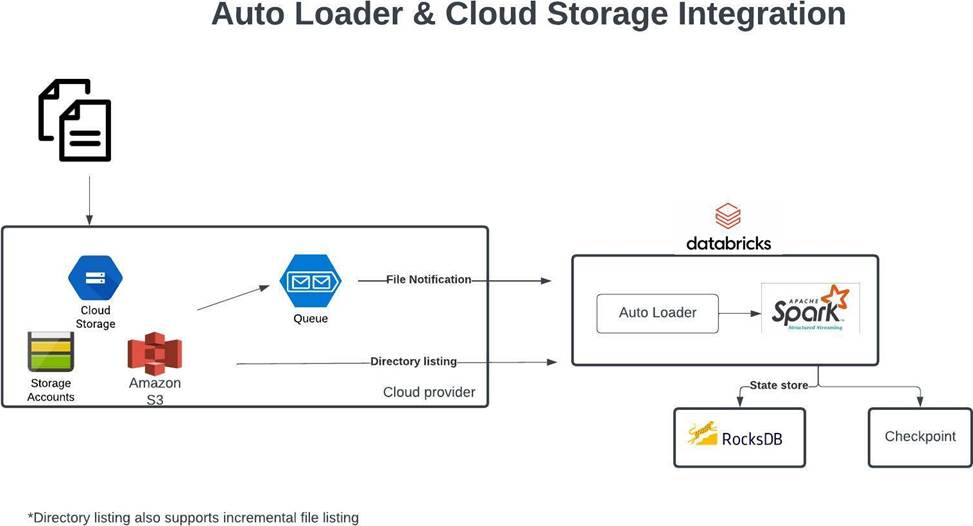
Which of the following scenarios is the best fit for AUTO LOADER?
- A . Efficiently process new data incrementally from cloud object storage
- B . Efficiently move data incrementally from one delta table to another delta table
- C . Incrementally process new data from streaming data sources like Kafka into delta lake
- D . Incrementally process new data from relational databases like MySQL
- E . Efficiently copy data from one data lake location to another data lake location
Which of the following scenarios is the best fit for AUTO LOADER?
- A . Efficiently process new data incrementally from cloud object storage
- B . Efficiently move data incrementally from one delta table to another delta table
- C . Incrementally process new data from streaming data sources like Kafka into delta lake
- D . Incrementally process new data from relational databases like MySQL
- E . Efficiently copy data from one data lake location to another data lake location
The team has decided to take advantage of table properties to identify a business owner for each table, which of the following table DDL syntax allows you to populate a table property identifying the business owner of a table
CREATE TABLE inventory (id INT, units FLOAT)
- A . SET TBLPROPERTIES business_owner = ‘supply chain’
CREATE TABLE inventory (id INT, units FLOAT) - B . TBLPROPERTIES (business_owner = ‘supply chain’)
- C . CREATE TABLE inventory (id INT, units FLOAT)
SET (business_owner = ‘supply chain’) - D . CREATE TABLE inventory (id INT, units FLOAT)
SET PROPERTY (business_owner = ‘supply chain’) - E . CREATE TABLE inventory (id INT, units FLOAT)
SET TAG (business_owner = ‘supply chain’)
While investigating a data issue, you wanted to review yesterday’s version of the table using below command, while querying the previous version of the table using time travel you realized that you are no longer able to view the historical data in the table and you could see it the table was updated yesterday based on the table history(DESCRIBE HISTORY table_name) command what could be the reason why you can not access this data?
SELECT * FROM table_name TIMESTAMP AS OF date_sub(current_date(), 1)
- A . You currently do not have access to view historical data
- B . By default, historical data is cleaned every 180 days in DELTA
- C . A command VACUUM table_name RETAIN 0 was ran on the table
- D . Time travel is disabled
- E . Time travel must be enabled before you query previous data
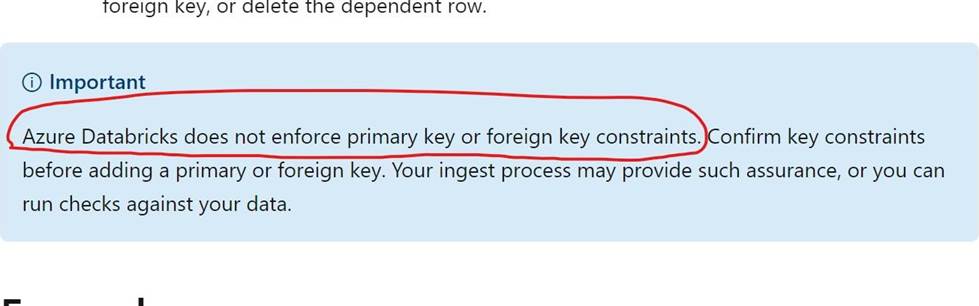
Which of the following table constraints that can be enforced on Delta lake tables are supported?
- A . Primary key, foreign key, Not Null, Check Constraints
- B . Primary key, Not Null, Check Constraints
- C . Default, Not Null, Check Constraints
- D . Not Null, Check Constraints
- E . Unique, Not Null, Check Constraints
Which of the following commands results in the successful creation of a view on top of the delta stream (stream on delta table)?
- A . Spark.read.format("delta").table("sales").createOrReplaceTempView("streaming_vw")
- B . Spark.readStream.format("delta").table("sales").createOrReplaceTempView("streaming_vw ")
- C . Spark.read.format("delta").table("sales").mode("stream").createOrReplaceTempView("strea ming_vw")
- D . Spark.read.format("delta").table("sales").trigger("stream").createOrReplaceTempView("stre aming_vw")
- E . Spark.read.format("delta").stream("sales").createOrReplaceTempView("streaming_vw")
- F . You can not create a view on streaming data source.
What is the purpose of a gold layer in Multi-hop architecture?
- A . Optimizes ETL throughput and analytic query performance
- B . Eliminate duplicate records
- C . Preserves grain of original data, without any aggregations
- D . Data quality checks and schema enforcement
- E . Powers ML applications, reporting, dashboards and adhoc reports.
What is the purpose of a gold layer in Multi-hop architecture?
- A . Optimizes ETL throughput and analytic query performance
- B . Eliminate duplicate records
- C . Preserves grain of original data, without any aggregations
- D . Data quality checks and schema enforcement
- E . Powers ML applications, reporting, dashboards and adhoc reports.
Latest Databricks Certified Data Engineer Professional Dumps Valid Version with 278 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
